10 Cluster管理
Envoy支持同时配置任意数量的上游集群,并基于Cluster Manager管理它们;
Cluster Manager负责为集群管理上游主机的健康状态、负载均衡机制、连接类型及适用协议等;
生成集群配置的方式由静态或动态(CDS)两种;
集群在服务器启动或者通过 CDS 进行初始化时需要一个预热的过程,这意味 着集群存在下列状况。
- 初始服务发现加载 (例如DNS 解析、EDS 更新等)完成之前不可用
- 配置了主动健康状态检查机制时,Envoy会主动发送健康状态检测请求报文至发现的每个上游主机;于是,初始的主动健康检查成功完成之前不可用
于是,新增集群初始化完成之前对Envoy的其它组件来说不可见;而对于需要 更新的集群,在其预热完成后通过与旧集群的原子交换来确保不会发生流量中 断类的错误;
集群管理器配置上游集群时需要知道如何解析集群成员,相应的解析机 制即为服务发现;
集群中的每个成员由endpoint进行标识,它可由用户静态配置,也可通过EDS 或DNS服务动态发现;
Static:静态配置,即显式指定每个上游主机的已解析名称(IP地址/端口或unix域套按字文 件);
Strict DNS:严格DNS,Envoy将持续和异步地解析指定的DNS目标,并将DNS结果中的返 回的每个IP地址视为上游集群中可用成员;
Logical DNS:逻辑DNS,集群仅使用在需要启动新连接时返回的第一个IP地址,而非严格 获取DNS查询的结果并假设它们构成整个上游集群;适用于必须通过DNS访问的大规模 Web服务集群;
Original destination:当传入连接通过iptables的REDIRECT或TPROXY target或使用代理协 议重定向到Envoy时,可以使用原始目标集群;
Endpoint discovery service (EDS):EDS是一种基于GRPC或REST-JSON API的xDS管理服务 器获取集群成员的服务发现方式;
Custom cluster:Envoy还支持在集群配置上的cluster_type字段中指定使用自定义集群发现机 制;
Envoy的服务发现并未采用完全一致的机制,而是假设主机以最终一致的方式加入或离开网格,它结合主动健康状态检查机制来判定集群的健康状态;健康与否的决策机制以完全分布式的方式进行,因此可以很好地应对网络分区。
为集群启用主机健康状态检查机制后,Envoy基于如下方式判定是否路由请求 到一个主机:
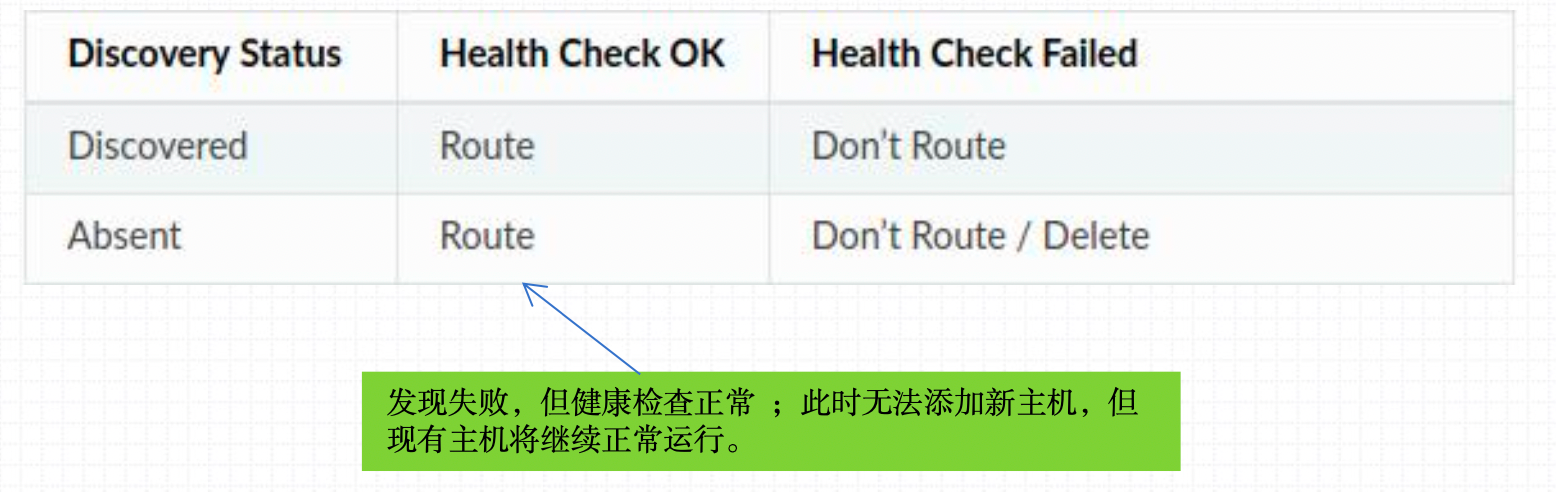
Envoy提供了一系列开箱即用的故障处理机制:
- 超时(timeout)
- 有限次数的重试,并支持可变的重试延迟
- 主动健康检查与异常探测
- 连接池
- 断路器
所有这些特性,都可以在运行时动态配置; 结合流量管理机制,用户可为每个服务/版本定制所需的故障恢复机制;
健康状态检测用于确保代理服务器不会将下游客户端的请求代理至工作异常的上游主机;
Envoy支持两种类型的健康状态检测,二者均基于集群进行定义:
主动检测(Active Health Checking):Envoy周期性地发送探测报文至上游主机,并根据 其响应判断其健康状态;Envoy目前支持三种类型的主动检测:
- HTTP:向上游主机发送HTTP请求报文
- L3/L4:向上游主机发送L3/L4请求报文,基于响应的结果判定其健康状态,或仅通过连接状态进行判定;
- Redis:向上游的redis服务器发送Redis PING ;
被动检测(Passive Health Checking):Envoy通过异常检测(Outlier Detection)机制进行 被动模式的健康状态检测; 目前,仅http router、tcp proxy和redis proxy三个过滤器支持异常值检测;Envoy支持以下类型的异常检测:
- 连续5XX(consecutive_5xx):意指所有类型的错误,非http router过滤器生成的错误也会在内部映射为5xx错误代码;
- 连续网关故障(consecutive-gateway_failure):连续5XX的子集,单纯用于http的502、503或504错误,即网关故障;
- 连续的本地原因故障(consecutive_local_origin_failure):Envoy无法连接到上游主机或与上游主机的通信被反复中断;
- 成功率(success_rate):主机的聚合成功率数据阈值;
集群的主机健康状态检测机制需要显式定义,否则,发现的所有上游主机即被视 为可用;定义语法
clusters:
- name: ...
...
load_assignment:
endpoints:
- lb_endpoints:
- endpoint:
health_check_config:
port_value: ... # 自定义健康状态检测时使用的端口; 如果未定义,则向endpoint的端口发送检测
...
...
health_checks:
- timeout: ... # 超时时长
interval: ... # 时间间隔
initial_jitter: ... # 初始检测时间点散开量,以毫秒为单位;
interval_jitter: ... # 间隔检测时间点散开量,以毫秒为单位;
unhealthy_threshold: ... # 将主机标记为不健康状态的检测阈值,即至少多少次不健康的检测后才将其标记为不可用;
healthy_threshold: ... # 将主机标记为健康状态的检测阈值,但初始检测成功1次即视主机为健康;
http_health_check: {...} # HTTP类型的检测;包括此种类型在内的以下四种检测类型必须设置一种;
tcp_health_check: {...} # TCP类型的检测;
grpc_health_check: {...} # GRPC专用的检测;
custom_health_check: {...} # 自定义检测;
reuse_connection: ... # 布尔型值,是否在多次检测之间重用连接,默认值为true;
no_traffic_interval: ... # 定义未曾调度任何流量至集群时其端点健康检测时间间隔,一旦其接收流量即转为正常的时间间隔;
unhealthy_interval: ... # 标记为“unhealthy”状态的端点的健康检测时间间隔,一旦重新标记为“healthy”即转为正常时间间隔;
unhealthy_edge_interval: ... # 端点刚被标记为“unhealthy”状态时的健康检测时间间隔,随后即转为同unhealthy_interval的定义;
healthy_edge_interval: ... # 端点刚被标记为“healthy”状态时的健康检测时间间隔,随后即转为同interval的定义;
clusters:
- name: local_service
connect_timeout: 0.25s
lb_policy: ROUND_ROBIN
type: EDS
eds_cluster_config:
eds_config:
api_config_source:
api_type: GRPC
grpc_services:
- envoy_grpc:
cluster_name: xds_cluster
health_checks: #定义tcp检测
- timeout: 5s
interval: 10s
unhealthy_threshold: 2
healthy_threshold: 2
tcp_health_check: {} #对于tcp检测,为空载或非空载
空负载的tcp检测意味着仅通过连接状态判定其检测结果
非空负载的tcp检测可以使用send和receive来分别指定请求负荷及于响应报文中期望模糊匹配的结果 ;
{
"send": "{...}",
"receive": []
}
http类型的检测可以自定义使用的path 、host和期望的响应码等,并能够在必 要时修改(添加/删除)请求报文的标头
具体配置语法如下:
health_checks: []
- ...
http_health_check:
"host": "..." # 检测时使用的主机标头,默认为空,此时使用集群名称;
"path": "..." # 检测时使用的路径,例如/healthz;必选参数;
"service_name": "..." # 用于验证检测目标集群的服务名称参数,可选;
"request_headers_to_add": [] # 向检测报文添加的自定义标头列表;
"request_headers_to_remove": [] # 从检测报文中移除的标头列表;
"use_http2": "..." # 是否使用http2协议;
"expected_statuses": [] # 期望的响应码列表;
示例:
clusters:
- name: local_service
connect_timeout: 0.25s
lb_policy: ROUND_ROBIN
type: EDS
eds_cluster_config:
eds_config:
api_config_source:
api_type: GRPC
grpc_services:
- envoy_grpc:
cluster_name: xds_cluster
health_checks:
- timeout: 5s
interval: 10s
unhealthy_threshold: 2
healthy_threshold: 2
http_health_check:
host: ... # 默认为空值,并自动使用集群为其值;
path: ... # 检测针对的路径,例如/healthz;
expected_statuses: ... # 期望的响应码,默认为200;
root@istio:~/ServiceMesh_in_Practise/cluster-manager/health-check# ls
README.md docker-compose.yaml front-envoy-tcp.yaml front-envoy.yaml
异常值探测,也称之为“离群值检测”。
异常主机驱逐机制:确定主机异常 -> 若尚未驱逐主机,且已驱逐的数量低于允许的阈值,则已经驱逐主机 -> 主机处于驱逐状态一定时长 -> 超出时长后自动恢复服务
异常探测通过outlier_dection字段定义在集群上下文中:
clusters:
- name: ...
...
outlier_detection:
consecutive_5xx: ... # 因连续5xx错误而弹出主机之前允许出现的连续5xx响应或本地原始错误的数量,默认为5;
interval: ... # 弹射分析扫描之间的时间间隔,默认为10000ms或10s;
base_ejection_time: ... # 主机被弹出的基准时长,实际时长等于基准时长乘以主机已经弹出的次数;默认为30000ms或30s;
max_ejection_percent: ... # 因异常探测而允许弹出的上游集群中的主机数量百分比,默认为10%;不过,无论如何,至少要弹出一个主机;
enforcing_consecutive_5xx: ... # 基于连续的5xx检测到主机异常时主机将被弹出的几率,可用于禁止弹出或缓慢弹出;默认为100;
enforcing_success_rate: ... # 基于成功率检测到主机异常时主机将被弹出的几率,可用于禁止弹出或缓慢弹出;默认为100;
success_rate_minimum_hosts: ... # 对集群启动成功率异常检测的最少主机数,默认值为5;
success_rate_request_volume: ... # 在检测的一次时间间隔中必须收集的总请求的最小值,默认值为100;
success_rate_stdev_factor: ... # 用确定成功率异常值弹出的弹射阈值的因子;弹射阈值=均值-(因子*平均成功率标准差);不过,此处设置的值 需要除以1000以得到因子,例如,需要使用1.3为因子时,需要将该参数值设定为1300;
consecutive_gateway_failure: ... # 因连续网关故障而弹出主机的最少连续故障数,默认为5;
enforcing_consecutive_gateway_failure: ... # 基于连续网关故障检测到异常状态时而弹出主机的几率的百分比,默认为0;
split_external_local_origin_errors: ... # 是否区分本地原因而导致的故障和外部故障,默认为false;此项设置为true时,以下三项方能生效;
consecutive_local_origin_failure: ... # 因本地原因的故障而弹出主机的最少故障次数,默认为5;
enforcing_consecutive_local_origin_failure: ... # 基于连续的本地故障检测到异常状态而弹出主机的几率百分比,默认为100;
enforcing_local_origin_success_rate: ... # 基于本地故障检测的成功率统计检测到异常状态而弹出主机的几率,默认为100;
同主动健康检查一样,异常检测也要配置在集群级别;
示例1:用于配置在返 回3个连续5xx错误时将主机弹出30秒:
consecutive_5xx: "3"
base_ejection_time: "30s"
示例2:在新服务上启用异常检测时应该从不太严格的规则集开始,以便仅弹出具有网关 连接错误的主机(HTTP 503),并且仅在10%的时间内弹出它们:
consecutive_gateway_failure: "3"
base_ejection_time: "30s"
enforcing_consecutive_gateway_failure: "10"
示例3:同时,高流量、稳定的服务可以使用统计信息来弹出频繁异常容的主机;下面的 配置示例将弹出错误率低于群集平均值1个标准差的任何端点,统计信息每10秒进 行一次评估,并且算法不会针对任何在10秒内少于500个请求的主机运行:
interval: "10s"
base_ejection_time: "30s"
success_rate_minimum_hosts: "10"
success_rate_request_volume: "500"
success_rate_stdev_factor: "1000" # divided by 1000 to get a double
root@istio:~/ServiceMesh_in_Practise/cluster-manager/outlier-detection# ls
docker-compose.yaml front-envoy.yaml
Envoy提供了几种不同的负载均衡策略,并可大体分为全局负载均衡和分布式负 载均衡两类;
分布式负载均衡:Envoy自身基于上游主机(区域感知)的位置及健康状态等来确定如何 分配负载至相关端点
- 主动健康检查
- 区域感知路由
- 负载均衡算法
全局负载均衡:这是一种通过单个具有全局权限的组件来统一决策负载机制,Envoy的控 制平面即是该类组件之一,它能够通过指定各种参数来调整应用于各端点的负载
- 优先级
- 位置权重
- 端点权重
- 端点健康状态
复杂的部署场景可以混合使用两类负载均衡策略,全局负载均衡通过定义高级路 由优先级和权重以控制同级别的流量,而分布式负载均衡用于对系统中的微观变动 作出反应(例如主动健康检查);
clusters:
- name: ...
...
load_assignment: {...}
cluster_name: ...
endpoints: [] # LocalityLbEndpoints列表,每个列表项主要由位置、端点列表、权重和优先级四项组成;
- locality: {...} # 位置定义
region: ...
zone: ...
sub_zone: ...
lb_endpoints: [] # 端点列表
- endpoint: {...} # 端点定义
address: {...} # 端点地址
health_check_config: {...} # 当前端点与健康状态检查相关的配置;
load_balancing_weight: ... # 当前端点的负载均衡权重,可选;
metadata: {...} # 基于匹配的侦听器、过滤器链、路由和端点等为过滤器提供额外信息的元数据,常用用于提供服务配置或辅助负载均衡;
health_status: ... # 端点是经EDS发现时,此配置项用于管理式设定端点的健康状态,可用值有UNKOWN、HEALTHY、UNHEALTHY、DRAINING、TIMEOUT和DEGRADED;
load_balancing_weight: {...} # 设置locality权重
priority: ... # 设置locality优先级
policy: {...} # 负载均衡策略设定
drop_overloads: [] # 过载保护机制,丢弃过载流量的机制;
overprovisioning_factor: ... # 整数值,定义超配因子(百分比),默认值为140,即1.4;
endpoint_stale_after: ... # 过期时长,过期之前未收到任何新流量分配的端点将被视为过时,并标记为不健康;默认值0表示永不过时;
lb_subset_config: {...}
ring_hash_lb_config: {...}
original_dst_lb_config: {...}
least_request_lb_config: {...}
common_lb_config: {...}
health_panic_threshold: ... # Panic阈值,默认为50%;
zone_aware_lb_config: {...} # 区域感知路由的相关配置;
locality_weighted_lb_config: {...} # 局部权重负载均衡相关的配置;
ignore_new_hosts_until_first_hc: ... # 是否在新加入的主机经历第一次健康状态检查之前不予考虑进负载均衡;
Cluster Manager使用负载均衡策略将下游请求调度至选中的上游主机,它支持如下 几个算法:
- 加权轮询(weighted round robin):算法名称为ROUND_ROBIN
- 加权最少请求(weighted least request):算法名称为LEAST_REQUEST
- 环哈希(ring hash):算法名称为RING_HASH,其工作方式类似于一致性哈希算法;
- 磁悬浮(maglev):类似于环哈希,但其大小固定为65537,并需要各主机映射的节点填 满整个环;无论配置的主机和位置权重如何,算法都会尝试确保将每个主机至少映射一 次;算法名称为MAGLEV
- 随机(random):未配置健康检查策略,则随机负载均衡算法通常比轮询更好;
另外,还有原始目标集群负载均衡机制,其算法为ORIGINAL_DST_LB,但仅适 用于原始目标集群的调度;
root@istio:~/ServiceMesh_in_Practise/cluster-manager/weighted-rr# ls
docker-compose.yaml front-envoy.yaml send-request.sh
加权最少请求算法根据主机的权重相同或不同而使用不同的算法。该算法适应于长连接的应用,比如MySQL等。
所有主机的权重均相同
- 这是一种复杂度为O(1)调度算法,它随机选择N个(默认为2,可配置)可用主机并从中挑 选具有最少活动请求的主机;
- 研究表明,这种称之为P2C的算法效果不亚于O(N)复杂度的全扫描算法,它确保了集群中 具有最大连接数的端点决不会收到新的请求,直到其连接数小于等于其它主机;
所有主机的权重并不完全相同,即集群中的两个或更多的主机具有不同的权重
- 调度算法将使用加权轮询调度的模式,权重将根据主机在请求时的请求负载进行动态调整 ,方法是权重除以当前的活动请求计数;例如,权重为2且活动请求计数为4的主机的综合 权重为2/4 = 0.5)
- 该算法在稳态下可提供良好的平衡效果,但可能无法尽快适应不太均衡的负载场景;
- 与P2C不同,主机将永远不会真正排空,即便随着时间的推移它将收到更少的请求;
LEAST_REQUEST的配置参数:
least_request_lb_config:
choice_count: "{...}" # 从健康主机中随机挑选出多少个做为样本进行最少连接数比较,默认为2;
Envoy使用ring/modulo算法对同一集群中的上游主机实行一致性哈希算法,但它需要依赖于在路由中定义了相应的哈希策略时方才有效;
通过散列其地址的方式将每个主机映射到一个环上,然后,通过散列请求的某些属性后将其映射在环上,并以顺时针方式找到最接近的对应主机从而完成路由;该技术通常也称为“ Ketama” 散列,并且像所有基于散列的负载平衡器一样,仅在使用协议路由指定要散列的值时才有效;
为了避免环偏斜,每个主机都经过哈希处理,并按其权重成比例地放置在环上;最佳做法是显式设置minimum_ring_size和maximum_ring_size参数,并监视min_hashes_per_host和max_hashes_per_host指标以确保请求的能得到良好的均衡。
配置参数:
ring_hash_lb_config:
"minimum_ring_size": "{...}", # 哈希环的最小值,环越大调度结果越接近权重酷比,默认为1024,最在值为8M;
"hash_function": "...", # 哈希算法,支持XX_HASH和MURMUR_HASH_2两种,默认为前一种;
"maximum_ring_size": "{...}" # 哈希环的最大值,默认为8M;不过,值越大越消耗计算资源;
route.RouteAction.HashPolicy用于一致性哈希算法的散列策略列表,即指定将请求报文的哪部分属性进行哈希运算并映射至主机的哈希环上以完成路由。
列表中每个哈希策略都将单独评估,合并后的结果用于路由请求;组合的方法是确定性的,以便相同的哈希策略列表将产生相同的哈希。
哈希策略检查的请求的特定部分不存时将会导致无法生成哈希结果。如果(且仅当)所有已配置的哈希策略均无法生成哈希,则不会为该路由生成哈希,在这 种情况下,其行为与未指定任何哈希策略的行为相同(即,环形哈希负载均衡器将选择一 个随机后端);
若哈希策略将“ terminal”属性设置为true,并且已经生成了哈希,则哈希算法将立即返回,而忽略哈希策略列表的其余部分;
路由哈希策略定义在路由配置中
route_config:
...
virutal_host:s:
- ...
routes:
- match:
...
route:
...
hash_policy: [] # 指定哈希策略列表,每个列表项仅可设置如下header、cookie或connection_properties三者之一;
header: {...}
header_name: ... # 要哈希的首部名称
cookie: {...}
name: ... # cookie的名称,其值将用于哈希计算,必选项;
ttl: ... # 持续时长,不存在带有ttl的cookie将自动生成该cookie;如果TTL存在且为零,则生成的cookie将是会话cookie
path: ... # cookie的路径;
connection_properties: {...}
source_ip: ... # 布尔型值,是否哈希源IP地址;
terminal: ... # 是否启用哈希算法的短路标志,即一旦当前策略生成哈希值,将不再考虑列表中后续的其它哈希策略;
示例:
下面的示例将哈希请求报文的源IP地址和User-Agent首部;
static_resources:
listeners:
- address:
socket_address:
address: 0.0.0.0
port_value: 80
name: listener_http
filter_chains:
- filters:
- name: envoy.http_connection_manager
typed_config:
"@type": type.googleapis.com/envoy.config.filter.network.http_connection_manager.v2.HttpConnectionManager
codec_type: auto
stat_prefix: ingress_http
route_config:
name: local_route
virtual_hosts:
- name: backend
domains:
- "*"
routes:
- match:
prefix: "/"
route:
cluster: webcluster1
hash_policy: #基于head的hash
- header:
header_name: User-Agent
http_filters:
- name: envoy.router
clusters:
- name: webcluster1
connect_timeout: 0.25s
type: STRICT_DNS
lb_policy: RING_HASH #hash环
ring_hash_lb_config: #hash环配置
maximum_ring_size: 1048576
minimum_ring_size: 512
http2_protocol_options: {}
load_assignment:
cluster_name: webcluster1
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: myservice
port_value: 80
root@istio:~/ServiceMesh_in_Practise/cluster-manager/ring-hash# ls
docker-compose.yaml front-envoy.yaml
Maglev是环哈希算法的一种特殊形式,它使用固定为65537的环大小;环构建算法将每个主机按其权重成比例地放置在环上,直到环完全填满为止;例如,如 果主机A的权重为1,主机B的权重为2,则主机A将具有21,846项,而主机B将具有43,691 项(总计65,537项);
该算法尝试将每个主机至少放置一次在表中,而不管配置的主机和位置权重如何,因此 在某些极端情况下,实际比例可能与配置的权重不同;最佳做法是监视min_entries_per_host和max_entries_per_host指标以确保没有主机出现异常 配置; :9901/stats?filter=hash
在需要一致哈希的任何地方,Maglev都可以取代环哈希;同时,与环形哈希算法 一样,Magelev仅在使用协议路由指定要哈希的值时才有效;通常,与环哈希ketama算法相比,Maglev具有显着更快的表查找建立时间以及主机选择时间;稳定性略逊于环哈希。
EDS配置中,属于某个特定位置的一组端点称为LocalityLbEndpoints(逻辑组合),它们具有相同的位置( locality)、权重(load_balancing_weight)和优先级(priority); 每个逻辑组内再会按照负载均衡策略进行负载。
locality:从大到小可由region(地域)、zone(区域)和sub_zone(子区域)进行逐级标识;
load_balancing_weight:可选参数,用于为每个priority/region/zone/sub_zone配置权重,取值范围[1,n);通常,一个locality权重除以具有相同优先级的所有locality的权重之和即为当前locality的流量比例; 此配置仅启用了位置加权负载均衡机制时才会生效;
priority:此LocalityLbEndpoints组的优先级,默认为最高优先级0;
通常,Envoy调度时仅挑选最高优先级的一组端点,且仅此优先级的所有端点均不可用时才进行故障转移至下一个优先级的相关端点;
注意,也可在同一位置配置多个LbEndpoints,但这通常仅在不同组需要具有不同的负载均衡权重或不同的优先级时才需要;
# endpoint.LocalityLbEndpoints
{
"locality": "{...}",
"lb_endpoints": [],
"load_balancing_weight": "{...}",
"priority": "..."
}
调度时,Envoy仅将流量调度至最高优先级的一组端点(LocalityLbEnpoints)。
在最高优先级的端点变得不健康时,流量才会按比例转移至次一个优先级的端点;例如一个优先级中20%的端点不健康时,也将有20%的流量转移至次一个优先级端点;
超配因子:也可为一组端点设定超配因子,实现部分端点故障时仍将更大比例的流量导向至本组端点,默认的超配因子为1.4;计算公式:
转移的流量=100%-健康的端点比例*超配因子;于是,对于1.4的因子来说,20%的故障比例时,所有流量仍将保留在当前组(80%*1.4=112%,表示能够承载112%的流量);当健康的端点比例低于72%时,才会有部分流量(72%*1.4=100.8%)转移至次优先级端点; 一个优先级别当前处理流量的能力也称为健康评分(健康主机比例*超配因子,上限为100%,超出100%表示健康),健康评分表示了该组处理全部流量的比例。(作用:容忍一定比例的端点不健康,在可容忍的比例内,可以不触发流量比例的重新分配)若各个优先级的健康评分总和(也称为标准化的总健康状态)小于100,则Envoy会认为没有足够的健康端点来分配所有待处理的流量,此时,各级别会根据其健康分值的比例重新分配100%的流量;例如,对于具有{20,30}健康评分的两个组(标准化的总健康状况为50)将被标准化,并导致负载比例为40%和60%;
另外,优先级调度还支持同一优先级内部的端点降级(DEGRADED)机制(再次对组内节点进行划分的机制),其工作方式类同于在两个不同优先级之间的端点分配流量的机制。
非降级端点健康比例*超配因子大于等于100%时,降级端点不承接流量;*非降级端点的健康比例*超配因子小于100%时,降级端点承接与100%差额部分的流量;
调度期间,Envoy仅考虑上游主机列表中的可用(健康或降级)端点,但可用端点的百分比过低时,Envoy将忽略所有端点的健康状态并将流量调度给所有端点;此百分比即为Panic阈值,也称为恐慌阈值;
- 默认的Panic阈值为50%;
- Panic阈值用于避免在流量增长时导致主机故障进入级联状态;
恐慌阈值可与优先级一同使用。给定优先级中的可用端点数量下降时,Envoy会将一些流量转移至较低优先级的端点;
- 若在低优先级中找到的承载所有流量的端点,则忽略恐慌阈值;
- 否则,Envoy会在所有优先级之间分配流量,并在给定的优先级的可用性低于恐慌阈值时,将该优先级的流量分配至该优先级的所有主机;
# Cluster.CommonLbConfig
{
"healthy_panic_threshold": "{...}", # 百分比数值,定义恐慌阈值,默认为50%;
"zone_aware_lb_config": "{...}",
"locality_weighted_lb_config": "{...}",
"update_merge_window": "{...}",
"ignore_new_hosts_until_first_hc": "..."
}
clusters:
- name: webcluster1
connect_timeout: 0.25s
type: STRICT_DNS
lb_policy: ROUND_ROBIN
load_assignment:
cluster_name: webcluster1
endpoints: #定义了2个locality。默认情况下由优先级高的locality下的端点使用lb_policy: ROUND_ROBIN的方式处理
- locality:
region: cn-north-1
priority: 0
lb_endpoints:
- endpoint:
address:
socket_address:
address: colored
port_value: 80
- locality: #当基于主动健康检测时,高优先级的locality中的ep不健康后,并且不健康的比例超过了超配因子(即(100-健康比例*超配因子)>0)后,会将(100-健康比例*超配因子)%该比例的流量导向该locality
region: cn-north-2
priority: 1
lb_endpoints:
- endpoint:
address:
socket_address:
address: myservice
port_value: 80
health_checks:
- ...
演示示例:
root@istio:~/ServiceMesh_in_Practise/cluster-manager/priority-levels# ls
README.md docker-compose.yaml front-envoy.yaml
位置加权负载均衡(Locality weighted load balancing)即为特定的Locality及相关的 LbEndpoints组显式赋予权重,并根据此权重比在各Locality之间分配流量;
所有Locality的所有Endpoint均可用时,则根据位置权重在各Locality之间进行加权轮询;例如,cn-north-1和cn-north-2两个region的权重分别为1和2时,且各region内的端点均处理于健康状态,则流量分配比例为“1:2”,即一个33%,一个是67%;
启用位置加权负载均衡及位置权重定义的方法:
cluster:
- name: ...
...
common_lb_config:
locality_weighted_lb_config: {} # 启用位置加权负载均衡机制,它没有可用的子参数;
...
load_assignment:
endpoints:
locality: "{...}"
lb_endpoints": []
load_balancing_weight: "{}" # 整数值,定义当前位置或优先级的权重,最小值为1;
priority: "..."
注意:位置加权负载均衡同区域感知负载均衡互斥,因此,用户仅可在Cluster级别设置 locality_weighted_lb_config或zone_aware_lb_config其中之一,以明确指定启用的负载均衡策略。
当某Locality的某些Endpoint不可用时,Envoy则按比例动态调整该Locality的权重。位置加权负载均衡方式也支持为LbEndpoint配置超配因子,默认为1.4;于是,一个Locality(假设为X)的有效权重计算方式如下:
health(L_X) = 140 * healthy_X_backends / total_X_backends
effective_weight(L_X) = locality_weight_X * min(100, health(L_X))
load to L_X = effective_weight(L_X) / Σ_c(effective_weight(L_c))
例如,假设位置X和Y分别拥有1和2的权重,则Y的健康端点比例只有50%时,其权重调 整为“2×(1.4×0.5)=1.4”,于是流量分配比例变为“1:1.4”;
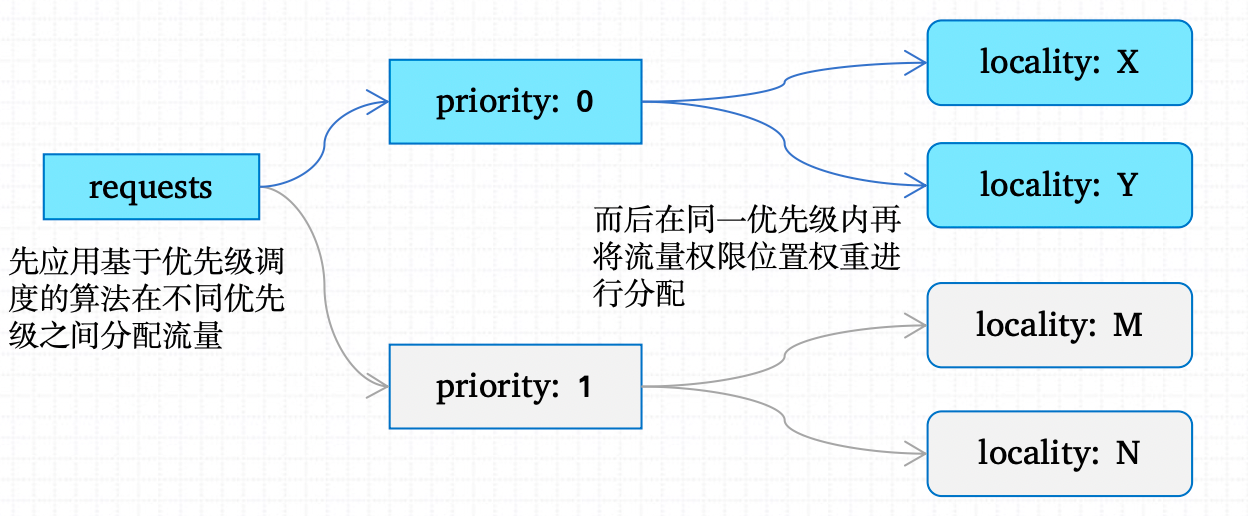
若同时配置了优先级和位置权重,负载均衡器将会以如下步骤进行调度:
- 优先级调度:选择priority最高的locality组,可能多个组;
- 位置加权调度:从选出的priority中选择locality;
- 端点调度:从选出的locality中选择Endpoint;
clusters:
- name: webcluster1
connect_timeout: 0.25s
type: STRICT_DNS
lb_policy: ROUND_ROBIN
common_lb_config:
locality_weighted_lb_config: {} #启用“位置权重”
load_assignment:
cluster_name: webcluster1
policy:
overprovisioning_factor: 140
endpoints:
- locality:
region: cn-north-1
priority: 0 #locality的优先级
load_balancing_weight: 1 #locality的权重(位置权重)
lb_endpoints:
- endpoint:
address:
socket_address:
address: colored
port_value: 80
- locality:
region: cn-north-2
priority: 0 #locality的优先级
load_balancing_weight: 2 #locality的权重
lb_endpoints:
- endpoint:
address:
socket_address:
address: myservice
port_value: 80
说明:
该集群定义了两个Locality,cn-north-1和 cn-north-2,它们分别具有权重1和2;它们具有相同的优先级0。于是,所有端点都健康时,该集群的流量 会以1:2的比例分配至cn-north-1和cn- north-2;
假设cn-north-2具有两个端点,且一个端点健康状态检测失败时,则流量分配变更为 1:1.4。
1.4=2*(50%*1.4)
演示示例:
root@istio:~/ServiceMesh_in_Practise/cluster-manager/locality-weighted# ls
README.md docker-compose.yaml front-envoy.yaml send-request.sh
可以通过删除容器内的/var/www/html/health.html文件,来标记一个示例转换成不健康状态。
Envoy还支持在一个集群中基于子集实现更细粒度的流量分发。首先,在集群的上游主机上添加元数据(键值标签),并使用子集选择器(分类元数据)将上游主机划分为子集;而后,在路由配置中指定负载均衡器可以选择的且必须具有匹配的元数据的上游主机, 从而实现向特定子集的路由;各子集内的主机间的负载均衡采用集群定义的策略(lb_policy);
配置了子集,但路由并未指定元数据或不存在与指定元数据匹配的子集时,则子 集均衡均衡器为其应用“回退策略”:
- NO_FALLBACK:请求失败,类似集群中不存在任何主机;此为默认策略;
- ANY_ENDPOINT:在所有主机间进行调度,不再考虑主机元数据;
- DEFAULT_SUBSET:调度至默认的子集,该子集需要事先定义;
子集必须预定义,方可由子集负载均衡器在调度时使用:
- 定义主机元数据:键值数据
主机的子集元数据必须要定义在“envoy.lb”过滤器下;仅当使用ClusterLoadAssignments定义主机时才支持主机元数据,有2种方式:
通过EDS发现的端点
通过load_assignment字段定义的端点
load_assignment:
cluster_name: webcluster1
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
protocol: TCP
address: ep1
port_value: 80
metadata:
filter_metadata:
envoy.lb:
version: '1.0'
stage: 'prod'
- 定义子集:基于子集选择器,目标仅支持键值列表
clusters:
- name ...
...
lb_subset_config
fallback_policy: "..." # 回退策略,默认为NO_FALLBACK
default_subset: "{...}" # 回退策略DEFAULT_SUBSET使用的默认子集;
subset_selectors: [] # 子集选择器
- keys: [] # 定义一个选择器,指定用于归类主机元数据的键列表;
- key1
- key2
- ...
fallback_policy: ... # 当前选择器专用的回退策略;
locality_weight_aware: "..." # 是否在将请求路由到子集时考虑端点的位置和位置权重;存在一些潜在的缺陷;
scale_locality_weight: "..." # 是否将子集与主机中的主机比率来缩放每个位置的权重;
panic_mode_any: "..." # 是否在配置回退策略且其相应的子集无法找到主机时尝试从整个集群中选择主机;
list_as_any: "..."
对于每个选择器,Envoy会遍历主机并检查其“envoy.lb”过滤器元数据,并为每个惟一的 键值组合创建一个子集;
若某主机元数据可以匹配该选择器中指定每个键,则会将该主机添加至此选择器中;这同时意味着,一个主机可能同时满足多个子集选择器的适配条件,此时,该主机将同时隶属 于多个子集;
若所有主机均未定义元数据,则不会生成任何子集;
- 路由元数据匹配(metadata_match)
使用负载均衡器子集还要求在路由条目上配置元数据匹配(metadata_match)条件,它用于在路由期间查找特定子集;
- 仅在上游集群中与metadata_match中设置的元数据匹配的子集时才能完成流量路由;
- 使用了weighted_clusters定义路由目标时,其内部的各目标集群也可定义专用的metadata_match;
routes:
- name: ...
match: {...}
route: {...} # 路由目标,cluster和weighted_clusters只能使用其一;
cluster:
metadata_match: {...} # 子集负载均衡器使用的端点元数据匹配条件;若使用了weighted_clusters且内部定义了metadat_match,
# 则元数据将被合并,且weighted_cluster中定义的值优先;过滤器名称应指定为envoy.lb;
filter_metadata: {...} # 元数据过滤器
envoy.lb: {...}
key1: value1
key2: value2
...
weighted_clusters: {...}
clusters: []
- name: ...
weight: ...
metadata_match: {...}
不存在与路由元数据匹配的子集时,将启用回退策略;
表格是集群中的节点及其拥 有的元数据:
| Endpint | stage | version | type | xlarge |
|---|---|---|---|---|
| e1 | prod | 1.0 | std | true |
| e2 | prod | 1.0 | std | |
| e3 | prod | 1.1 | std | |
| e4 | prod | 1.1 | std | |
| e5 | prod | 1.0 | bigmem | |
| e6 | prod | 1.1 | bigmem | |
| e7 | dev | 1.2-pre | std |
子集选择器定义:
lb_subset_config:
fallback_policy: DEFAULT_SUBSET
default_subset:
stage: "prod"
version: "1.0"
type: "std"
subset_selectors:
- keys: ["stage", "type"]
- keys: ["stage", "version"]
- keys: ["version"]
- keys: ["xlarge", "version"]
映射出十个子集:
- stage=prod, type=std (e1, e2, e3, e4)
- stage=prod, type=bigmem (e5, e6)
- stage=dev, type=std (e7)
- stage=prod, version=1.0 (e1, e2, e5)
- stage=prod, version=1.1 (e3, e4, e6)
- stage=dev, version=1.2-pre (e7)
- version=1.0 (e1, e2, e5)
- version=1.1 (e3, e4, e6)
- version=1.2-pre (e7)
- version=1.0, xlarge=true (e1)
此外,还有一个默认的子集:
- stage=prod, type=std, version=1.0 (e1, e2)
路由时,路由上配置的元数据用于匹配和过滤出目标子集;路由匹配条件也需要 使用“envoy.lb”过滤器:存在匹配的子集时,其将用于负载均衡的调度目标范围; 否则,应用回退策略;
routes:
- match:
prefix: "/"
headers:
- name: x-custom-version
value: pre-release
route:
cluster: webcluster1
metadata_match:
filter_metadata:
envoy.lb:
version: "1.2-pre"
stage: "dev"
- match:
prefix: "/"
headers:
- name: x-hardware-test
value: memory
route:
cluster: webcluster1
metadata_match:
filter_metadata:
envoy.lb:
type: "bigmem"
stage: "prod"
- match:
prefix: "/"
route:
weighted_clusters:
clusters:
- name: webcluster1
weight: 90
metadata_match:
filter_metadata:
envoy.lb:
version: "1.0"
- name: webcluster1
weight: 10
metadata_match:
filter_metadata:
envoy.lb:
version: "1.1"
metadata_match:
filter_metadata:
envoy.lb:
stage: "prod"
演示示例:
root@istio:~/ServiceMesh_in_Practise/cluster-manager/lb-subsets# ls
README.md docker-compose.yaml front-envoy.yaml test.sh
多级服务调度用场景中,某上游服务因网络故障或服 务繁忙无法响应请求时很可能会导致多级上游调用者大 规模级联故障,进而导致整个系统不可用,此即为服务的雪崩效应;
熔断:上游服务(服务提供者)因压力过大而变得响应过慢甚至失败时,下游服务(服务消费者)通过暂时切断对上游的请 求调用达到牺牲局部,保全上游甚至是整体之目的;
熔断打开(Open):在固定时间窗口内,检测指标达到指定的阈值时启动熔断;
熔断半打开(HalfOpen):断路器在工作一段时间后自动切换至半打开状态,并根据下一次请求的返回结果判断状态切换。
- 请求成功:转为熔断关闭状态;
- 请求失败:切回熔断打开状态;
熔断关闭(Closed):一定时长后上游服务可能会变得再次可用,此时下游即可关闭熔断,并再次请求其服务;
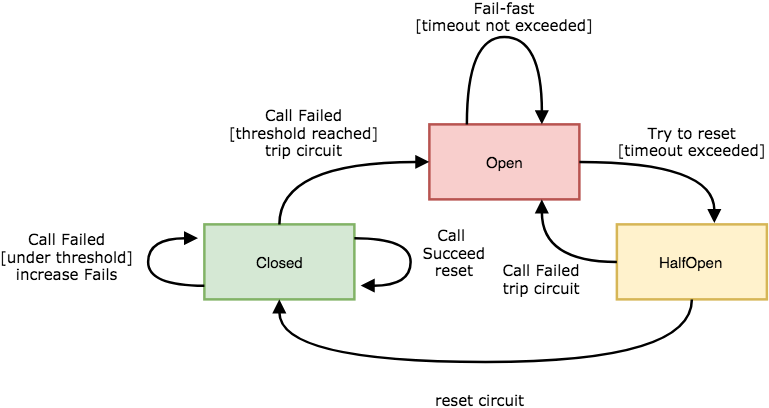
总结起来, 熔断是分布式应用常用的一种流量管理模式,它能够让应用程序免受上游服务失败、延迟峰值或其 它网络异常的侵害;
Envoy在网络级别(TCP)强制进行断路限制,于是不必独立配置和编码每个应用;
Envoy支持多种类型的完全分布式断路机制,达到由其定义的阈值时,相应的断路器即会溢出:
集群最大连接数:Envoy同上游集群建立的最大连接数,仅适用于HTTP/1.1,因为 HTTP/2可以链路复用;
集群最大请求数:在给定的时间,集群中的所有主机未完成的最大请求数,仅适用于 HTTP/2;
集群可挂起的最大请求数:连接池满载时所允许的等待队列的最大长度;
集群最大活动重试次数:给定时间内集群中所有主机可以执行的最大重试次数;
集群最大并发连接池:可以同时实例化出的最大连接池数量;
每个断路器都可在每个集群及每个优先级的基础上进行配置和跟踪,它们可分别拥有各自不同的设定;
在istio中,熔断的功能通过连接池(连接池管理)和故障实例隔离(异常点检测)进行定义,而Envoy的断路器通常仅对应于Istio中的连接池功能。
- 通过限制某个客户端对目标服务的连接数、访问请求、队列长度和重试次数等,避免对一个服务的过量访问。
- 某个服务实例频繁超时或出错时将其逐出,以避免影响整个服务。
最大连接数:表示在任何给定时间内, Envoy 与上游集群建立的最大连接数,适用于 HTTP/1.1;
每连接最大请求数:表示在任何给定时间内,上游集群中所有主机可以处理的最大请求数;若设为 1 则会禁止 keep alive 特性;
最大请求重试次数:在指定时间内对目标主机最大重试次数
连接超时时间:TCP 连接超时时间,最小值必须大于 1ms;最大连接数和连接超时时间是对 TCP 和HTTP 都有效的通用连接设置;
最大等待请求数:待处理请求队列的长度,若该断路器溢出,集群的 upstream_rq_pending_overflow计 数器就会递增
断路器的相关设置由circuit_breakers定义;
与连接池相关的参数有两个,定义在cluster的上下文;
clusters:
- name: ...
...
connect_timeout: ... # TCP连接的超时时长,即主机网络连接超时,合理的设置可以能够改善因调用服务变慢而导致整个链接变慢的情形;
max_requests_per_connection: ... # 每个连接可以承载的最大请求数,HTTP/1.1和HTTP/2的连接池均受限于此设置,无设置则无限制,1表示禁用keep-alive
...
circuit_breakers: {...} # 熔断相关的配置,可选;
threasholds: [] # 适用于特定路由优先级的相关指标及阈值的列表;
- priority: ... # 当前断路器适用的路由优先级;
max_connections: ... # 上游集群可承载的最大连接数,默认为1024;
max_pending_requests: ... # 上游集群支持的可挂起的最大请求数,默认为1024;
max_requests: ... # Envoy可调度给上游集群的最大并发请求数,默认为1024;
max_retries: ... # 允许发往上游集群的最大并发重试数量,默认为3;
track_remaining: ... # 其值为true时表示将公布统计数据以显示断路器打开前所剩余的资源数量;默认为false;
max_connection_pools: ... # 每个集群可同时打开的最大连接池数量,默认为无限制;
将max_connections和 最max_pending_requests都设置为 1,表示如果超过了 一个连接同时发起请求,Envoy就会熔断,阻止后续的请求或连接;
集群级断路器配置示例:
clusters:
- name: service_httpbin
connect_timeout: 2s
type: LOGICAL_DNS
dns_lookup_family: V4_ONLY
lb_policy: ROUND_ROBIN
load_assignment:
cluster_name: service_httpbin
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: httpbin.org
port_value: 80
circuit_breakers:
thresholds:
max_connections: 1
max_pending_requests: 1
max_retries: 3
max_requests: 1
可使用工具fortio进行压力测试,例如:fortio -- load -c 2 -qps 0 -n 20 -loglevel Warning <URL>
root@istio:~/ServiceMesh_in_Practise/cluster-manager/circuit-breaker# ls
docker-compose.yaml front-envoy.yaml send-requests.sh service-envoy.yaml