1.1 K8s部署之kubeadm单master
参考文档:单Master的k8s安装、多Master的k8s安装、多Master其他文档
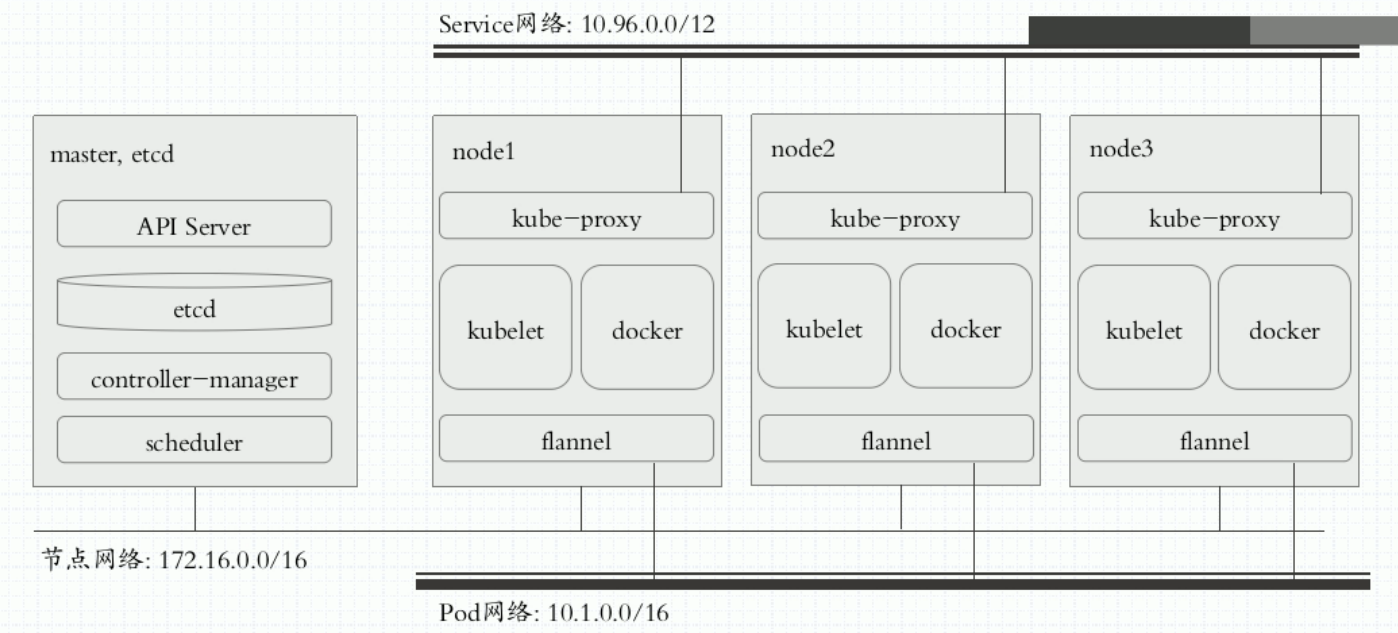
kubeadm安装单Master拓补图:
cat <<EOF >> /etc/hosts
192.168.5.36 k8smaster
192.168.5.37 k8snode01
192.168.5.38 k8snode02
EOF
systemctl stop firewalld && systemctl disable firewalld && setenforce 0 && sed -i "s/^SELINUX=enforcing/SELINUX=disabled/g" /etc/sysconfig/selinux
swapoff -a && sed -i 's/.swap./#&/' /etc/fstab
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system
yum install -y ntp
cat <<EOF >/etc/ntp.conf
driftfile /var/lib/ntp/drift
restrict default nomodify notrap nopeer noquery
restrict 127.0.0.1
restrict ::1
restrict 192.168.5.0 mask 255.255.255.0 nomodify notrap
server 0.cn.pool.ntp.org
server 1.cn.pool.ntp.org
server 2.cn.pool.ntp.org
server 3.cn.pool.ntp.org
includefile /etc/ntp/crypto/pw
keys /etc/ntp/keys
disable monitor
EOF
systemctl restart ntpd
systemctl enable ntpd
**阿里云yum源 **
cd /etc/yum.repos.d/
curl -O https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
cat <<-EOF >kubernets.repo
[Kubernetes]
name=kubernetes repo
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
enabled=1
EOF
yum repolist #检查仓库是否配置正确,如果出现以上配置的两个仓库的信息,说明配置正确
yum install -y kubelet kubeadm kubectl docker-ce
systemctl enable docker.service && systemctl restart docker.service
systemctl enable kubelet.service #kubelet此时无法启动
这一步之后,进行systemctl start kubelet.service会报错,这是因为kubelet目前还不能正常运行,还处于缺少各种配置文件(、证书)的状态。这些配置文件需要kubeadm init时自动为kubelet生成。
The kubelet is now restarting every few seconds(RestartSec=10), as it waits in a crashloop for kubeadm to tell it what to do. 此时的kubelet处于每隔几秒重启一次的状态,这种崩溃循环是正常的,kubelet在这个崩溃循环中等待kubeadm告诉它该怎么做。
列出kubeadm安装过程中使用的image:
[root@k8smaster ~]# kubeadm config images list --kubernetes-version=1.11.1
k8s.gcr.io/kube-apiserver-amd64:v1.11.1
k8s.gcr.io/kube-controller-manager-amd64:v1.11.1
k8s.gcr.io/kube-scheduler-amd64:v1.11.1
k8s.gcr.io/kube-proxy-amd64:v1.11.1
k8s.gcr.io/pause:3.1
k8s.gcr.io/etcd-amd64:3.2.18
k8s.gcr.io/coredns:1.1.3
因为国内没办法访问Google的镜像源,变通的方法是从其他镜像源下载后,修改tag。执行下面这个Shell脚本即可。通过阿里云容器镜像服务下载gcr.io镜像
kubernetes_version=1.11.1
images=(flannel:v0.10.0-amd64)
for i in $(kubeadm config images list --kubernetes-version=${kubernetes_version}); do
images+=(${i##*/})
done
#images=(kube-apiserver-amd64:v1.11.1 kube-controller-manager-amd64:v1.11.1 kube-scheduler-amd64:v1.11.1 kube-proxy-amd64:v1.11.1 pause:3.1 etcd-amd64:3.2.18 coredns:1.1.3 flannel:v0.10.0-amd64)
for imageName in ${images[@]} ; do
if [[ ${imageName##pause} != ${imageName} ]]; then #对pause镜像特殊处理
docker pull registry.cn-hangzhou.aliyuncs.com/ljzsdut/pause-amd64:${imageName##*:}
docker tag registry.cn-hangzhou.aliyuncs.com/ljzsdut/pause-amd64:${imageName##*:} k8s.gcr.io/pause:${imageName##*:}
docker rmi registry.cn-hangzhou.aliyuncs.com/ljzsdut/pause-amd64:${imageName##*:}
else
docker pull registry.cn-hangzhou.aliyuncs.com/ljzsdut/$imageName
docker tag registry.cn-hangzhou.aliyuncs.com/ljzsdut/$imageName k8s.gcr.io/$imageName
docker rmi registry.cn-hangzhou.aliyuncs.com/ljzsdut/$imageName
fi
done
#上面的脚本为什么要对pause特殊处理?
#因为通过kubeadm部署k8s集群,在执行kubeadm init命令时,默认生成的manifests文件夹下yaml文件上拉取的pause镜像的tag为pause:3.1。而gcr.io上的镜像tag为gcr.io/google_containers/pause-amd64:3.1,两者的命名不一样,所以需要特殊处理。
此外,如果不使用flannel作为pod网络,flannel:v0.10.0-amd64镜像是不需要的。而且flannel镜像的版本与安装flannel的doployment的yaml文件配置有关。
在执行初始化之前,我们还有一下3点需要注意:
1.选择一个网络插件,并检查它是否需要在初始化Master时指定一些参数,比如我们可能需要根据选择的插件来设置--pod-network-cidr参数。参考:Installing a pod network add-on。
2.kubeadm使用eth0的默认网络接口(通常是内网IP)做为Master节点的advertise address,如果我们想使用不同的网络接口,可以使用--apiserver-advertise-address=<ip-address>参数来设置。如果适应IPv6,则必须使用IPv6d的地址,如:--apiserver-advertise-address=fd00::101。
3.使用kubeadm config images pull来预先拉取初始化需要用到的镜像,用来检查是否能连接到Kubenetes的Registries。
Kubenetes默认Registries地址是k8s.gcr.io,很明显,在国内并不能访问gcr.io,因此在kubeadm v1.13之前的版本,安装起来非常麻烦,但是在1.13版本中终于解决了国内的痛点,其增加了一个--image-repository参数,默认值是k8s.gcr.io,我们将其指定为国内镜像地址:registry.aliyuncs.com/google_containers,其它的就可以完全按照官方文档来愉快的玩耍了。
其次,我们还需要指定--kubernetes-version参数,因为它的默认值是stable-1,会导致从https://dl.k8s.io/release/stable-1.txt下载最新的版本号,我们可以将其指定为固定版本(最新版:v1.13.0)来跳过网络请求。
现在,我们就来试一下:
# 使用calico网络 --pod-network-cidr=192.168.0.0/16
sudo kubeadm init --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.13.0 --pod-network-cidr=192.168.0.0/16
接下来执行Master节点的初始化:
kubeadm init首先会进行一系列的预检查,然后下载并安装集群组件。常用参数:kubeadm init –help查看
–kubernetes-version=v1.11[.1] 指定k8s版本
–pod-network-cidr=10.244.0.0/16 指定pod使用的网络,该值与network组件有关,不同的组件使用不同的值。参考pod网络
–service-cidr=10.96.0.0/12 指定service使用的网络,默认为"10.96.0.0/12"
–apiserver-advertise-address=192.168.5.36 指定apiserver监听地址,默认为0.0.0.0
–apiserver-bind-port=6443 指定apiserver监听端口,默认6443
[root@k8smaster ~]# kubeadm init --kubernetes-version=v1.11.1 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12 --apiserver-advertise-address=192.168.5.36
[init] using Kubernetes version: v1.11.1
[preflight] running pre-flight checks
I0727 17:30:32.271950 9927 kernel_validator.go:81] Validating kernel version
I0727 17:30:32.272189 9927 kernel_validator.go:96] Validating kernel config
[WARNING SystemVerification]: docker version is greater than the most recently validated version. Docker version: 18.06.0-ce. Max validated version: 17.03
[preflight/images] Pulling images required for setting up a Kubernetes cluster
[preflight/images] This might take a minute or two, depending on the speed of your internet connection
[preflight/images] You can also perform this action in beforehand using 'kubeadm config images pull'
[kubelet] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[preflight] Activating the kubelet service
[certificates] Generated ca certificate and key.
[certificates] Generated apiserver certificate and key.
[certificates] apiserver serving cert is signed for DNS names [k8smaster kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.5.36]
[certificates] Generated apiserver-kubelet-client certificate and key.
[certificates] Generated sa key and public key.
[certificates] Generated front-proxy-ca certificate and key.
[certificates] Generated front-proxy-client certificate and key.
[certificates] Generated etcd/ca certificate and key.
[certificates] Generated etcd/server certificate and key.
[certificates] etcd/server serving cert is signed for DNS names [k8smaster localhost] and IPs [127.0.0.1 ::1]
[certificates] Generated etcd/peer certificate and key.
[certificates] etcd/peer serving cert is signed for DNS names [k8smaster localhost] and IPs [192.168.5.36 127.0.0.1 ::1]
[certificates] Generated etcd/healthcheck-client certificate and key.
[certificates] Generated apiserver-etcd-client certificate and key.
[certificates] valid certificates and keys now exist in "/etc/kubernetes/pki"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/admin.conf"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/kubelet.conf"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/controller-manager.conf"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/scheduler.conf"
[controlplane] wrote Static Pod manifest for component kube-apiserver to "/etc/kubernetes/manifests/kube-apiserver.yaml"
[controlplane] wrote Static Pod manifest for component kube-controller-manager to "/etc/kubernetes/manifests/kube-controller-manager.yaml"
[controlplane] wrote Static Pod manifest for component kube-scheduler to "/etc/kubernetes/manifests/kube-scheduler.yaml"
[etcd] Wrote Static Pod manifest for a local etcd instance to "/etc/kubernetes/manifests/etcd.yaml"
[init] waiting for the kubelet to boot up the control plane as Static Pods from directory "/etc/kubernetes/manifests"
[init] this might take a minute or longer if the control plane images have to be pulled
[apiclient] All control plane components are healthy after 45.006897 seconds
[uploadconfig] storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.11" in namespace kube-system with the configuration for the kubelets in the cluster
[markmaster] Marking the node k8smaster as master by adding the label "node-role.kubernetes.io/master=''"
[markmaster] Marking the node k8smaster as master by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[patchnode] Uploading the CRI Socket information "/var/run/dockershim.sock" to the Node API object "k8smaster" as an annotation
[bootstraptoken] using token: qllqye.gtntiz8icyg7fakc
[bootstraptoken] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstraptoken] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstraptoken] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstraptoken] creating the "cluster-info" ConfigMap in the "kube-public" namespace
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes master has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of machines by running the following on each node
as root:
kubeadm join 192.168.5.36:6443 --token qllqye.gtntiz8icyg7fakc --discovery-token-ca-cert-hash sha256:4b3d0159ad8d64c290e9b3d7203034dce43fd8575e7650c6f61d689a177e74a9
说明:默认情况下,通过 kubeadm create token 创建的 token ,过期时间是24小时,这就是为什么过了一天无法再次使用上面记录的kubeadm join命令的愿意,也可以运行 kubeadm token create --ttl 0生成一个永不过期的 token,详情请参考:kubeadm-token(https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm-token/)
看到以上信息表示Master节点已经初始化成功了。按照上面的提示,执行下面的命令。
[root@k8smaster ~]# mkdir -p $HOME/.kube
[root@k8smaster ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@k8smaster ~]# chown $(id -u):$(id -g) $HOME/.kube/config
以上3行的作用:指定kubectl的配置文件,以用来连接apiserver。指定配置文件的几种方式:
- 命令行参数:kubectl –kubeconfig /etc/kubernetes/admin.conf
- 环境变量:export KUBECONFIG=/etc/kubernetes/admin.conf
- 默认位置:$HOME/.kube/config
The loading order follows these rules:
1. If the --kubeconfig flag is set, then only that file is loaded. The flag may only be set once and no erging takes place.
2. If $KUBECONFIG environment variable is set, then it is used a list of paths (normal path delimitting rules for your system). These paths are merged. When a value is modified, it is modified in the file that defines the stanza. When a value is created, it is created in the first file that exists. If no files in the chain exist, then it creates the last file in the list.
3. Otherwise, ${HOME}/.kube/config is used and no merging takes place.
[root@k8smaster ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8smaster NotReady master 2m v1.11.2
[root@k8smaster ~]# kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-78fcdf6894-9b8fn 0/1 Pending 0 2m
kube-system coredns-78fcdf6894-xq69l 0/1 Pending 0 2m
kube-system etcd-k8smaster 1/1 Running 0 1m
kube-system kube-apiserver-k8smaster 1/1 Running 0 1m
kube-system kube-controller-manager-k8smaster 1/1 Running 0 1m
kube-system kube-proxy-pgrc2 1/1 Running 0 2m
kube-system kube-scheduler-k8smaster 1/1 Running 0 1m
可以看到节点还没有Ready,dns的两个pod也没不正常,这是因为还需要安装网络配置。
**集群pod网络安装: **
如果要让k8s集群内的pod进行通信,我们必须安装一个pod网络附件(add-on)。否则集群内的一些组件无法工作,例如CoreDNS的工作就依赖于网络组件。k8s网络解决方案有很多,但是每个k8s集群只能使用一种网络组件。我们此处使用flannel作为网络解决方案,flannel可以加入到一个已经存在的k8s集群中,即使集群中的pod已经运行。
以下命令只需在master上执行即可,因为node节点在加入集群时会自动以pod的形式运行网络组件:
[root@k8smaster ~]# cat /proc/sys/net/bridge/bridge-nf-call-iptables
1
[root@k8smaster ~]# cat /proc/sys/net/bridge/bridge-nf-call-ip6tables
1
#如果以上值不为1,运行sysctl net.bridge.bridge-nf-call-iptables=1;sysctl net.bridge.bridge-nf-call-ip6tables=1命令进行设置。此设置会将桥接的网络流量传递给iptables的链上。
[root@k8smaster ~]# kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
#建议下载下来后启用Directrouting后再apply。
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan",
"Directrouting": true
}
}
[root@k8smaster ~]# kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-78fcdf6894-9b8fn 1/1 Running 0 3m
kube-system coredns-78fcdf6894-xq69l 1/1 Running 0 3m
kube-system etcd-k8smaster 1/1 Running 0 2m
kube-system kube-apiserver-k8smaster 1/1 Running 0 2m
kube-system kube-controller-manager-k8smaster 1/1 Running 0 2m
kube-system kube-flannel-ds-amd64-h2zzs 1/1 Running 0 15s
kube-system kube-proxy-pgrc2 1/1 Running 0 3m
kube-system kube-scheduler-k8smaster 1/1 Running 0 2m
使用kubectl get pods –all-namespaces命令查看CoreDNS的pod是否running。如果显示running,则可以进行下面的向集群中加入Node工作。
Node节点的加入集群前,首先要确保docker-ce、kubeadm、kubelet安装完毕,然后下载镜像。
kubernetes_version=1.11.1
images=(flannel:v0.10.0-amd64)
for i in $(kubeadm config images list --kubernetes-version=${kubernetes_version}); do
if [[ ${i##*/pause} != ${i} ]]; then
images+=(${i##*/})
elif [[ ${i##*/kube-proxy} != ${i} ]]; then
images+=(${i##*/})
fi
done
# images=(kube-proxy-amd64:v1.11.1 pause:3.1 flannel:v0.10.0-amd64)
for imageName in ${images[@]} ; do
if [[ ${imageName##pause} != ${imageName} ]]; then #对pause镜像特殊处理
docker pull registry.cn-hangzhou.aliyuncs.com/ljzsdut/pause-amd64:${imageName##*:}
docker tag registry.cn-hangzhou.aliyuncs.com/ljzsdut/pause-amd64:${imageName##*:} k8s.gcr.io/pause:${imageName##*:}
docker rmi registry.cn-hangzhou.aliyuncs.com/ljzsdut/pause-amd64:${imageName##*:}
else
docker pull registry.cn-hangzhou.aliyuncs.com/ljzsdut/$imageName
docker tag registry.cn-hangzhou.aliyuncs.com/ljzsdut/$imageName k8s.gcr.io/$imageName
docker rmi registry.cn-hangzhou.aliyuncs.com/ljzsdut/$imageName
fi
done
建议启用ipvs,代替iptables(装入内核模块):
模块无需全部装入,可以按需装入,主要有ip_vs, ip_vs_rr, ip_vs_wrr, ip_vs_sh, nf_conntrack_ipv4
cat > /etc/sysconfig/modules/ipvs.modules <<"EOF"
#!/bin/bash
ipvs_modules="ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_fo ip_vs_nq ip_vs_sed ip_vs_ftp nf_conntrack_ipv4"
for kernel_module in ${ipvs_modules}; do
/sbin/modinfo -F filename ${kernel_module} > /dev/null 2>&1
if [ $? -eq 0 ]; then
/sbin/modprobe ${kernel_module}
fi
done
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep ip_vs
最后再根据Master节点的提示加入集群。以下命令会以pod的方式启动kube-proxy:
[root@k8snode01 ~]# kubeadm join 192.168.5.36:6443 --token qllqye.gtntiz8icyg7fakc --discovery-token-ca-cert-hash sha256:4b3d0159ad8d64c290e9b3d7203034dce43fd8575e7650c6f61d689a177e74a9
[preflight] running pre-flight checks
[WARNING RequiredIPVSKernelModulesAvailable]: the IPVS proxier will not be used, because the following required kernel modules are not loaded: [ip_vs ip_vs_rr ip_vs_wrr ip_vs_sh] or no builtin kernel ipvs support: map[ip_vs_rr:{} ip_vs_wrr:{} ip_vs_sh:{} nf_conntrack_ipv4:{} ip_vs:{}]
you can solve this problem with following methods:
1. Run 'modprobe -- ' to load missing kernel modules;
2. Provide the missing builtin kernel ipvs support
I0727 17:36:46.483023 9755 kernel_validator.go:81] Validating kernel version
I0727 17:36:46.483615 9755 kernel_validator.go:96] Validating kernel config
[WARNING SystemVerification]: docker version is greater than the most recently validated version. Docker version: 18.06.0-ce. Max validated version: 17.03
[discovery] Trying to connect to API Server "192.168.5.36:6443"
[discovery] Created cluster-info discovery client, requesting info from "https://192.168.5.36:6443"
[discovery] Requesting info from "https://192.168.5.36:6443" again to validate TLS against the pinned public key
[discovery] Cluster info signature and contents are valid and TLS certificate validates against pinned roots, will use API Server "192.168.5.36:6443"
[discovery] Successfully established connection with API Server "192.168.5.36:6443"
[kubelet] Downloading configuration for the kubelet from the "kubelet-config-1.11" ConfigMap in the kube-system namespace
[kubelet] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[preflight] Activating the kubelet service
[tlsbootstrap] Waiting for the kubelet to perform the TLS Bootstrap...
[patchnode] Uploading the CRI Socket information "/var/run/dockershim.sock" to the Node API object "k8snode01" as an annotation
This node has joined the cluster:
* Certificate signing request was sent to master and a response
was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the master to see this node join the cluster.
[root@k8snode02 ~]# kubeadm join 192.168.5.36:6443 --token qllqye.gtntiz8icyg7fakc --discovery-token-ca-cert-hash sha256:4b3d0159ad8d64c290e9b3d7203034dce43fd8575e7650c6f61d689a177e74a9
...省略输出...
节点的启动也需要一点时间,稍后再到Master上查看状态。
[root@k8smaster ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8smaster Ready master 5m v1.11.2
k8snode01 Ready <none> 38s v1.11.2
k8snode02 Ready <none> 30s v1.11.2
(可选设置)在node节点上使用kubectl,做如下配置:
scp root@k8smaster:/etc/kubernetes/admin.conf .
kubectl --kubeconfig ./admin.conf get nodes