1.2 K8s部署之kubeadm高可用
Kubernetes具有自愈能力,它跟踪到某工作节点发生故障时,控制平面可以将离线节点上的Pod对象重新编排至其它可用工作节点运行,因此,更多的工作节点也意味着更好的容错能力,因为它使得Kubernetes在实现工作节点故障转移时拥有更加灵活的自由度。而当管理员检测到集群负载过重或无法容纳其更多的Pod对象时,通常需要手动将节点添加到群集,其过程略繁琐,Kubernetes cluster-autoscaler还为集群提供了规模按需自动缩放的能力。
然而,添加更多工作节点并不能使群集适应各种故障,例如,若主API服务器出现故障(由于其主机出现故障或网络分区将其从集群中隔离),将无法再跟踪和控制集群。因此,还需要冗余控制平面的各组件以实现主节点的服务高可用性。基于冗余数量的不同,控制平面能容忍一个甚至是几个节点的故障。一般来说,高可用控制平面至少需要三个Master节点来承受最多一个Master节点的丢失,才能保证等待状态的Master能保持半数以上以满足节点选举时的法定票数。一个最小化的Master节点高可用架构如下图所示。
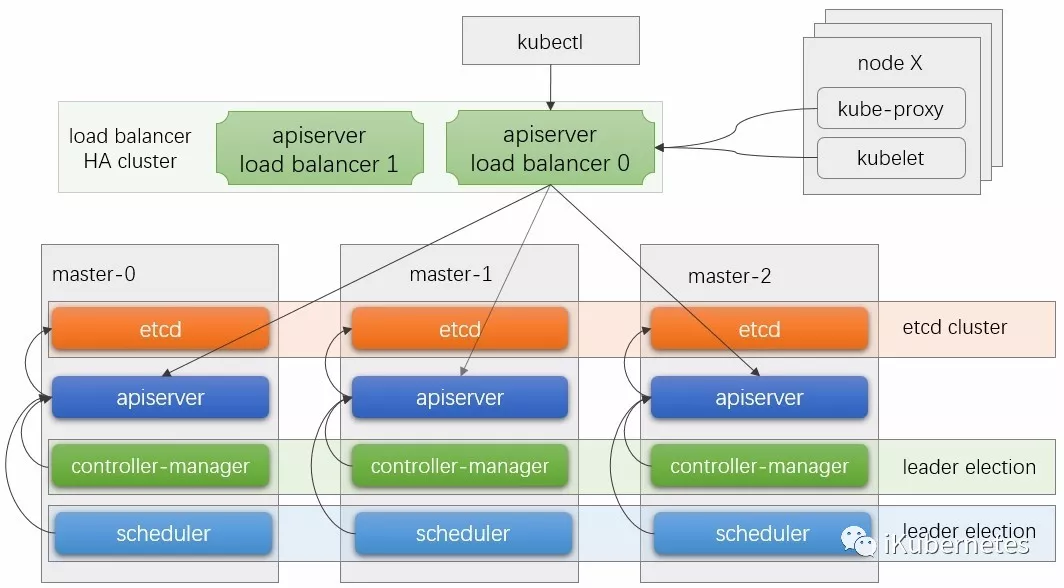
Kubernetes组件中仅etcd需要复杂逻辑完成集群功能,其它组件间的松耦合特性使得能够通过多种方式实现Master节点的高可用性,上图是较为常用的一种架构,各架构方式也通常有一些共同的指导方针:
(1)利用etcd自身提供的分布式存储集群为kubernetes构建一个可靠的存储层;
(2)将无状态的apiserver运行为多副本(本质就是http服务器),并在其前端使用负载均衡器(或DNS)调度请求;需要注意的是,负载均衡器本身也需要高可用;可以使用Haproxy/Nginx+keepalived实现。
(3)多副本的控制器管理器,并通过其自带的leader选举功能(–leader-election)选举出主角色,余下的副本在主角色故障时自动启动新一轮的选举操作;该功能默认开启。
(4)多副本的调度器,并通过其自带的leader选举功能(–leader-election)选举出主角色,余下的副本在主角色故障时自动启动新一轮的选举操作;该功能默认开启。
controller-manager、scheduler选举方法:
它们选举leader的方式是抢占式选举:各node间无需相互通信,各个node通过竞赛的方式去api-server上注册一个EndPoint对象,当有一个注册后其他node就无法注册只能等待重新抢占的机会,当某个node注册成功后,他就持有这个ep对象也就是成为了Leader。而且Leader在持有ep期间,需要定期去更新这个EndPoint的时间戳,如果3个周期没有更新,则认为当前Leader挂掉,其他的node则开始新一轮的抢占选举。后面有详细介绍。
分布式服务之间进行可靠、高效协作的关键前提是有一个可信的数据存储和共享机制,etcd项目正是致力于此目的构建的分布式数据存储系统,它以键值格式组织数据,主要用于配置共享和服务发现,也支持实现分布式锁、集群监控和leader选举等功能。
etcd基于Go语言开发,内部采用raft协议作为共识算法进行分布式协作,通过将数据同步存储在多个独立的服务实例上从而提高数据的可靠性(数据多副本),避免了单点故障导致数据丢失。**Raft协议通过选举出的leader节点实现数据一致性,由leader节点负责所有的写入请求并同步给集群中的所有节点,在取决半数以上follower节点的确认后予以持久存储。**这种需要半数以上节点投票的机制要求集群数量最好是奇数个节点,推荐的数量为3个、5个或7个。Etcd集群的建立有三种方式:
(1)静态集群:事先规划并提供所有节点的固定IP地址以组建集群,仅适合于能够为节点分配静态IP地址的网络环境,好处是它不依赖于任何外部服务;
(2)基于etcd发现服务构建集群:通过一个事先存在的etcd集群进行服务发现来组建新集群,支持集群的动态构建,它依赖于一个现存可用的etcd服务;
(3)基于DNS的服务资源记录构建集群:通过在DNS服务上的某域名下为每个节点创建一条SRV记录,而后基于此域名进行服务发现来动态组建新集群,它依赖于DNS服务及事先管理妥当的资源记录;
一般说来,对于etcd分布式存储集群来说,三节点集群可容错一个节点,五节点集群可容错两个节点,七节点集群可容错三个节点,依次类推,但通常多于七个节点的集群规模是不必要的,而且对系统性能也会产生负面影响。
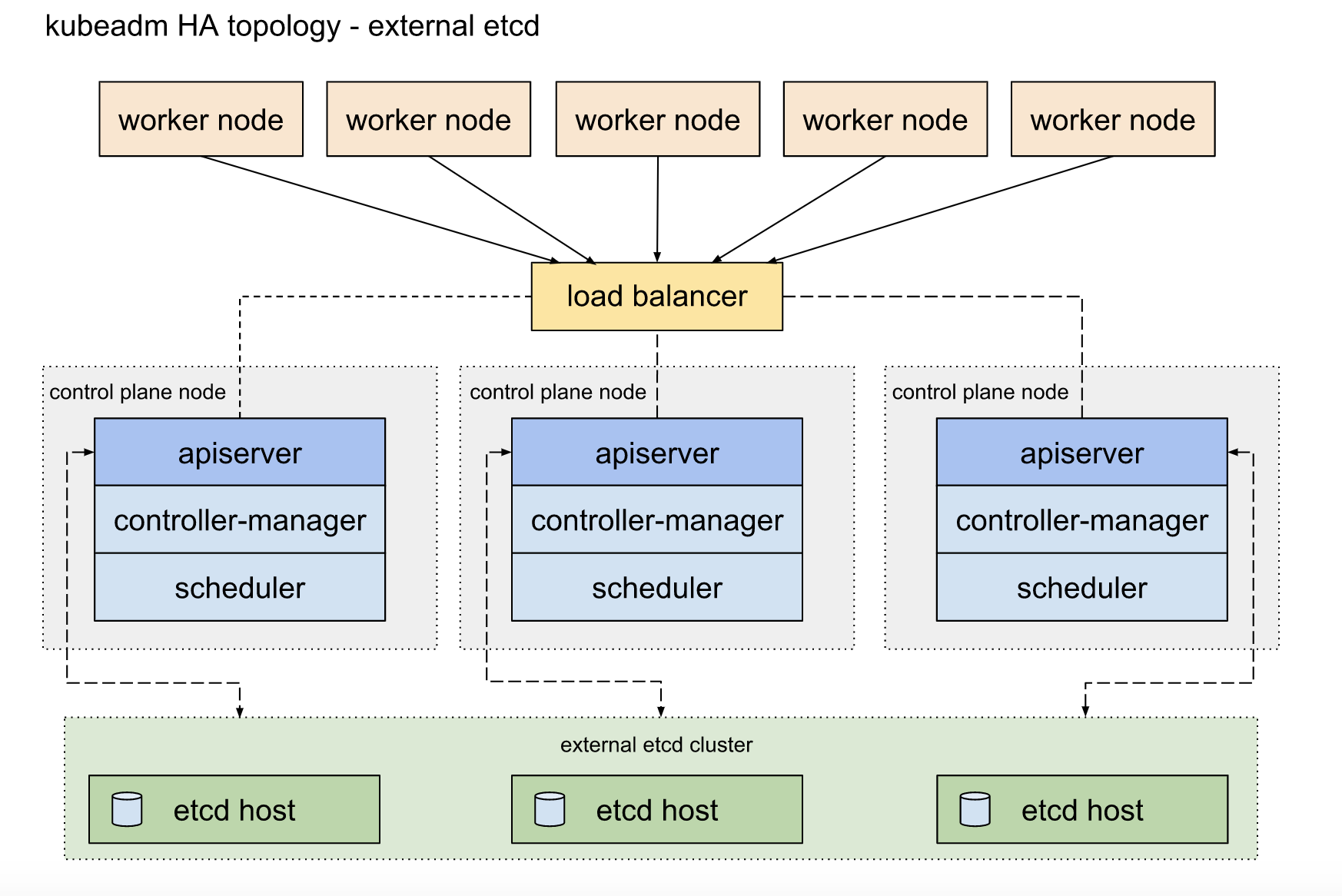
apiserver本质上就是一个http服务器,本身是无状态的,他们的状态数据保存在etcd中。这种无状态的应用实现高可用是十分简单的,只需将无状态的apiserver运行为多副本,并在其前端使用负载均衡器调度请求(或DNS调度);需要注意的是,负载均衡器本身也需要高可用;可以使用Haproxy/Nginx+keepalived实现。
Controller Manager通过监控API server上的资源状态变动并按需分别执行相应的操作,于是,多实例运行的kube-controller-manager进程可能会导致同一操作行为被每一个实例分别执行一次,例如某一Pod对象创建的请求被3个控制器实例分别执行一次进而创建出一个Pod对象副本来。因此,在某一时刻,仅能有一个kube-controller-manager实例正常工作状态,余下的均处于备用状态,或称为等待状态。
多个kube-controller-manager实例要同时启用“--leader-elect=true”选项以自动实现leader选举,选举过程完成后,仅leader实例处于活动状态,余下的其它实例均转入等待模式,它们会在探测到leader故障时进行新一轮选举。与etcd集群基于raft协议进行leader选举不同的是,kube-controller-manager集群各自的选举操作仅是通过在kube-system名称空间中创建一个与程序同名的Endpoint资源对象实现。
~]$ kubectl get endpoints -n kube-system
NAME ENDPOINTS AGE
kube-controller-manager <none> 13h
kube-scheduler <none> 13h
…
这种leader选举操作是分布式锁机制的一种应用,它通过创建和维护kubernetes资源对象来维护锁状态,目前kubernetes支持ConfigMap和Endpoints两种类型的资源锁。初始状态时,各kube-controller-manager实例通过竞争方式去抢占指定的Endpoint资源锁。胜利者将成为leader,它通过更新相应的Endpoint资源的注解control-plane.alpha.kubernetes.io/leader中的“holderIdentity”为其节点名称从而将自己设置为锁的持有者,并基于周期性更新同一注解中的“renewTime”以声明自己对锁资源的持有状态以避免等待状态的实例进行争抢。于是,一旦某leader不再更新renewTime(例如3个周期内都未更新),等待状态的各实例将一哄而上进行新一轮竞争。
~]$ kubectl describe endpoints kube-controller-manager -n kube-system
Name: kube-controller-manager
Namespace: kube-system
Labels: <none>
Annotations: control-plane.alpha.kubernetes.io/leader={"holderIdentity":"master1.ilinux.io_846a3ce4-b0b2-11e8-9a23-00505628fa03","leaseDurationSeconds":15,"acquireTime":"2018-09-05T02:22:54Z","renewTime":"2018-09-05T02:40:55Z","leaderTransitions":1}'
Subsets:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal LeaderElection 13h kube-controller-manager master0.ilinux.io_e8fca6fc-b049-11e8-a247-000c29ab0f5b became leader
Normal LeaderElection 5m kube-controller-manager master1.ilinux.io_846a3ce4-b0b2-11e8-9a23-00505628fa03 became leader
kube-scheduler的实现方式与此类似,只不过它使用自己专用的Endpoint资源kube-scheduler。
参考文档:多Master的k8s安装
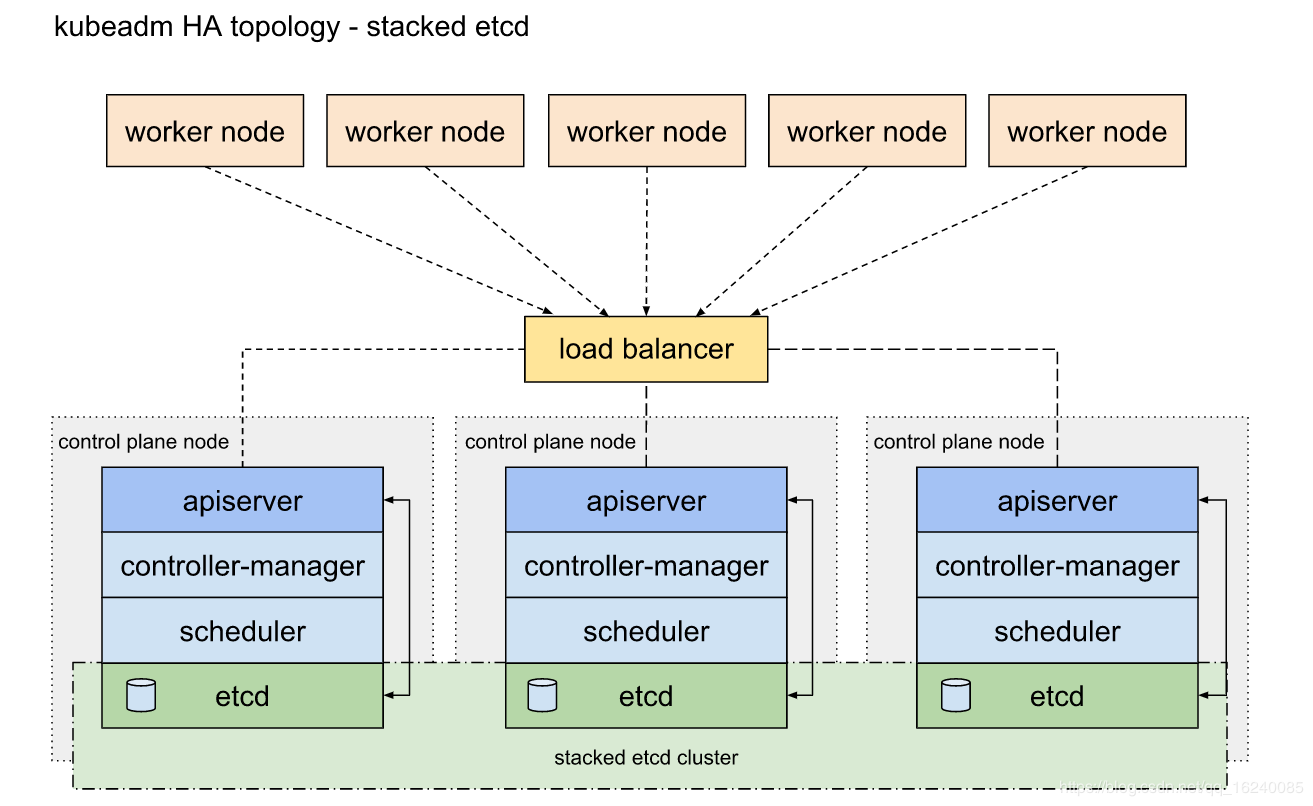
- 前提工作:
Master+Node:安装docker+kubelet,此外还需要安装kubeadm和kubectl(kubectl并非必须)。docker提供容器运行时环境;kubelet在Node节点上运行工作负载Pod,并且在master节点上用来运行apiserver等静态Pod,当然如果允许master节点接收工作负载,也可以运行工作负载Pod。
- 初始化master:
将api-server、controller-manager、scheduler、etcd四个组件通过kubelet以静态pod模式运行(staic pod),manifest文件默认位于/etc/kubernetes/manifests。
- node:
将kube-proxy组件通过kubelet以pod模式运行(其实kube-procy和CoreDNS都是在kubeadm init阶段以DaemonSet形式运行的)
- Master+Node:
安装flanel插件(只需要在Master上手动安装,node上会自动触发安装,因为flannel是以DaemonSet方式运行的)
- 使用kubeadm安装k8s集群,因为Master和Node节点都是使用pod运行的各个组件,所以每个节点包括Master和Node都需要安装docker-ce和kubelet两个组件,而且Master和Node节点初始化时都要使用kubeadm命令,此外如果要在某个节点上使用命令行工具kubectl,还要在该节点上安装kubectl工具,所以一般我们会在所有节点上安装4个rpm包:docker-ce、kubelet、kubeadm、kubectl。
- Master节点运行kubeadm init命令时,通过kubectl工具会将api-server、controller-manager、scheduler、etcd四个组件以static pod的方式运行(自己拉取镜像),此外还会在Master上安装kube-proxy和CoreDNS(同样会以pod的方式运行,但不是以static方式运行)。Master节点上也需要kubelet组件来运行pod,但是kubelet是以daemon模式运行。
- Master节点初始化后,各pod之间还不能通信,例如CoreDNS不能进入running状态,需要我们单独安装pod network组件,例如flannel、calico等,当然这些add-on也是以pod的方式运行。
- Node节点使用kubeadm join命令加入到k8s集群中。运行此命令后,Node节点会自己拉取相关镜像以pod的方式运行kube-proxy和flannel等pod network组件。(Node节点上的kubelet是以daemon模式运行)
准备工作需要在所有的节点进行。
cat >/etc/hosts <<EOF
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.6.121 k8s-master01 k8s-master01.ljzsdut.com
192.168.6.122 k8s-master02 k8s-master02.ljzsdut.com
192.168.6.123 k8s-master03 k8s-master03.ljzsdut.com
192.168.6.124 k8s-node01 k8s-node01.ljzsdut.com
192.168.6.125 k8s-node02 k8s-node01.ljzsdut.com
192.168.6.126 k8s-node03 k8s-node01.ljzsdut.com
EOF
systemctl stop firewalld ; systemctl disable firewalld ; setenforce 0 ; sed -i "s/^SELINUX=enforcing/SELINUX=disabled/g" /etc/sysconfig/selinux /etc/selinux/config
swapoff -a ; sed -i 's/.*swap.*/#&/' /etc/fstab
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv6.conf.all.disable_ipv6=1
net.ipv4.ip_forward=1 #开启内核转发
net.ipv4.tcp_tw_recycle=0 #NAT环境中建议关闭
vm.swappiness=0 #禁止使用swap空间,只有当系统发生OOM是才允许使用
vm.overcommit_memory=1 #内存分配策略:不检查物理内存是否够用
vm.panic_on_oom=0 #0表示开启OOM,杀死某些进程,而不是进行kernel pannic
fs.inotify.max_user_instances=8192
fs.inotify.max_user_watches=1048576
fs.file-max=52706963
fs.nr_open=52706963
net.netfilter.nf_conntrack_max=2310720 # 最大跟踪连接数
EOF
sysctl --system
rpm -qa |grep chrony &>/dev/null || yum install -y chrony
sed -i '2a server ntp1.aliyun.com iburst' /etc/chrony.conf
systemctl restart chronyd
systemctl enable chronyd
#关闭系统不需要的服务(可选)
systemctl stop postfix
systemctl disable postfix
#Centos7自带的3.10.x内核存在一些bug,导致docker、kubernetes不稳定。建议升级内核到4.4。
#参考文档:http://elrepo.org/tiki/tiki-index.php
#参考文档:https://blog.csdn.net/kikajack/article/details/79396793
#1、导入公钥
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
#2、安装elrepo内核软件源
yum install -y https://www.elrepo.org/elrepo-release-7.0-4.el7.elrepo.noarch.rpm
#3、查看可用的内核包
yum --disablerepo="*" --enablerepo="elrepo-kernel" list available
#4、安装长期支持版本
yum --enablerepo=elrepo-kernel install -y kernel-lt
#设置grub,开机从新内核启动:内核安装好后,需要设置为默认启动选项并重启后才会生效
#1、通过 gurb2-mkconfig 命令创建 grub2 的配置文件
grub2-mkconfig -o /boot/grub2/grub.cfg
#2、查看系统上的所有可以内核:
awk -F\' '$1=="menuentry " {print i++ " : " $2}' /etc/grub2.cfg
0 : CentOS Linux (4.4.202-1.el7.elrepo.x86_64) 7 (Core)
1 : CentOS Linux (3.10.0-862.11.6.el7.x86_64) 7 (Core)
2 : CentOS Linux (3.10.0-514.el7.x86_64) 7 (Core)
3 : CentOS Linux (0-rescue-f58eebd168fc4ff3809f5af6bf26ada0) 7 (Core)
#3、设置上面的0号内核为默认使用内核,然后重启
grub2-set-default 0
reboot
模块无需全部装入,可以按需装入,主要有ip_vs, ip_vs_rr, ip_vs_wrr, ip_vs_sh, nf_conntrack_ipv4
yum install -y ipvsadm #ipvs的管理工具,可选
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
ipvs_modules="ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_fo ip_vs_nq ip_vs_sed ip_vs_ftp nf_conntrack_ipv4"
for kernel_module in \${ipvs_modules}; do
/sbin/modinfo -F filename \${kernel_module} > /dev/null 2>&1
if [ $? -eq 0 ]; then
/sbin/modprobe \${kernel_module}
fi
done
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
从kubernetes1.8版本开始,新增了kube-proxy对ipvs的支持,并且在新版的kubernetes1.11版本中被纳入了GA。iptables模式问题不好定位,规则多了性能会显著下降,甚至会出现规则丢失的情况;相比而言,ipvs就稳定的多。
**在安装完k8s后,再进行启用ipvs的操作:**请查看:五.1《kube-proxy启用ipvs》
参考文档:kube-proxy开启ipvs代替iptables
# docker阿里云源
curl -o /etc/yum.repos.d/docker-ce.repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
### Install required packages for docker.
yum install -y device-mapper-persistent-data lvm2
yum install -y docker-ce-19.03.8
## Create /etc/docker directory.
mkdir /etc/docker
# Setup daemon.
cat > /etc/docker/daemon.json <<EOF
{
"graph": "/u01/install/docker",
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m",
"max-file": "3"
},
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
],
"registry-mirrors": ["https://lqetgo1f.mirror.aliyuncs.com","https://docker.mirrors.ustc.edu.cn/"],
"insecure-registries" : ["https://harbor.ljzsdut.com"]
}
EOF
mkdir -p /etc/systemd/system/docker.service.d
# Restart Docker
systemctl daemon-reload
systemctl restart docker
systemctl enable docker
# kubernetes阿里云源
cat <<-EOF >/etc/yum.repos.d/kubernets.repo
[Kubernetes]
name=kubernetes repo
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
enabled=1
EOF
#安装kubeadm kubelet软件,为了保证与老节点的版本一致,我们可以指定安装版本
KUBE_VERSION=1.18.2
yum install -y kubeadm-${KUBE_VERSION} kubelet-${KUBE_VERSION} kubectl-${KUBE_VERSION} ipvsadm #kubectl、ipvsadm可选
# start kubelet
systemctl enable kubelet
systemctl start kubelet
systemctl status kubelet
此时的kubelet处于每隔10秒重启一次的状态,这种崩溃循环是正常的,kubelet在这个崩溃循环中等待kubeadm告诉它该怎么做。kubeadm通过生成/var/lib/kubelet/config.yaml配置文件来告诉kubelet需要干什么。
“max-file”: “3” #每个容器中日志数量,分别是id+.json、id+1.json、id+2.json
bash
yum install -y bash-completion #会生成一个文件/usr/share/bash-completion/bash_completion
source /usr/share/bash-completion/bash_completion
echo 'source <(kubectl completion bash)' >>/etc/profile && source /etc/profile
Zsh
自动补全的脚步可以通过 kubectl completion zsh 查看。下面是配置步骤:
在 ~/.zshrc 文件中添加
source <(kubectl completion zsh)
如果出现 complete:13: command not found: compdef 之类的错误,就在 ~/.zshrc 文件开头添加
autoload -Uz compinit
compinit
部署负载均衡
此处我们采用haproxy+keepalived组合,当然也可以使用nginx+keepalived组合
监听8443,后端为6443
yum install -y haproxy
#修改配置文件如下
K8S_MASTER_01=192.168.6.121@@@k8s-master01
K8S_MASTER_02=192.168.6.122@@@k8s-master02
K8S_MASTER_03=192.168.6.123@@@k8s-master03
VIP=192.168.6.120
LOAD_BALANCER_PORT=6443
OTHER_MASTERS=()
for host in ${!K8S_MASTER_@};do
if ip a |grep ${!host//@@@*} &>/dev/null;then
LOCAL_IP=${!host//@@@*}
HostName=${!host##*@@@}
else
OTHER_MASTERS+=(${!host//@@@*})
fi
done
cat >/etc/haproxy/haproxy.cfg <<EOF
global
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
stats socket /run/haproxy.sock mode 660 level admin
stats timeout 30s
user haproxy
group haproxy
daemon
nbproc 1
defaults
log global
timeout connect 5000
timeout client 10m
timeout server 10m
listen kube-master
bind 0.0.0.0:8443
mode tcp
option tcplog
balance roundrobin
EOF
#修改配置
for host in ${!K8S_MASTER_@} ;do
sed -i '/balance roundrobin/a\ server '${!host##*@@@}\ ${!host//@@@*}':6443 check inter 2000 fall 2 rise 2 weight 1' /etc/haproxy/haproxy.cfg
done
#启动
systemctl enable haproxy
systemctl restart haproxy
systemctl status haproxy -l
yum install -y psmisc #安装killall命令
yum install -y keepalived
#修改配置文件
cat >/etc/keepalived/keepalived.conf <<EOF
global_defs {
router_id kube-master
}
vrrp_script check-haproxy {
script "killall -0 haproxy"
interval 5
weight -60
}
vrrp_instance VI-kube-master {
state MASTER #BACKUP或者为MASTER
priority 120 #不同节点的差值在60之内,因为"weight -60"
unicast_src_ip ${LOCAL_IP} #当前节点ip
unicast_peer { #其他节点ip列表,每行一个
}
dont_track_primary
interface eth0 #指定网卡
virtual_router_id 111 #同一个集群中,该值要相同,表示一个广播组
advert_int 3
track_script {
check-haproxy
}
virtual_ipaddress {
${VIP} #指定VIP
}
}
EOF
#以上配置需要根据不同节点进行设置
for i in ${OTHER_MASTERS[@]};do
sed -i '/unicast_peer {/a\ '$i'' /etc/keepalived/keepalived.conf
done
num=0
for host in ${!K8S_MASTER_@} ;do
if ip a |grep ${!host//@@@*} &>/dev/null;then
sed -i 's/priority 120/priority '$[120-${num}*5]'/g' /etc/keepalived/keepalived.conf
sed -i 's/state MASTER/state BACKUP/g' /etc/keepalived/keepalived.conf
fi
num=$[num+1]
done
#启动
systemctl enable keepalived
systemctl restart keepalived
systemctl status keepalived -l
在执行初始化之前,我们还有一下几点需要注意:
1.选择一个网络插件,并检查它是否需要在初始化Master时指定一些参数,比如我们可能需要根据选择的插件来设置--pod-network-cidr参数。参考:Installing a pod network add-on。
2.kubeadm使用eth0的默认网络接口(通常是内网IP)做为Master节点的advertise address,如果我们想使用不同的网络接口,可以使用--apiserver-advertise-address=<ip-address>参数来设置。如果适应IPv6,则必须使用IPv6d的地址,如:--apiserver-advertise-address=fd00::101。
3.使用kubeadm config images pull来预先拉取初始化需要用到的镜像,用来检查是否能连接到Kubenetes的Registries。Kubenetes默认Registries地址是k8s.gcr.io,很明显,在国内并不能访问gcr.io,因此在kubeadm v1.13之前的版本,安装起来非常麻烦,但是在1.13版本中终于解决了国内的痛点,其增加了一个--image-repository参数,默认值是k8s.gcr.io,我们将其指定为国内镜像地址:registry.aliyuncs.com/google_containers,其它的就可以完全按照官方文档来愉快的玩耍了。
其次,我们还需要指定--kubernetes-version参数,因为它的默认值是stable-1,会导致从https://dl.k8s.io/release/stable-1.txt下载最新的版本号,我们可以将其指定为固定版本(最新版:v1.16.2)来跳过网络请求。
# 使用calico网络 --pod-network-cidr=192.168.0.0/16
# 使用flannel网络 --pod-network-cidr=10.244.0.0/16
sudo kubeadm init --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.16.2 --pod-network-cidr=10.244.0.0/16 --dry-run
4.查看InitConfiguration文件
# 我们也可以修改默认的InitConfiguration文件,使用一下命令自动生成:
# kubeadm config print init-defaults
apiVersion: kubeadm.k8s.io/v1beta2
kind: ClusterConfiguration
kubernetesVersion: v1.16.2 #指定--kubernetes-version v1.16.2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: 192.168.6.120:6443 #指定--control-plane-endpoint
imageRepository: registry.aliyuncs.com/google_containers #指定--image-repository
controllerManager: {}
apiServer:
extraArgs:
authorization-mode: Node,RBAC
timeoutForControlPlane: 4m0s
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
networking:
dnsDomain: cluster.local
podSubnet: 10.244.0.0/16 #指定--pod-network-cidr=10.244.0.0/16
serviceSubnet: 10.96.0.0/12
scheduler: {}
kubeProxy:
config:
featureGates:
SupportIPVSProxyMode: true #启用ipvs模式
mode: ipvs
# 查看已安装的k8s的初始化配置文件
# kubeadm config view
参考文档:
kubeadm init首先会进行一系列的预检查,然后下载并安装集群组件。常用参数:kubeadm init –help查看
–kubernetes-version=v1.11[.1] 指定k8s版本
–pod-network-cidr=10.244.0.0/16 指定pod使用的网络,该值与network组件有关,不同的组件使用不同的值。参考pod网络
–service-cidr=10.96.0.0/12 指定service使用的网络,默认为"10.96.0.0/12"
--apiserver-advertise-address=192.168.5.36 指定本机apiserver监听地址,默认为0.0.0.0 --apiserver-bind-port=6443 指定本机apiserver监听端口,默认6443–control-plane-endpoint 指定控制平面的负载均衡地址
–upload-certs 将证书等创建为k8s的secret,2小时后自动删除,可是使用
kubeadm init phase upload-certs --upload-certs重新创建。–image-repository 指定镜像仓库
[root@k8s-master01 ~]# kubeadm init --control-plane-endpoint "${VIP}:${LOAD_BALANCER_PORT}" --upload-certs --image-repository "registry.aliyuncs.com/google_containers" --kubernetes-version v1.16.2 --pod-network-cidr=10.244.0.0/16
[init] Using Kubernetes version: v1.16.2
[preflight] Running pre-flight checks
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 19.03.4. Latest validated version: 18.09
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Activating the kubelet service
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [k8s-master01 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.6.121 192.168.6.120]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [k8s-master01 localhost] and IPs [192.168.6.121 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [k8s-master01 localhost] and IPs [192.168.6.121 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 32.507182 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.16" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Storing the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace
[upload-certs] Using certificate key:
a7365741ee1276fdd39bcbf132ce1334cbb5dbf1ca7f40da3d9ea624f13b3259
[mark-control-plane] Marking the node k8s-master01 as control-plane by adding the label "node-role.kubernetes.io/master=''"
[mark-control-plane] Marking the node k8s-master01 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: 7uu86c.2m3es7nnbc4ox63n
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join 192.168.6.120:6443 --token 7uu86c.2m3es7nnbc4ox63n \
--discovery-token-ca-cert-hash sha256:127278359dbaa6a22b3462ef0d973d919bd2428b6089cc4912dbd20c4828945a \
--control-plane --certificate-key a7365741ee1276fdd39bcbf132ce1334cbb5dbf1ca7f40da3d9ea624f13b3259
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.6.120:6443 --token 7uu86c.2m3es7nnbc4ox63n \
--discovery-token-ca-cert-hash sha256:127278359dbaa6a22b3462ef0d973d919bd2428b6089cc4912dbd20c4828945a
说明:默认情况下,通过"kubeadm create token"创建的token是有限的 ,过期时间是24小时,这就是为什么过了一天无法再次使用上面记录的"kubeadm join"命令的原因,我们可以运行“kubeadm token create --ttl 0”生成一个永不过期的token也可以使用"kubeadm token create --print-join-command"重新创建一条token。使用新token 详情请参考:kubeadm-token(https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm-token/)
看到以上信息表示Master节点已经初始化成功了。按照上面的提示,执行下面的命令。
[root@k8smaster ~]# mkdir -p $HOME/.kube
[root@k8smaster ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@k8smaster ~]# chown $(id -u):$(id -g) $HOME/.kube/config
以上3行的作用:指定kubectl的配置文件,以用来连接apiserver。指定配置文件的几种方式:
- 命令行参数:kubectl –kubeconfig /etc/kubernetes/admin.conf
- 环境变量:export KUBECONFIG=/etc/kubernetes/admin.conf
- 默认位置:$HOME/.kube/config
The loading order follows these rules:
1. If the --kubeconfig flag is set, then only that file is loaded. The flag may only be set once and no erging takes place.
2. If $KUBECONFIG environment variable is set, then it is used a list of paths (normal path delimitting rules for your system). These paths are merged. When a value is modified, it is modified in the file that defines the stanza. When a value is created, it is created in the first file that exists. If no files in the chain exist, then it creates the last file in the list.
3. Otherwise, ${HOME}/.kube/config is used and no merging takes place.
[root@k8smaster ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8smaster NotReady master 2m v1.11.2
[root@k8smaster ~]# kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-78fcdf6894-9b8fn 0/1 Pending 0 2m
kube-system coredns-78fcdf6894-xq69l 0/1 Pending 0 2m
kube-system etcd-k8smaster 1/1 Running 0 1m
kube-system kube-apiserver-k8smaster 1/1 Running 0 1m
kube-system kube-controller-manager-k8smaster 1/1 Running 0 1m
kube-system kube-proxy-pgrc2 1/1 Running 0 2m
kube-system kube-scheduler-k8smaster 1/1 Running 0 1m
可以看到节点还没有Ready,dns的两个pod也没不正常,这是因为还需要安装网络配置。
如果要让k8s集群内的pod进行通信,我们必须安装一个pod网络附件(add-on)。否则集群内的一些组件无法工作,例如CoreDNS的工作就依赖于网络组件。k8s网络解决方案有很多,但是每个k8s集群只能使用一种网络组件。此处我们使用flannel、calico网络作为演示,实际部署过程中,我们二选一部署。
我们此处使用flannel作为网络解决方案,flannel可以加入到一个已经存在的k8s集群中,即使集群中的pod已经运行。
以下命令只需在master上执行即可,因为node节点在加入集群时会自动以pod的形式运行网络组件:
[root@k8smaster ~]# cat /proc/sys/net/bridge/bridge-nf-call-iptables
1
[root@k8smaster ~]# cat /proc/sys/net/bridge/bridge-nf-call-ip6tables
1
#如果以上值不为1,运行sysctl net.bridge.bridge-nf-call-iptables=1;sysctl net.bridge.bridge-nf-call-ip6tables=1命令进行设置。此设置会将桥接的网络流量传递给iptables的链上。
#安装CNI(flannel)
[root@k8s-master01 ~]# curl -O https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
[root@k8s-master01 ~]# sed -i 's/quay.io/quay-mirror.qiniu.com/g' kube-flannel.yml
#建议下载下来后启用Directrouting后再apply。
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan",
"Directrouting": true
}
}
[root@k8s-master01 ~]# kubectl apply -f kube-flannel.yml
[root@k8smaster ~]# kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-78fcdf6894-9b8fn 1/1 Running 0 3m
kube-system coredns-78fcdf6894-xq69l 1/1 Running 0 3m
kube-system etcd-k8smaster 1/1 Running 0 2m
kube-system kube-apiserver-k8smaster 1/1 Running 0 2m
kube-system kube-controller-manager-k8smaster 1/1 Running 0 2m
kube-system kube-flannel-ds-amd64-h2zzs 1/1 Running 0 15s
kube-system kube-proxy-pgrc2 1/1 Running 0 3m
kube-system kube-scheduler-k8smaster 1/1 Running 0 2m
使用kubectl get pods --all-namespaces命令查看CoreDNS的pod是否running。如果显示running,则可以进行下面的向集群中加入Node工作。
以下命令只需在master上执行即可,因为node节点在加入集群时会自动以pod的形式运行网络组件:
[root@k8smaster ~]# cat /proc/sys/net/bridge/bridge-nf-call-iptables
1
[root@k8smaster ~]# cat /proc/sys/net/bridge/bridge-nf-call-ip6tables
1
#如果以上值不为1,运行sysctl net.bridge.bridge-nf-call-iptables=1;sysctl net.bridge.bridge-nf-call-ip6tables=1命令进行设置。此设置会将桥接的网络流量传递给iptables的链上。
[root@172.22.22.7 ~]# kubectl apply -f https://docs.projectcalico.org/v3.14/manifests/calico.yaml
[root@k8smaster ~]# kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-78fcdf6894-9b8fn 1/1 Running 0 3m
kube-system coredns-78fcdf6894-xq69l 1/1 Running 0 3m
kube-system etcd-k8smaster 1/1 Running 0 2m
kube-system kube-apiserver-k8smaster 1/1 Running 0 2m
kube-system kube-controller-manager-k8smaster 1/1 Running 0 2m
kube-system kube-flannel-ds-amd64-h2zzs 1/1 Running 0 15s
kube-system kube-proxy-pgrc2 1/1 Running 0 3m
kube-system kube-scheduler-k8smaster 1/1 Running 0 2m
使用kubectl get pods --all-namespaces命令查看CoreDNS的pod是否running。如果显示running,则可以进行下面的向集群中加入Node工作。
如果calico-node报错:caliconode is not ready: BIRD is not ready: BGP not established with x.x.x.x
解决方法:调整calicao 网络插件的网卡发现机制,修改 IP_AUTODETECTION_METHOD 对应的value值。官方提供的yaml文件中,ip识别策略(IPDETECTMETHOD)没有配置,即默认为first-found,这会导致一个网络异常的ip作为nodeIP被注册,从而影响 node-to-node mesh 。我们可以修改成 can-reach 或者 interface 的策略,尝试连接某一个Ready的node的IP,以此选择出正确的IP。
- can-reach使用您的本地路由来确定将使用哪个IP地址到达提供的目标。可以使用IP地址和域名。
# Using IP addresses IP_AUTODETECTION_METHOD=can-reach=8.8.8.8 IP6_AUTODETECTION_METHOD=can-reach=2001:4860:4860::8888 # Using domain names IP_AUTODETECTION_METHOD=can-reach=www.google.com IP6_AUTODETECTION_METHOD=can-reach=www.google.com
- interface使用提供的接口正则表达式(golang语法)枚举匹配的接口并返回第一个匹配接口上的第一个IP地址。列出接口和IP地址的顺序取决于系统。
# Valid IP address on interface eth0, eth1, eth2 etc. IP_AUTODETECTION_METHOD=interface=eth.* IP6_AUTODETECTION_METHOD=interface=eth.*示例:在calico-node这个DaemonSet中,设置calico-node容器的环境变量。
- name: CALICO_IPV4POOL_CIDR value: "10.244.0.0/16" - name: IP_AUTODETECTION_METHOD #添加该环境变量(注意pod中有多个容器,别加错了) value: "interface=(eth.*|ens.*)"
calico网络参考:
https://blog.csdn.net/ccy19910925/article/details/82423452
https://www.kubernetes.org.cn/4960.html
[root@k8s-master02 ~]# kubeadm join 192.168.6.120:6443 --token 7uu86c.2m3es7nnbc4ox63n \
> --discovery-token-ca-cert-hash sha256:127278359dbaa6a22b3462ef0d973d919bd2428b6089cc4912dbd20c4828945a \
> --control-plane --certificate-key a7365741ee1276fdd39bcbf132ce1334cbb5dbf1ca7f40da3d9ea624f13b3259
[preflight] Running pre-flight checks
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 19.03.4. Latest validated version: 18.09
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[preflight] Running pre-flight checks before initializing the new control plane instance
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[download-certs] Downloading the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [k8s-master02 localhost] and IPs [192.168.6.122 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [k8s-master02 localhost] and IPs [192.168.6.122 127.0.0.1 ::1]
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [k8s-master02 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.6.122 192.168.6.120]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Valid certificates and keys now exist in "/etc/kubernetes/pki"
[certs] Using the existing "sa" key
[kubeconfig] Generating kubeconfig files
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[check-etcd] Checking that the etcd cluster is healthy
[kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.16" ConfigMap in the kube-system namespace
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Activating the kubelet service
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
[etcd] Announced new etcd member joining to the existing etcd cluster
[etcd] Creating static Pod manifest for "etcd"
[etcd] Waiting for the new etcd member to join the cluster. This can take up to 40s
{"level":"warn","ts":"2019-11-11T12:32:07.530+0800","caller":"clientv3/retry_interceptor.go:61","msg":"retrying of unary invoker failed","target":"passthrough:///https://192.168.6.122:2379","attempt":0,"error":"rpc error: code = DeadlineExceeded desc = context deadline exceeded"}
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[mark-control-plane] Marking the node k8s-master02 as control-plane by adding the label "node-role.kubernetes.io/master=''"
[mark-control-plane] Marking the node k8s-master02 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
This node has joined the cluster and a new control plane instance was created:
* Certificate signing request was sent to apiserver and approval was received.
* The Kubelet was informed of the new secure connection details.
* Control plane (master) label and taint were applied to the new node.
* The Kubernetes control plane instances scaled up.
* A new etcd member was added to the local/stacked etcd cluster.
To start administering your cluster from this node, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Run 'kubectl get nodes' to see this node join the cluster.
Node节点的加入集群前,首先要确保docker-ce、kubeadm、kubelet安装完毕。
最后再根据Master节点的提示加入集群。以下命令会以pod的方式启动kube-proxy:
[root@k8s-node01 ~]# kubeadm join 192.168.6.120:6443 --token 7uu86c.2m3es7nnbc4ox63n \
--discovery-token-ca-cert-hash sha256:127278359dbaa6a22b3462ef0d973d919bd2428b6089cc4912dbd20c4828945a
[preflight] Running pre-flight checks
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 19.03.4. Latest validated version: 18.09
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.16" ConfigMap in the kube-system namespace
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Activating the kubelet service
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
[root@k8snode02 ~]# kubeadm join 192.168.6.120:6443 --token 7uu86c.2m3es7nnbc4ox63n \
--discovery-token-ca-cert-hash sha256:127278359dbaa6a22b3462ef0d973d919bd2428b6089cc4912dbd20c4828945a
如果是后期增加节点,kubeadm join命令中使用的toke可能已经过期,需要重新生成token。
节点的启动也需要一点时间,稍后再到Master上查看状态。
[root@k8smaster ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8smaster Ready master 5m v1.11.2
k8snode01 Ready <none> 38s v1.11.2
k8snode02 Ready <none> 30s v1.11.2
(可选设置)在node节点上使用kubectl,做如下配置:
scp root@k8smaster:/etc/kubernetes/admin.conf .
kubectl --kubeconfig ./admin.conf get nodes
1、更改kube-proxy的配置,其配置存储在configmap中。
kubectl edit configmap kube-proxy -n kube-system
找到如下部分的内容
minSyncPeriod: 0s
scheduler: ""
syncPeriod: 30s
kind: KubeProxyConfiguration
metricsBindAddress: 127.0.0.1:10249
mode: "ipvs" # 加上这个,之前是: mode: "" 。默认为iptables模式
nodePortAddresses: null
scheduler默认是空,默认负载均衡算法为轮训。编辑完,保存退出。
3、删除所有kube-proxy的pod
[root@k8s-master01 ~]# kubectl get pod -n kube-system |grep kube-proxy|awk '{print $1}' | xargs kubectl -n kube-system delete pod
4、查看kube-proxy的pod日志
[root@k8s-master01 ~]# kubectl get pod -n kube-system |grep kube-proxy|awk '{print $1}' | head -1 |xargs kubectl -n kube-system logs -f |grep 'Using ipvs Proxier'
I0607 02:54:42.413292 1 server_others.go:259] Using ipvs Proxier.
有.....Using ipvs Proxier......即可。
5、使用ipvsadm查看ipvs相关规则,如果没有这个命令可以直接yum install -y ipvsadm安装
[root@k8s-master01 ~]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 127.0.0.1:30451 rr
-> 10.244.85.245:8080 Masq 1 0 0
TCP 127.0.0.1:30917 rr
-> 10.244.58.212:80 Masq 1 0 0
......
如果k8s组件是pod形式存在,默认使用的是UTC时区,如果要使用中国时区,需要修改/etc/kubernetes/manifests下几个组件的yaml文件,配置这几个k8s组件的pod时区,添加:
volumeMounts:
- name: host-time
mountPath: /etc/localtime
readOnly: true
volumes:
- name: host-time
hostPath:
path: /etc/localtime
https://blog.51cto.com/billy98/2389246
只能从一个MINOR版本升级到下一个MINOR版本,或者在同一个MINOR的PATCH版本之间升级。也就是说,升级时不能跳过MINOR版本。例如,可以从1.y升级到1.y + 1,但不能从1.y升级到1.y + 2。
升级工作流程如下:
- 升级主master节点。
- 升级其他master节点。
- 升级work节点。
1、所有节点更新软件
VERSION=1.18.6
yum install -y docker-ce kubeadm-${VERSION} kubelet-${VERSION}
2、所有节点拉取镜像
kubeadm config images pull --image-repository "registry.aliyuncs.com/google_containers"
3、主节点升级Master
查询需要升级的信息:
kubeadm upgrade plan
进行升级:
kubeadm upgrade apply v1.17.0
如果报错可以使用–ignore-preflight-errors=CoreDNSUnsupportedPlugins类似的参数来忽略错误
4、所有节点从启kubelet
systemctl restart kubelet
5、升级Node
主要进行了升级部署在此节点上的控制平面实例,升级此节点的kubelet配置。
kubectl drain $NODE --ignore-daemonsets
kubeadm upgrade node
kubectl uncordon $NODE
准备工作需要在所有的节点进行。
所有节点,包括老节点:
cat >/etc/hosts <<EOF
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.22.22.7 k8s-master01 k8s-master01.rencaiyoujia.com
172.22.22.8 k8s-master02 k8s-master02.rencaiyoujia.com
172.22.22.9 k8s-master03 k8s-master03.rencaiyoujia.com
172.22.22.4 k8s-node01 k8s-node01.rencaiyoujia.com
172.22.22.5 k8s-node02 k8s-node02.rencaiyoujia.com
172.22.22.6 k8s-node03 k8s-node03.rencaiyoujia.com
10.15.9.211 k8s-node04 k8s-node04.rencaiyoujia.com
10.15.9.220 k8s-node05 k8s-node05.rencaiyoujia.com
EOF
新增节点:
hostnamectl set-hostname k8s-node04 #修改主机名,以便于在k8s中显示
systemctl stop firewalld && systemctl disable firewalld && setenforce 0 && sed -i "s/^SELINUX=enforcing/SELINUX=disabled/g" /etc/sysconfig/selinux
swapoff -a && sed -i 's/.swap./#&/' /etc/fstab
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv6.conf.all.disable_ipv6=1
net.ipv4.ip_forward=1
net.ipv4.tcp_tw_recycle=0 #NAT环境中建议关闭
vm.swappiness=0 #禁止使用swap空间,只有当系统发生OOM是才允许使用
vm.overcommit_memory=1 #内存分配策略:不检查物理内存是否够用
vm.panic_on_oom=0 #0表示开启OOM,杀死某些进程,而不是进行kernel pannic
fs.inotify.max_user_instances=8192
fs.inotify.max_user_watches=1048576
fs.file-max=52706963
fs.nr_open=52706963
net.netfilter.nf_conntrack_max=2310720 # 最大跟踪连接数
EOF
sysctl --system
rpm -qa |grep chrony &>/dev/null || yum install -y chrony
sed -i '2a server ntp1.aliyun.com iburst' /etc/chrony.conf
systemctl restart chronyd
systemctl enable chronyd
#关闭系统不需要的服务(可选)
systemctl stop postfix
systemctl disable postfix
#Centos7自带的3.10.x内核存在一些bug,导致docker、kubernetes不稳定。建议升级内核到4.4。
#参考文档:http://elrepo.org/tiki/tiki-index.php
#参考文档:https://blog.csdn.net/kikajack/article/details/79396793
#1、导入公钥
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
#2、安装elrepo内核软件源
yum install -y https://www.elrepo.org/elrepo-release-7.0-4.el7.elrepo.noarch.rpm
#3、查看可用的内核包
yum --disablerepo="*" --enablerepo="elrepo-kernel" list available
#4、安装长期支持版本
yum --enablerepo=elrepo-kernel install -y kernel-lt
#设置grub,开机从新内核启动:内核安装好后,需要设置为默认启动选项并重启后才会生效
#1、通过 gurb2-mkconfig 命令创建 grub2 的配置文件
grub2-mkconfig -o /boot/grub2/grub.cfg
#2、查看系统上的所有可以内核:
awk -F\' '$1=="menuentry " {print i++ " : " $2}' /etc/grub2.cfg
0 : CentOS Linux (4.4.202-1.el7.elrepo.x86_64) 7 (Core)
1 : CentOS Linux (3.10.0-862.11.6.el7.x86_64) 7 (Core)
2 : CentOS Linux (3.10.0-514.el7.x86_64) 7 (Core)
3 : CentOS Linux (0-rescue-f58eebd168fc4ff3809f5af6bf26ada0) 7 (Core)
#3、设置上面的0号内核为默认使用内核,然后重启
grub2-set-default 0
reboot
模块无需全部装入,可以按需装入,主要有ip_vs, ip_vs_rr, ip_vs_wrr, ip_vs_sh, nf_conntrack_ipv4
yum install -y ipvsadm #ipvs的管理工具,可选
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
ipvs_modules="ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_fo ip_vs_nq ip_vs_sed ip_vs_ftp nf_conntrack_ipv4"
for kernel_module in ${ipvs_modules}; do
/sbin/modinfo -F filename ${kernel_module} > /dev/null 2>&1
if [ $? -eq 0 ]; then
/sbin/modprobe ${kernel_module}
fi
done
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
参考文档:kube-proxy开启ipvs代替iptables
Docker:
# docker阿里云源
curl -o /etc/yum.repos.d/docker-ce.repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
### Install required packages for docker.
yum install -y device-mapper-persistent-data lvm2
yum install -y docker-ce-19.03.8
## Create /etc/docker directory.
mkdir /etc/docker
# Setup daemon.
cat > /etc/docker/daemon.json <<EOF
{
"graph": "/u01/install/docker",
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m",
"max-file": "3"
},
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
],
"registry-mirrors": ["https://lqetgo1f.mirror.aliyuncs.com","https://docker.mirrors.ustc.edu.cn/"],
"insecure-registries" : ["https://harbor.ljzsdut.com"]
}
EOF
mkdir -p /etc/systemd/system/docker.service.d
# Restart Docker
systemctl daemon-reload
systemctl restart docker
systemctl enable docker
Kubeadm& kubelet:
# kubernetes阿里云源
cat <<-EOF >/etc/yum.repos.d/kubernets.repo
[Kubernetes]
name=kubernetes repo
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
enabled=1
EOF
#安装kubeadm kubelet软件,为了保证与老节点的版本一致,我们可以指定安装版本
KUBE_VERSION=1.18.2
yum install -y kubeadm-${KUBE_VERSION} kubelet-${KUBE_VERSION} kubectl-${KUBE_VERSION} ipvsadm #kubectl、ipvsadm可选
# start kubelet
systemctl enable kubelet
systemctl start kubelet
systemctl status kubelet
此时的kubelet处于每隔10秒重启一次的状态,这种崩溃循环是正常的,kubelet在这个崩溃循环中等待kubeadm告诉它该怎么做。kubeadm通过生成/var/lib/kubelet/config.yaml配置文件来告诉kubelet需要干什么。
“max-file”: “3” #每个容器中日志数量,分别是id+.json、id+1.json、id+2.json
Node节点的加入集群前,首先要确保docker-ce、kubeadm、kubelet安装完毕。
最后再根据Master节点的提示加入集群。以下命令会以pod的方式启动kube-proxy:
使节点加入集群的命令格式是: kubeadm join --token <token> <master-ip>:<master-port> --discovery-token-ca-cert-hash sha256:<hash>
如果我们忘记了Master节点的token,可以使用下面的命令来查看:
[root@k8s-master01 ~]# kubeadm token list
默认情况下,token的有效期是24小时,如果token已经过期的话,可以使用以下命令重新生成:
[root@k8s-master01 ~]# kubeadm token create
W0607 10:14:53.487828 29674 configset.go:202] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
elwy21.gnqnvxyn66osyv1c
[root@k8s-master01 ~]# kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
elwy21.gnqnvxyn66osyv1c 23h 2020-06-08T10:14:53+08:00 authentication,signing <none> system:bootstrappers:kubeadm:default-node-token
如果你找不到–discovery-token-ca-cert-hash的值,可以使用以下命令生成:
[root@k8s-master01 ~]# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
d9e12b26d8d0b37a221030dfa4e373af8477b4f7636f723e821760d7c6ed4e80
除了上面通过两次命令找token和hash,也可以直接一次性执行如下命令来获取:
[root@k8s-master01 ~]# kubeadm token create --print-join-command
W0607 10:22:13.229567 5030 configset.go:202] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
kubeadm join 172.22.22.13:8443 --token nu0geu.kuiiy16njfkfeiqq --discovery-token-ca-cert-hash sha256:d9e12b26d8d0b37a221030dfa4e373af8477b4f7636f723e821760d7c6ed4e80
现在登录到工作节点服务器,然后用root权限运行如下命令加入集群
[root@k8s-node04 ~]# kubeadm join 172.22.22.13:8443 --token nu0geu.kuiiy16njfkfeiqq --discovery-token-ca-cert-hash sha256:d9e12b26d8d0b37a221030dfa4e373af8477b4f7636f723e821760d7c6ed4e80
W0607 10:27:50.040020 11196 join.go:346] [preflight] WARNING: JoinControlPane.controlPlane settings will be ignored when control-plane flag is not set.
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.18" ConfigMap in the kube-system namespace
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
节点的启动也需要一点时间,稍后再到Master上查看状态。
[root@k8s-master01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready master 10d v1.18.2
k8s-master02 Ready master 10d v1.18.2
k8s-master03 Ready master 10d v1.18.2
k8s-node01 Ready <none> 10d v1.18.2
k8s-node02 Ready <none> 10d v1.18.2
k8s-node03 Ready <none> 10d v1.18.2
k8s-node04 Ready <none> 10m v1.18.2
(可选设置)在node节点上使用kubectl,做如下配置:
scp root@k8smaster:/etc/kubernetes/admin.conf .
kubectl --kubeconfig ./admin.conf get nodes
kubernetes-tls-bootstrapping:
kubelet向apiserver 申请证书;
Controller Manager(默认批准控制器 )自动签署相关证书和自动清理过期的TLS Bootstrapping Token
1、https://jimmysong.io/posts/kubernetes-tls-bootstrapping
2、https://blog.fanfengqiang.com/2019/03/11/kubernetes-TLS-Bootstrapping%E9%85%8D%E7%BD%AE/
3、https://mritd.me/2018/08/28/kubernetes-tls-bootstrapping-with-bootstrap-token/
4、https://kubernetes.io/zh/docs/reference/command-line-tools-reference/kubelet-tls-bootstrapping/>