2.2 K8s资源对象之 Pod
Pod内一般建议只有一个容器,也可以有多个容器但是一般只有一个主容器,其他是辅助容器(边车容器)或者Init Container(初始化容器,可以有多个,而且多个初始化容器是串行运行的) 。pod内的多个容器共享底层的net、uts、ipc三种名称空间,而另外的user、mnt、pid名称空间是相互隔离的。虽然pod内的多个容器的mnt名称空间(文件系统)是相互隔离的,但是pod内的多个容器可以共享存储卷。即pod内所有容器共享网络、存储卷和/etc/hosts文件,这些是通过使用docker的–net和–volumes-from实现。
Pod分类:
静态Pod(Static Pod):
静态Pod在特定的节点上直接通过kubelet进行管理,不受apiserver的观察管理。静态Pod不是嵌入到控制器(如deployment)中创建,没有跟任何的副本控制器进行关联,所以静态Pod是不受控制器管理的Pod。而是由kubelet守护进程直接对其进行监控,如果崩溃了,kubelet守护进程会重启它,但是一旦node宕机后,pod便消失而不会再调度到其他的node上重启。 Kubelet通过Kubernetes apiserver为每个静态pod创建镜像pod,这些镜像pod对于APIserver是可见的,可以通过
kubelet get pods查看到,但是不受它控制。静态pod能够通过两种方式创建:配置文件或者 HTTP。1、配置文件方式
资源清单配置文件要求放在指定目录,需要是 json 或者 yaml 格式描述的标准的 pod 定义文件。使用
kubelet --pod-manifest-path=<the directory>(或在config文件中指定staticPodPath: /etc/kubernetes/manifests)启动 kubelet 守护进程,它就会定期扫描目录下面 yaml/json 文件的出现/消失/变化,从而执行 pod 的创建/删除。**静态Pod无法通过APIServer删除(若删除会变成pending状态),如需删除该Pod则将yaml或json文件从这个目录中删除。**例如kubeadm安装k8s时,apiserver、scheduler、controller-manager组件等就是有这种方式实现的。2、HTTP方式
Kubelet 定期的从参数 –manifest-url=<URL> 配置的地址下载文件,并将其解析为 json/yaml 格式的 pod 描述。它的工作原理与从 –pod-manifest-path=<directory> 中发现文件执行创建/更新静态 pod 是一样的,即,文件的每次更新都将应用到运行中的静态 pod 中。
控制器管理的Pod:
- ReplicationController:简称:rc,基本已经废弃
- ReplicaSet:简称:rs
- DaemonSet:简称:ds
- Deployment、HPA(HorizontalPodAutoscale)
- StatefulSet
- Job、Cronjob
简称:pod 、po
示例:pod-demo.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-demo
namespace: default
labels:
app: myapp
tier: frontend
#labels: {app:myapp,tier:frontend} #字典的另一种写法,不推荐使用
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
- name: busybox
image: busybox:latest
command: #此处给出command,会覆盖image的默认command
- "/bin/sh"
- "-c"
- "sleep 3600"
#command: ["/bin/sh","-c","sleep 3600"] #列表的另一种写法
pod从启动到终止,这个过程,pod内部做了哪些操作?
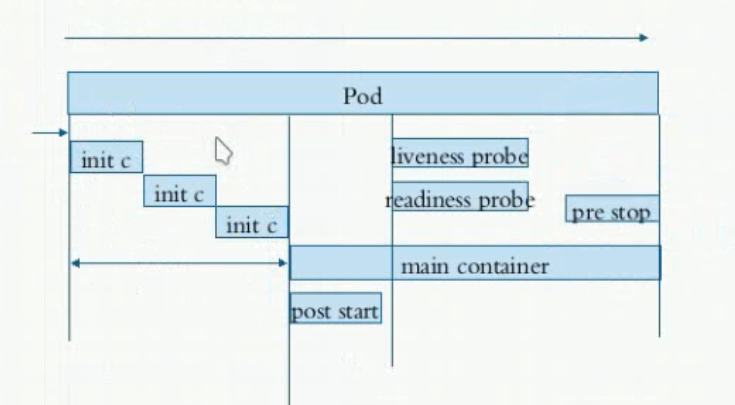
说明:上图中未画出pause容器,pause容器处于pod生命周期的最前,位于init containers之前。
pod的生命周期从创建开始到最终结束之间要经历一些事情,这些事情包含了初始化容器进行初始化、启动主容器和其他辅助容。主容器启动之后做启动后钩子,结束之前做结束前钩子。而整个运行期间要周期性的做liveness porbe和readiness probe。一旦probe探测到故障,由restartPolicy来决定容器是否被重启。一旦要删除Pod,会正常平滑地终止Pod,终止的时候,会先向Pod内的所有容器发送15号TERM信号,如果超过宽限期30s仍未终止,则会重新发送9号KILL信号。
Pod状态STATUS(kubectl get pod中的STATUS字段):
- Pending:挂起,表示Pod已经被k8s接受,但是有一个或多个容器还没有创建导致调度未完成。调度条件不满足导致调度无法完成或正在调度中(下载image)导致未调度完成
- Running:Pod中的所有容器都已经被创建。至少一个容器处于运行、正在启动或重启状态。
- Failed:Pod中的所有容器都已终止了,并且至少有一个容器是因为失败而终止。也就是说,容器以非0状态退出或被系统终止。(常出现在job和cronjob中)
- Sunneeded:Pod中的所有容器都被成功终止,而且不会再重启。
- Unknow:apiserver无法从kubelet上获取状态信息
创建Pod的阶段:
- 创建请求提交至apiserver,apiserver将信息保存在etcd数据库中
- apiserver请求scheduler进行pod调度,如果调度成功,将调度结果保存在etcd数据库中
- 目标节点上的kubelet通过apiserver的状态变化获取到新任务,此时kubelet会拿到创建请求的清单,根据清单在当前节点上创建Pod,无论创建成功还是失败,都会将结果信息发送给apiserver,apiserver将信息保存在etcd中。
Pod生命周期中的重要行为:
- 初始化容器
- 容器探测:
- liveness 存活探测
- readiness 就绪探测ready;就绪后才会被service调度请求至此pod
- postStart钩子和preStop钩子
- 启动后钩子postStart:容器创建后会立即调用PostStart钩子,如果钩子处理失败,容器会被终止,然后根据重启策略进行重启。(注意:容器启动后,先执行容器的command,然后再执行postStart的command。)
- 关闭前钩子preStop:在容器终止前,先进行preStop钩子,然后再进行终止操作。如果钩子执行失败,容器会被终止,然后根据重启策略进行重启操作。直至钩子完成才会进行其他容器操作,例如终止。
metadata:
name: filebeat-ds
namespace: default #缺省为default名称空间
一个对象可以有多个标签,实现对对象不同标准、不同层次地划分。不仅仅是pod可以打标签,所有的对象都可以打标签。
标签相关命令:
- kubectl get pods|deployment|… –show-labels 显示对象及其标签 kubectl get pods -l app 标签选择器:显示含有标签名为app的pod kubectl get pods -l app=myapp 标签选择器:显示含有标签名app=myapp的pod
- kubectl label [–overwrite] (-f FILENAME | TYPE NAME) KEY_1=VAL_1 … 修改/添加标签
在资源清单中创建标签:
metadata:
labels: <map[string]string> #
name: busybox-rc
标签命名规则:
- key:只能由字母、数字、_(下划线)、-(连接线)、.(点)组成,只能以字母或数字开头,最多可以有63个字符(具有键前缀格式的key最多可以有253个字符,例如kubernetes.io/hostname=xxx)
- value:只能由字母、数字、_(下划线)、-(连接线)、.(点)组成,只能以字母或数字开头和结尾,最多可以有63个字符,可以为空。
annotations与label不用的地方是不能用于挑选资源对象,仅用于为对象提供“元数据”,这些元数据可能被其他程序使用到。annotations没有字符数量限制。查看资源的注解信息使用kubectl describe TYPE NAME命令。
metadata:
annotations:
created-by: "cluster admin"
specification 规格、规范、详述
查看帮助文档:kubectl explain pods.spec
containers是个object类型的字段(object字段对应golang中的struct类型),常用字段:name(必需)、image、imagePullPolicy、command、args、env
spec:
containers:
- name: <string> #注意此处的命名不能有大写字母
image: <string>
imagePullPolicy: <Always|Never|IfNotPresent> #Nerver表示从不自动下载镜像,一般用于手动拉取镜像的情形;如果image的tag为latest,则缺省为Always;否则缺省为IfNotPresent
command: #等同于dockerfile中的ENTRYPOINT命令,但可以覆盖dockerfile中的ENTRYPOINT。注意此处给出的代码不会在shell中运行,这意味着像通配符等特性是不能使用的。如果要使用shell进行命令解析,使用如下方法:
- "/bin/sh"
- "-c"
- "xxx"
args: #等同于dockerfile中的CMD命令,但可以覆盖dockerfile中的CMD
- foo
- bar
ports: #容器暴露的端口。其实没有实际暴露端口作用,只是用来显示端口暴露信息的,是一个信息性的东西。即使没有设置,只要容器内端口是被监听的,端口依然是暴露的。这是因为k8s中容器暴露端口不需要像docker那样需要通过-p参数暴露端口到宿主机才能访问,因为pod间可以直接通过Pod IP:PORT访问。
- containerPort: <integer> #required
hostPort: <integer> #如果端口被暴露到宿主机,可以在此项中指明。类似的还有hostIp,但是会破坏随机部署的特性,如果非要指定hostIp,可以设置为“0.0.0.0”
name: <string> #为端口命名,之后可以在Service中通过名称来引用该端口;类似域名作用
protocal: <tcp|udp> #默认tcp
containers中的command和args是如何替换dockerfile中的ENTRYPOINT和CMD?
- 如果存在command和args,使用command和args;
- 如果既不存在command又不存在args,则使用dockerfile中的ENTRYPOINT和CMD;
- 如果只存在command,则只是用command,忽略dockerfile中的args。因为ENTRYPOINT别command替换后,命令都不同了,CMD参数肯定不能用了;
- 如果只存在args,则使用dockerfile中的ENTRYPOINT和args;
Here are some examples:
| Image Entrypoint | Image Cmd | Container command | Container args | Command run |
|---|---|---|---|---|
[/ep-1] | [foo bar] | <not set> | <not set> | [ep-1 foo bar] |
[/ep-1] | [foo bar] | [/ep-2] | <not set> | [ep-2] |
[/ep-1] | [foo bar] | <not set> | [zoo boo] | [ep-1 zoo boo] |
[/ep-1] | [foo bar] | [/ep-2] | [zoo boo] | [ep-2 zoo boo] |
containers.livenessProbe只用于判定主容器是否处于运行状态,成功后,“STATUS”字段为Running。
一个程序在长时间运行后或者有bug触发的情况下,会进入不正常的状态,这个不正常状态很严重,无法对外继续提供服务,以至于我们需要将容器内的进程杀死,重启整个容器/POD,使POD恢复到最初始的状态。liveness指令可以让你在系统出现这样的状态时,让Kubernetes帮你重启这个POD(重新构建容器)。即liveness探测失败后,kubelet会杀死容器,而后会根据Pod的restartPolicy策略进行是否重启处理。如果容器不提供存活探针,则默认认为Success。总之:如果触发liveness后,会根据容器的重启策略来重启容器。
容器探测是由kubelet对容器执行的定期检测。kubelet调用由容器实现的Handler,这个Handler我们称之为探针。容器的探测有存活性探测(containers.livenessProbe)和就绪性探测(readinessProbe),无论哪种检测方式,都支持如下三种探针类型,此外lifecycle也支持如下三种探针类型:
探针类型(支持3种探测行为):
- execAction:在容器内执行自定义命令,如果命令返回值为0则认为ok。
- tcpSocketAction:向指定的tcp套接字(tpc端口)发送请求,看是否可以建立tcp连接。
- httpGetAction:向指定的http服务发送http请求,即直接向指定的url发送get请求方法,根据相应码判定成功还是失败。如果200≤相应码<400,则认为ok。
每次容器他探测都将获取以下3种结果之一:
- 成功:容器通过诊断。
- 失败:容器未通过诊断。
- 未知:诊断失败,容器处于等待pendding状态。
kubectl explain pods.spec.containers.livenessProbe[.exec|.tcpSocket|.httpGet]
exec:
apiVersion: v1
kind: Pod
metadata:
name: liveness-exec-pod
namespace: default
spec:
containers:
- name: livenessProbe-exec-container
image: busybox:latest
imagePullPolicy: IfNotPresent
command: ["/bin/sh","-c","touch /tmp/health;sleep 30;rm -rf /tmp/health;sleep 3600"]
livenessProbe:
exec:
command:
- "test"
- "-e"
- "/tmp/healthy"
initialDelaySeconds: 2 #首次探测延迟探测时间。
periodSeconds: 3 #探测间隔时长,单位为s。默认为10s。
failureThreshold: 3 #成功之后,多少次连续的失败会被认定为faild。默认为3
timeoutSeconds: 1 #探测超时时长,默认为1s。
httpGet:
apiVersion: v1
kind: Pod
metadata:
name: liveness-httpGet-pod
namespace: default
spec:
containers:
- name: livenessProbe-exec-container
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
livenessProbe:
httpGet:
port: 80 #required,访问容器的端口号;如果定义ports,可以使用IANA_SVC_NAME,例如http
path: /index.html
initialDelaySeconds: 2 #首次探测延迟探测时间。
periodSeconds: 3 #探测间隔时长,单位为s。默认为10s。
failureThreshold: 3 #成功之后,多少次连续的失败会被认定为faild。默认为3
timeoutSeconds: 1 #探测超时时长,默认为1s。
tcpSocket:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: {{ APP_NAME }}-mysql
labels:
app: {{ APP_NAME }}-mysql
spec:
template:
metadata:
name: {{ APP_NAME }}-mysql
labels:
app: {{ APP_NAME }}-mysql
spec:
containers:
- name: {{ APP_NAME }}-mysql
image: {{ REGISTRY }}.cosmoplat.com/library/mysql:{{ IMAGE_VERSION }}
livenessProbe:
tcpSocket:
port: 3306
timeoutSeconds: 1
initialDelaySeconds: 120
periodSeconds: 10
successThreshold: 1
failureThreshold: 10
readinessProbe:
tcpSocket:
port: 3306
timeoutSeconds: 1
initialDelaySeconds: 60
periodSeconds: 10
successThreshold: 1
failureThreshold: 10
readinessProbe用于判定容器中的主进程是否已经准备就绪,并且可以对外提供服务。
readiness探测器的配置方式和liveness是一样的,区别在于它们对于Kubernetes的意义不一样。在readiness探测失败之后,**POD和容器并不会被删除,而是会被标记成特殊状态 **,进入这个状态之后,如果这个POD是在某个serice的endpoint列表里面的话,则会被从这个列表里面清除,以保证外部请求不会被转发到这个POD上。在一段时间之后如果容器恢复正常之后,POD也会恢复成正常状态,也会被加回到endpoint的列表里面,继续对外服务。容器是否就绪可以通过kubectl get pods中的"READY"字段查看。
当把一个新的Pod加入到Service时,Service将处于"READY"状态的Pod接入后端,如果Pod未能"READY",则不会介入到后端。所以对于像tomcat这样的启动时间比较长的应用程序,必须做readiness探测,因为Pod不做readiness探测,默认一启动就是Ready的,如果Pod处于Ready状态,Service会将请求发送到该Pod,但是其并未启动完成,并未处于真正的Ready状态,发送至其上的请求就无法处理。
总之:当触发readiness后,容器不会重启,但是会将此Pod从Service的后端中摘掉,不再接受流量。
apiVersion: v1
kind: Pod
metadata:
name: readiness-httpGet-pod
namespace: default
spec:
containers:
- name: readinessProbe-exec-container
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
livenessProbe:
httpGet:
port: 80 #required,访问容器的端口号;如果定义ports,可以使用IANA_SVC_NAME,例如http
path: /index.html
initialDelaySeconds: 2 #首次探测延迟探测时间。
periodSeconds: 3 #探测间隔时长,单位为s。默认为10s。
failureThreshold: 3 #成功之后,多少次连续的失败会被认定为faild。默认为3
timeoutSeconds: 1 #探测超时时长,默认为1s。
readinessProbe:
httpGet:
port: 80
path: /index.html
initialDelaySeconds: 2
periodSeconds: 3
failureThreshold: 3
timeoutSeconds: 1
从1.16开始加入了startupProbe探针,1.18版本进入beta版本。
startupProbe的存在意义?
1、如果将readinessProbe的initialDelaySeconds设置很长,但是随着程序功能的增加仍然有延迟时间不够的情况发生。
2、如果把periodSeconds和failureThreshold的值调大,就会增加程序出现问题之后的判定时间,不利于及时重启问题Pod。
readinessProbe:
failureThreshold: 3
httpGet:
path: /
port: 80
scheme: HTTP
periodSeconds: 5
successThreshold: 1
timeoutSeconds: 1
startupProbe:
httpGet:
path: /
port: 80
scheme: HTTP
failureThreshold: 60
periodSeconds: 10
timeoutSeconds: 3
由于启动探针的存在,会先禁用程序livenessProbe和readinessProbe探针。程序有60*10s=600s的启动时间,一旦启动探针探测成功之后,就会被livenessProbe接管,启动探针退出探测。这样在运行中出问题livenessProbe就能在5*3=15s内发现。如果启动探测是600s内还没有探测成功,则接受Pod的重启策略进行重启。
【程序启动后,到底需要多长时间可以达到就绪状态?】
1、 程序启动后,等待startupProbe.initialDelaySeconds之后,才开始startupProbe。经测试(经验结论,没有源码验证),开始startupProbe之后的首次探测,需要等待(startupProbe.periodSeconds/2)时间之后再进行。
2、startupProbe一旦Sucess之后,需要再等待readinessProbe.initialDelaySeconds后,才开始readinessProbe。经测试(经验结论,没有源码验证),开始startupProbe之后的首次探测,需要等待(readinessProbe.periodSeconds/2)时间之后再进行。
【综上所述】:我们可以设置startupProbe.periodSeconds=10,则会在启动5s后进行首次的startupProbe。如果成功后,当设置readinessProbe.periodSeconds=5再等待3s(5/2s)左右,就开始首次的readinessProbe。而且启用startupProbe之后,可以去掉initialDelaySeconds配置。
postStart:注意:容器启动后,先执行容器的command(因为执行容器的command属于启动过程),然后再执行postStart的command。所以容器的command命令不能强依赖于postStart的执行结果。
apiVersion: v1
kind: Pod
metadata:
name: poststart-pod
namespace: default
spec:
containers:
- name: busybox-httpd
image: busybox:latest
imagePullPolicy: IfNotPresent
command: ["/bin/sh","-c","sleep 3600"]
lifecycle:
postStart:
exec:
command:
- "/bin/sh"
- "-c"
- "mkdir -p /data/web/html;echo 'HOME PAGE'>>/data/web/html/index.html"
preStop:
exec:
command:
- "/bin/sh"
- "-c"
- "echo 'stop pod'>>/data/web/html/index.html"
Pod内能够具有多个容器,应用运行在容器里面,但是它也有可能有一个或多个先于应用容器启动的Init容器。
Init容器与普通的容器非常像,除了如下两点:
- Init容器总是运行到成功完成为止(返回值为0),正常退出。
- 每一个Init容器必须在上一个Init容器成功完成之后才可以启动。也就是多个Init容器是串行执行的。
Init容器的说明:
- 如果Init容器启动失败,会根据Pod的restartPolicy指定的策略进行重试。如果Pod的restartPolicy设置为Always,则k8s会不断地重启该Pod,直到Init容器成功为止;如果Pod对应的restartPolicy为Never,则Pod不会重新启动。
- Init容器会在pause容器初始化网络和数据卷完成之后启动。
- 在所有的Init容器没有成功之前,Pod将不会变成Ready状态,Init容器的端口将不会在Service中进行聚集。正在初始化的Pod处于Pedding状态,同时将Initializing状态设置为true。
- 如果Pod重启,所有的Init容器重新执行。init容器执行需要有幂等状态
- 对Init容器的sepc字段进行修改时,只允许修改image字段,修改其他字段都不会生效。更改Init容器的image字段,相当于重启该Pod。
- Init容器具有普通容器的所有字段,除了readinessProbe和livenessPorbe,因为Init容器执行完就会退出。
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: myapp-main-container
image: busybox
command: ['sh','-c','echo "The app is running!" && sleep 3600']
initContainers:
- name: init-myservice
image: busybox
command: ['sh','-c','until nslookup myservice; do echo waiting for myservice; sleep 2;done;']
- name: init-mydb
image: busybox
command: ['sh','-c','until nslookup mydb; do echo waiting for mydb; sleep 2;done;']
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9376
---
apiVersion: v1
kind: Service
metadata:
name: mydb
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9377
resource limit 主要是被系统的cgroups 所引用,限制 pod 对应的资源最大使用限制, request 则是kubernetes在调度时用于判断那一个节点上的资源符合当前pod的使用需求打分后调度, limit和request可以通过不同组合来对 pod 的QoS 等级做出评级, QoS等级影响 Node 节点上资源满载时所采取驱逐Pod的顺序
详情参考:9.1-k8s资源限制.md
推荐:https://cloud.tencent.com/developer/article/1645042
以上内容会在后面详述。
作用:限定Pod运行在哪个或哪些节点上
spec:
nodeName: <string> #直接选择某个特定的node
spec:
nodeSelector: #<map[string]string> #选择具有某个标签的node
disktype: ssd
kubernetes.io/arch: amd64
其他详见k8s调度策略
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: type
operator: NotIn
values:
- virtual-kubelet
https://blog.csdn.net/H_B_K/article/details/110293125
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: rack
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: business
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
topologySpreadConstraints:
- maxSkew: <integer>
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>
- maxSkew 描述 Pod 分布不均的程度。这是给定拓扑类型中任意两个拓扑域中 匹配的 pod 之间的最大允许差值。它必须大于零。取决于的whenUnsatisfiable 取值,其语义会有不同。
- 当 whenUnsatisfiable 等于 “DoNotSchedule” 时,maxSkew 是目标拓扑域 中匹配的 Pod 数与全局最小值之间可存在的差异
- 当 whenUnsatisfiable 等于 “ScheduleAnyway” 时,调度器会更为偏向能够降低 偏差值的拓扑域。
- topologyKey 是节点标签的键。如果两个节点使用此键标记并且具有相同的标签值, 则调度器会将这两个节点视为处于同一拓扑域中。调度器试图在每个拓扑域中放置数量 均衡的 Pod。
- whenUnsatisfiable,指示如果 Pod 不满足分布约束时如何处理:
- DoNotSchedule(默认)告诉调度器不要调度。
- ScheduleAnyway 告诉调度器仍然继续调度,只是根据如何能将偏差最小化来对 节点进行排序。
- labelSelector 用于查找匹配的 pod。匹配此标签的 Pod 将被统计,以确定相应 拓扑域中 Pod 的数量。
Pod中容器重启策略:
- Always:一旦Pod内容器挂了,就重启。**默认值。**反复重启逻辑:第一次,立即重启;之后重启采取的是指数延迟重启策略(10秒,20秒,40秒……)进行重新启动,上限为五分钟,并在重启成功十分钟后重置延迟重启。Pod一旦绑定到节点,Pod重启将永远不会被重新绑定到另一个节点,除非该节点宕机。
- OnFailure:只有容器状态为Failure时,才重启
- Never:从不重启
spec:
restartPolicy: <Always|OnFailure|Never>
设置为true,则pod使用宿主机网络名称空间。默认为false。
注意:
如果pod的网络设置为hostNetwork,此时pod使用dns为宿主机的dns,如果要使用k8s内的coredns,则需要设置
dnsPolicy: ClusterFirstWithHostNet,否则无法解析svc。
设置为true,则pod使用宿主机PID空间。默认为false。
spec:
hostAliases:
- ip: "192.168.5.2"
hostnames:
- "k8s-node1"
- "k8s-node1.ljzsdut.com"
containers:
后面详解,请查看存储卷。
如何定义pod内部解析域名时使用的dns-server呢?是使用集群的coreDns,还是使用宿主机的dns server?可以设置pod Spec中的dnsPolicy字段,有如下几种取值:
- “Default“:从节点继承DNS相关配置,对节点依赖性强。比如coredns就是使用Default模式。
- “ClusterFirst“:如果DNS查询与配置好的默认集群域名前缀不匹配,则将查询请求转发到从节点继承而来,作为查询的上游服务器。
- “ClusterFirstWithHostNet“:如果pod工作在主机网络,就将dnsPolicy设置成“ClusterFirstWithHostNet”,这样效率更高。在某些场景下,我们的 POD 是用 HOST 模式启动的(HOST模式,是共享宿主机网络的),一旦用 HOST 模式,表示这个 POD 中的所有容器,都要使用宿主机的 /etc/resolv.conf 配置进行DNS查询,但如果你想使用了 HOST 模式,还继续使用 Kubernetes 的DNS服务,那就将 dnsPolicy 设置为 ClusterFirstWithHostNet。
- “None“:1.9版本引入的新特性(Beta in v1.10)。完全忽略kubernetes系统提供的DNS,以pod Spec中dnsConfig配置取而代之,实现自定义DNS配置。
如果dnsPolicy字段未设置,默认策略是"ClusterFirst"。
自定义DNS配置可以通过 spec.dnsConfig 字段进行设置(一般与dnsPolicy: "None"一起使用),可以设置下列信息。
- nameservers:一组DNS服务器的列表,最多可以设置3个。
- searches:一组用于域名搜索的DNS域名后缀,最多可以设置6个。
- options:配置其他可选DNS参数,例如ndots、timeout等,以name或name/value对的形式表示。
spec:
dnsPolicy: "None"
dnsConfig:
nameservers:
- 1.2.3.4
searches:
- ns1.svc.cluster-domain.example
- my.dns.search.suffix
options:
- name: ndots
value: "2" #表示如果给定的域名点分后,大于等于2个部分,则不再进行搜索域补全。
- name: edns0
关于dns search解析效率:为了提升效率,尽量将域名写全,例如nginx.default.svc.cluster.local,这样就可以不再进行搜索域补全,提供解析效率。
可以提供域名解析测试的工具:dig、nslookup、host -v
12、Pod的PriorityClass
kubernetes支持多种资源调度模式,前面讲过简单的基于nodeName和nodeSelector的服务器资源调度,我们称之为用户绑定策略,下面简要描述基于PriorityClass的同一node下不同pod资源的优先级调度,我们称其为抢占式调度策略
现在版本支持Pod优先级抢占,通过PriorityClass来实现同一个Node节点内部的Pod对象抢占。根据 Pod 中运行的作业类型判定各个 Pod 的优先级,对于高优先级的 Pod 可以抢占低优先级 Pod 的资源。Pod priority指的是Pod的优先级,高优先级的Pod会优先被调度,或者在资源不足低情况牺牲低优先级的Pod,以便于重要的Pod能够得到资源部署.
定义PriorityClass对象:
apiVersion: scheduling.k8s.io/v1alpha1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000 #小于或等于 10 亿的任何整数(大于 10 亿的会分配给关键系统 Pod),value 越大则优先级越高
#preemptionPolicy: PreemptLowerPriority # 抢占功能开关,默认为 `PreemptLowerPriority`(开启);当配置为 `Never` 时声明了该 PriorityClass 的 Pod 将不会进行抢占。该配置仅在 Kubernetes v1.15 及更新版本中可用,且需要开启`NonPreemptingPriority` 特性开关。
globalDefault: false #是否为默认 PriorityClass,默认配置为 `false` 。每个集群只能有一个配置了 globalDefault 为 `true` 的 PriorityClass,所有没有声明 PriorityClass 的 Pod 将默认使用这个 PriorityClass。当集群没有默认 PriorityClass 时,所有没有声明 PriorityClass 的 Pod 的 value 为 0。
description: "This priority class should be used for XYZ service pods only." #任意字符串,旨在告诉集群用户应在何时使用此 PriorityClass。
在Pod的spec. priorityClassName中指定已定义的PriorityClass名称
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority #指定pod的优先级类
当节点没有足够的资源供调度器调度Pod、导致Pod处于pending时,抢占(preemption)逻辑会被触发。Preemption会尝试从一个节点删除低优先级的Pod,从而释放资源使高优先级的Pod得到节点资源进行部署。
注意:
- 将不具有 Pod 优先级和抢占功能的集群进行升级后,原有 Pod 的优先级默认为 0。
- 默认 PriorityClass 创建时,不会影响到原有 Pod 的优先级。
- 删除 PriorityClass 不会影响到原有的声明了此 PriorityClass 的 Pod。
- 禁用了抢占功能的 Pod 仍可能被其它优先级更高的 Pod 抢占。
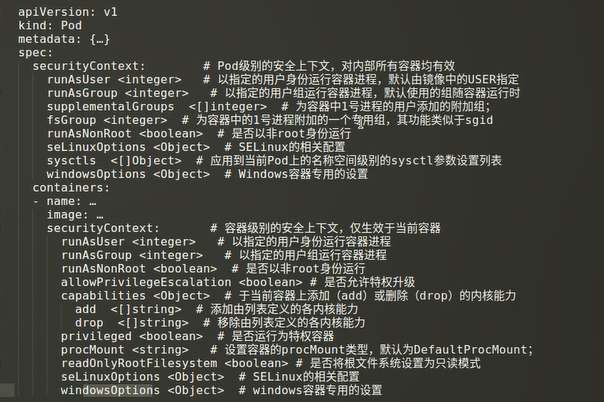
Pod的安全上下文是一组用于决定容器是如何创建和运行的约束条件,它们代表创建和运行容器时使用的运行参数;
安全上下文有2个级别:
- Pod级别
- 容器级别
此外,管理员可以定义PSP(PodSecurityPolicy)资源实现全局的安全上下文。
相关的配置如下:
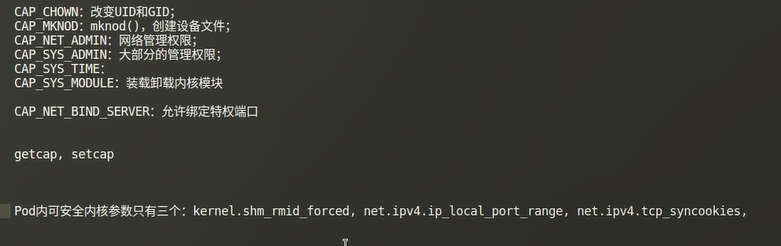
关于capabilities,可以参考这篇blog