3.1 K8s服务发现之 Service
三、Service
简称:svc
作用:用于服务发现、服务调度(四层调度器)。Service的名称解析强依赖于k8s的DNS服务(例如CoreDNS附件)。
Kubernetes Service 定义了这样一种抽象:一个 Pod 的逻辑分组,一种可以访问它们的策略。这一组 Pod 能够被 Service 访问到,通常是通过 Label Selector 来实现的。
在 Kubernetes 中,Pod 虽然拥有独立的 IP, 但 Pod 会快速地创建和删除,因此,通过 Pod 直接对外界提供服务不符合高可用的设计准则。通过 Service 这个抽象,Service 能够解耦 frontend(前端)和 backend(后端) 的关联,frontend 不用关心 backend 的具体实现,从而实现松耦合的微服务设计。
Service可以理解为是一个负载均衡调度器,它为具有生命周期的Pod提供了固定的访问入口,一个Service后端关联着一个或多个Pod,当Service接收到请求后,会将其转发到后端的Pod来处理。Service与常规的负载均衡器如Nginx不同的是,它可以自动发现后端服务器的增删,并实时生效后端Pod列表。那Service是怎么知道它后端对应哪些Pod呢?其实Service是通过标签选择器选择符合条件的Pod(也可以手动创建Endpoints对象来设置后端Pod),只要Pod具有标签选择器指定的标签和标签值,这个Pod就会被加入到Service的后端列表中。
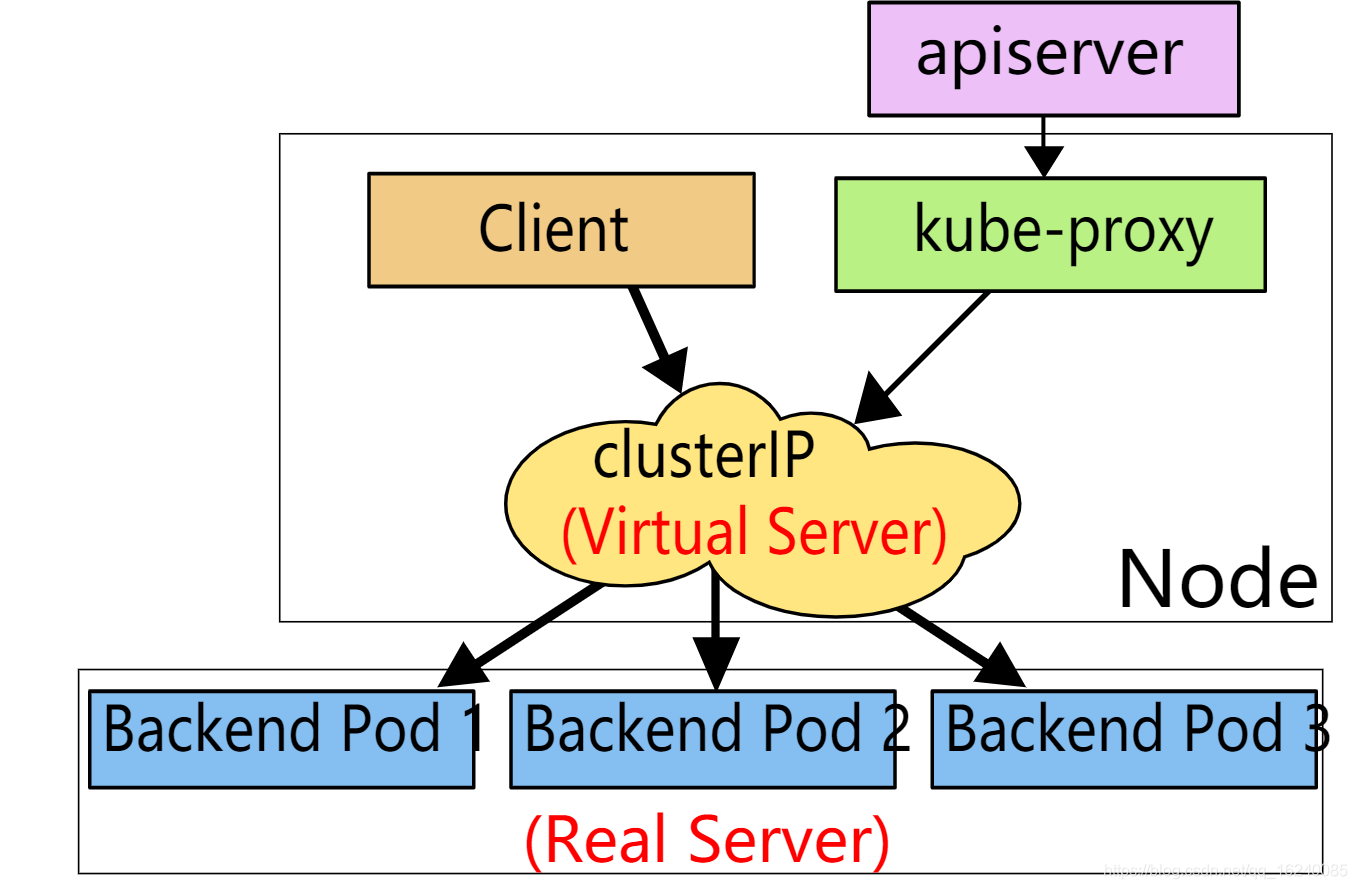
k8s上,Service并不是一个应用程序,也不是一个实体组件,只不过是一个iptables的dnat规则或者是ipvs规则(当创建一个Service时,会在集群内的每一个Node节点上创建相应的iptables/ipvs规则)。Service的地址不会出现在任何一块网卡上,它只会出现在iptables规则中,所以这个地址是无法ping通的,因为没有tcp协议栈来支持这个地址来响应ping(ipvs模式下,svc是可以ping通的)。但是Service却是可以用来被客户端请求,此外Service作为k8s对象, 它具有Service Name,而且这个名称可以被解析,可以将这个ServiceName解析为Service的IP,这里的名称解析由k8s的dns附件(addons,附加组件)来实现,例如kubedns,coredns等。k8s的dns组件是动态管理的,dns解析记录是动态创建、动态删除、动态改变,当我们修改Service的名称或修改Service的IP,dns解析记录会自动做相应的修改。
每个Node上的kube-proxy组件,它始终监视(watch请求)着apiserver中有关service(准确来说是endpoint)资源的变动信息。一旦service资源变动(包括创建),kube-proxy都要将变动信息转换为当前Node上iptables/ipvs规则。具体是iptables还是ipvs,取决于k8s的service实现方式。
推荐视频:https://www.bilibili.com/video/BV1Ft4y117Ch?p=4
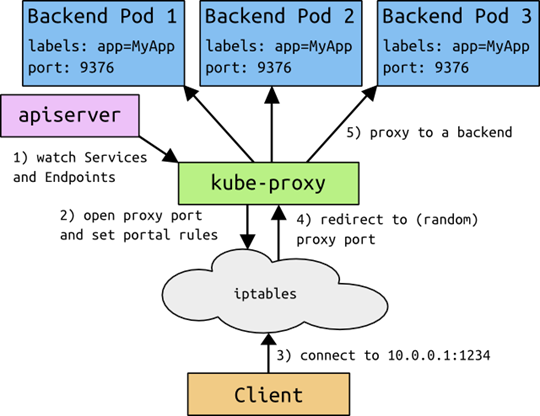
即:当对于每个Service,Kube-Proxy会在本地Node上打开一个随机选择的端口,连接到代理端口的请求,都会被代理转发给Pod。那么通过Iptables规则,捕获到达Service:Port的请求都会被转发到代理端口,代理端口重新转为对Pod的访问
缺点:存在内核态转为用户态(kube-proxy),再有用户态转发的两次转换,性能较差,一般不再使用
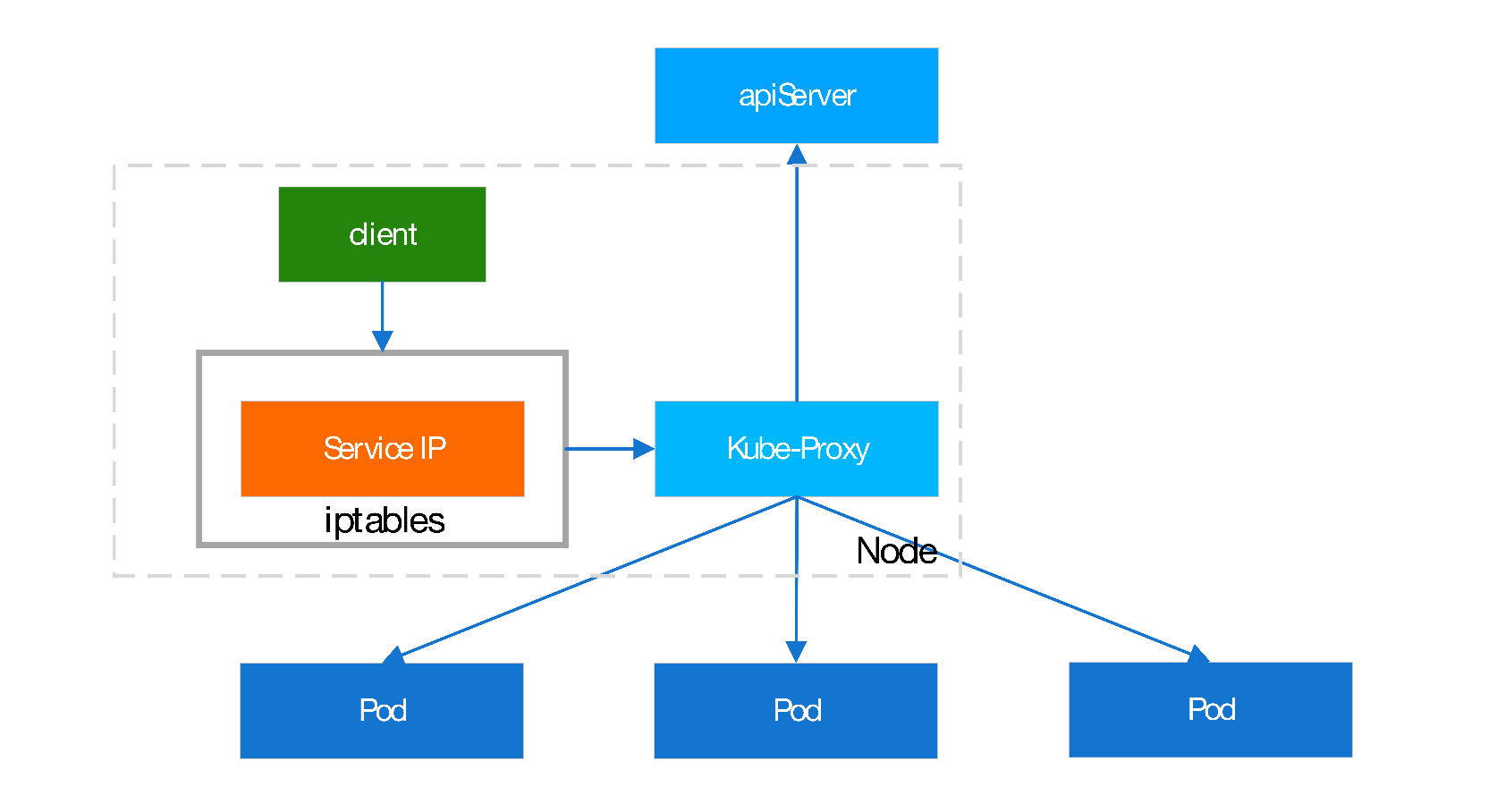
由Proxy在Node上创建监听端口,配置iptables规则将流量指向代理端口,代理端口再将请求转发至Pod。
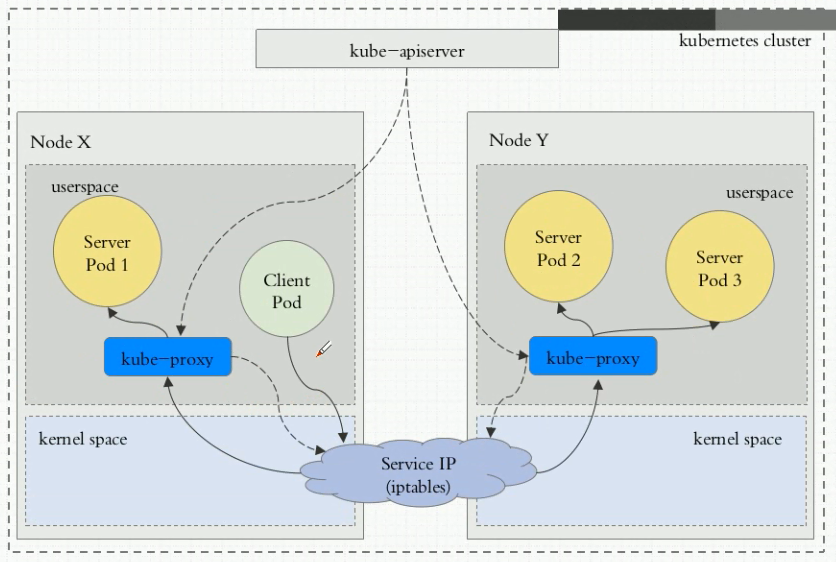
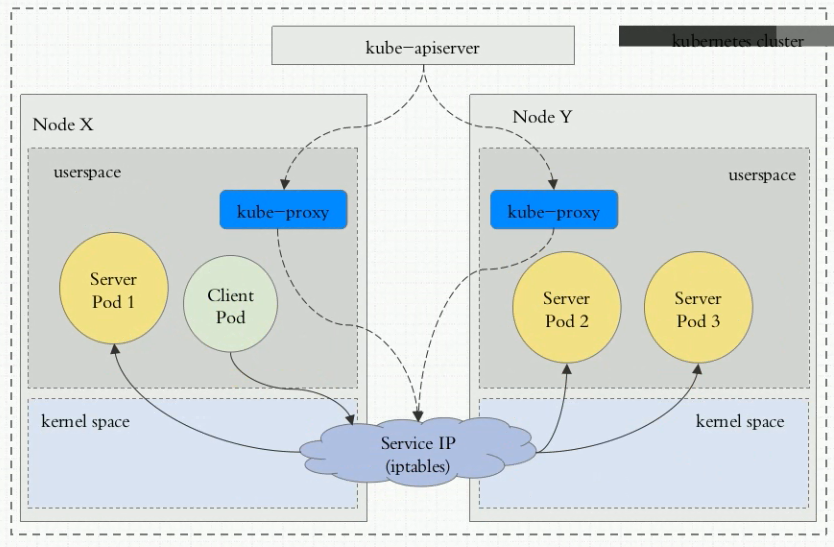
流量走向如下图:Client pod–>内核空间iptables–>用户空间kube-proxy–>pod2;
缺点:由用户空间的kube-proxy进行接受并调度,流量需要在内核空间和用户空间不断转换,效率很低,基本已经废弃;v1.1及之前版本
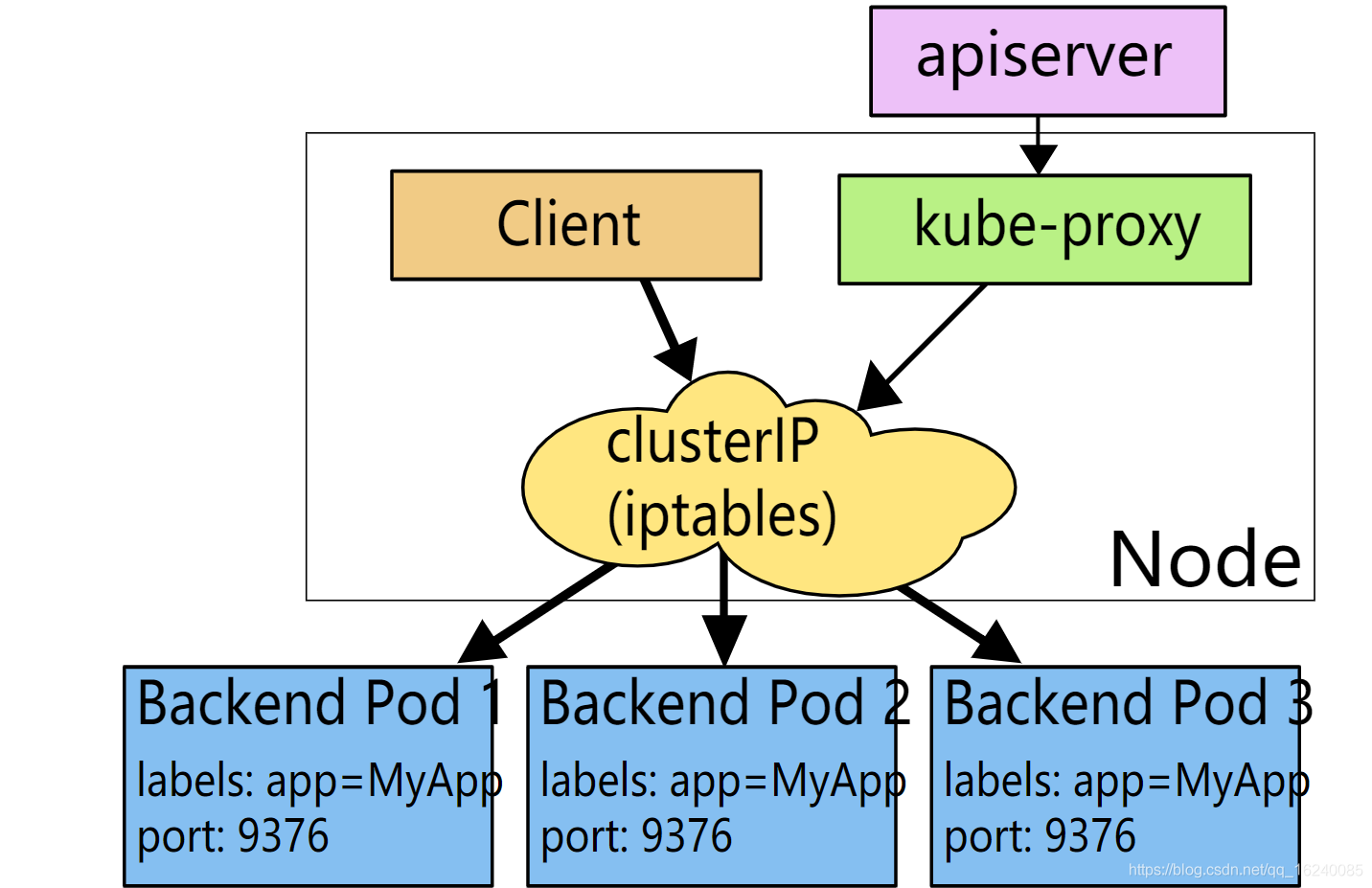
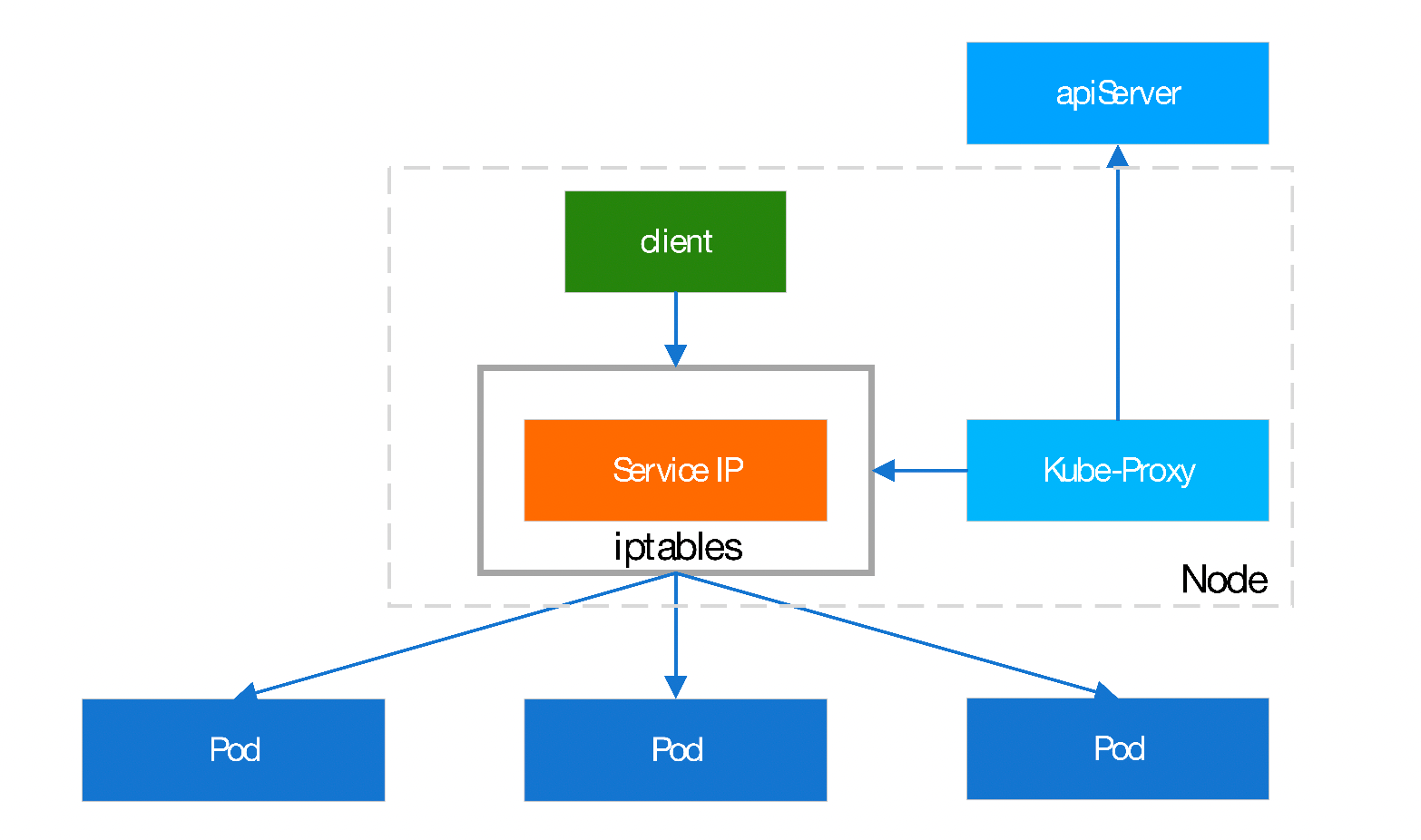
Client pod的请求直接由iptables规则调度至目标pod2,由内核空间的iptables规则进行调度;v1.2~v1.10
缺点:如果pod数量很多,会有很多iptables规则。而iptables规则变动时,比如某个pod重启导致iptables规则中pod的IP发生变化,而用户空间的iptables工具向内核的netfilter发送规则时,是全量的,需要将全部的iptables规则都发送过去,该规则变化可能需要几分钟。
岔个话题:我只能说K8s默认使用iptables来实现Service到Pod的转换欠下了大量的技术债。K8s的问题列表里面曾经记录了一个问题#44613:在100个Node的K8s集群里,kube-proxy有时会消耗70%的CPU。还有一个更恐怖的对比数据:当K8s里有5k个services(每个service平均需要插入8条rule,一共40k iptables rules)的时候,插入一条新的rule需要11分钟;而当services数量scale out 4倍到20k(160k rules)时,需要花费5个小时,而非44分钟,才能成功加入一条新的rule。可以看到时间消耗呈指数增加,而非线性。
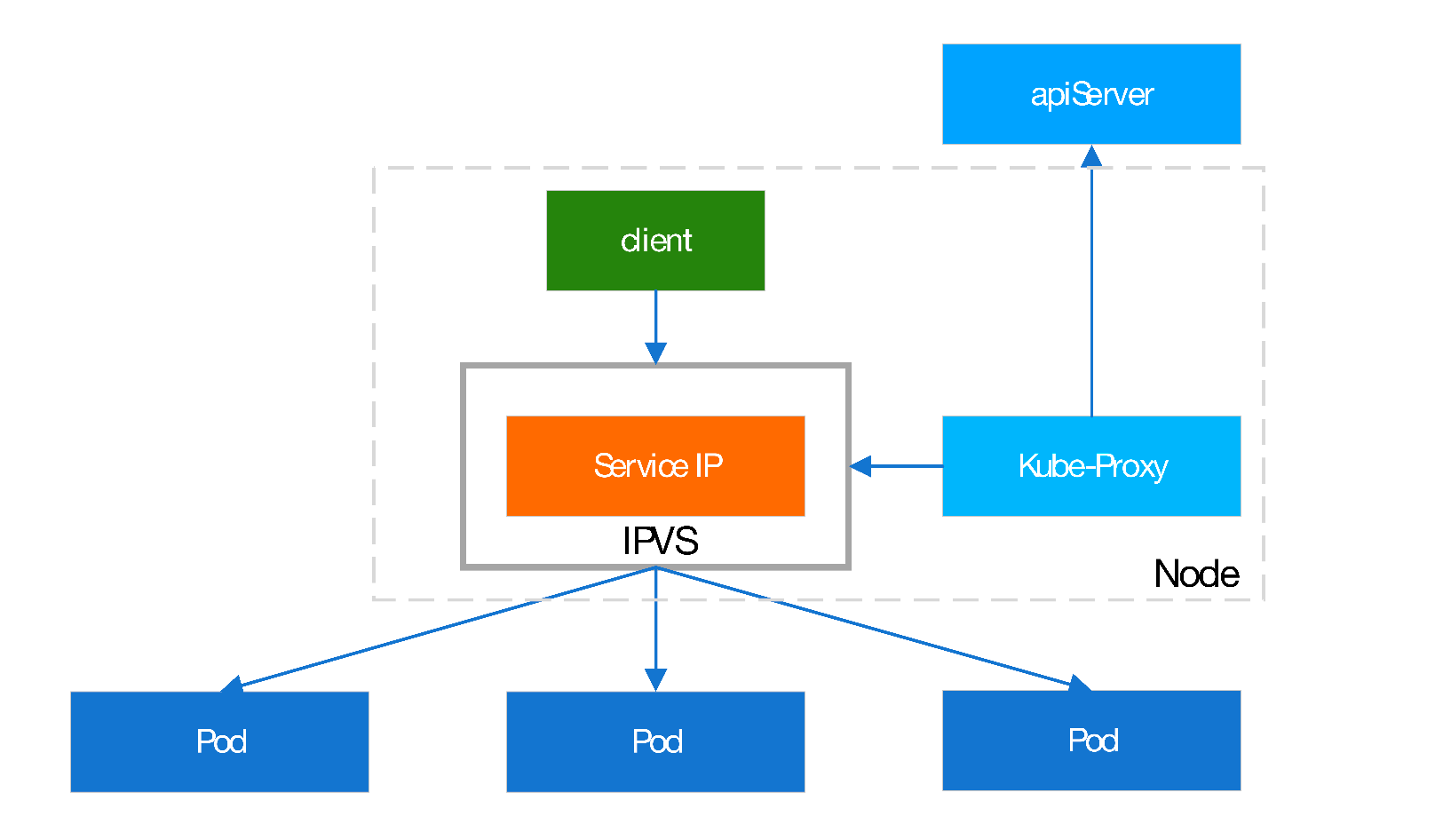
Client pod的请求直接由ipvs规则调度至目标pod2;v1.11+,
即使kube-proxy已经设置启用ipvs模式,但是其在启动时,会验证节点是否安装了ipvs的相关模块,如果未启用ipvs,自动转换为iptables。
如何更换代理模式:
#更改kube-proxy配置,kubeadm部署方式可以修改configmap
# kubectl -n kube-system edit configmap/kube-proxy
ipvs:
excludeCIDRs: null
minSyncPeriod: 0s
scheduler: “rr" #负载均衡算法
strictARP: false
syncPeriod: 0s
tcpFinTimeout: 0s
tcpTimeout: 0s
udpTimeout: 0s
kind: KubeProxyConfiguration
metricsBindAddress: ""
mode: "ipvs" #代理模式
ipvs各种内核模块提供的负载均衡算法:
rr:轮询
lc:最小连接数
dh:目标哈希
sh:源哈希
sed:最短期望延迟
nq:不排队调度
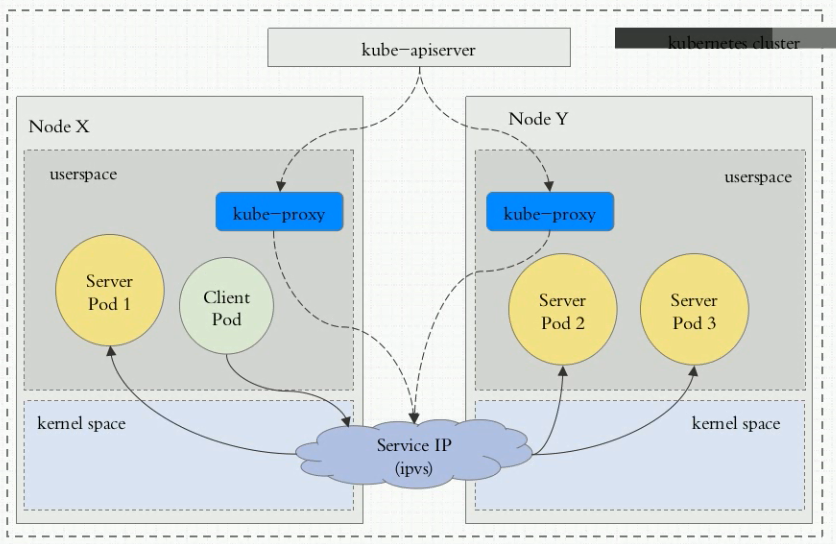
如果某个service后端的pod资源发生改变了,比如service的标签选择器发送改变导致后端又增加了一个pod,该pod的适用信息会立即反应到apiserver上(etcd中),而后kube-proxy会watch到该变化并将该变化立即转变为service规则(iptables/ipvs规则)。
ipvs和iptables都是基于netfilter的(调用netlink接口创建相应的iptables/ipvs规则),他们的差别为:
- ipvs 为大型集群提供了更好的可扩展性和性能
- ipvs 支持比 iptables 更复杂的复制均衡算法(最小负载、最少连接、加权等等)
- ipvs 支持服务器健康检查和连接重试等功能
ClusterIP:默认值;分配一个集群内部地址(私网地址),仅用于集群内通信(可以被节点node/master、pod访问,但是不能被集群外部访问);
如果在ClusterIP类型的Service中,将clusterIP的值设置为None,则会创建一个无头服务(headless Service)。
这种无头服务不会分配集群内部的私网地址(Cluster IP),而且endpoints会被设置为一组endpoints而不是一个Cluster IP。一个有头的Service会定义一个clusterName和一个对应的clusterIP。当域名解析ClusterName时,会解析为clusterIP。如果该服务为headless service,在定义时,会将Service的clusterIP设置为None,此时在域名解析clusterName时,因为没有clusterIP而会直接解析为后端Endpoints的PodIP(多条A记录)。一般在StatefulSet中会使用到无头服务。
NodePort:接收集群外部的访问。它是构建在ClusterIP的基础之上。客户端请求流程:client-->[负载均衡器(slb/nginx)]-->NodeIP:NodePort-->ClusterIP:ClusterPort-->PodIP:ContainerPort
LoadBalancer: 通过云供应商提供的负载均衡器暴露服务(例如阿里云的负载均衡器slb),将自动创建外部负载平衡器路由到k8s节点的NodePort上 。LoadBalancer类型的service是构建在NodePort的基础之上的。当使用LoadBlancer Service暴露服务时,实际上是通过向底层云平台申请创建一个负载均衡器来向外暴露服务; 客户端请求流程:client-->负载均衡器(slb)-->NodeIP:NodePort-->ClusterIP:ClusterPort-->PodIP:ContainerPort
ExternalName:在集群内部引用一个外部的服务,在集群内部直接使用。该类型的特点是Service的Endpoints为集群外部的服务,实现了集群内部pod和集群外部的服务进行通信。
可以创建Service的资源:pod (po), service (svc), replicationcontroller (rc), deployment (deploy), replicaset (rs)
kubectl expose (-f FILENAME | TYPE NAME) [--port=port] [--protocol=TCP|UDP|SCTP] [--target-port=number-or-name] [--name=name] [--external-ip=external-ip-of-service] [--type=type] [options]
#externalIPs:如果想通过svc来负载,但要求某台指定的(一个或多个)node上监听,而非像nodeport所有节点监听.此时可以指定externalIPs。这时候,会在具有指定externalIP的主机上,有kube-proxy来启动的指定端口svc port(注意不是监听nodePort)。需要注意的是,externalIPs并不受k8s管理,需要用户手动在k8s某个节点上配置该IP.
root@mgt03:~# kubectl get svc lcm-manager -n lcm -oyaml
apiVersion: v1
kind: Service
metadata:
annotations:
meta.helm.sh/release-name: lcm-mananager
meta.helm.sh/release-namespace: lcm
labels:
app: lcm-manager
app.kubernetes.io/managed-by: Helm
appinstance: lcm-manager
application: lcm-manager
deployment: lcm-manager
user: lcm
user_group: group-cloud-operator
name: lcm-manager
namespace: lcm
spec:
clusterIP: 100.105.26.62
clusterIPs:
- 100.105.26.62
externalIPs:
- 10.200.8.71
- 10.110.62.71
ports:
- name: http
port: 8094
protocol: TCP
targetPort: 8094
selector:
app: lcm-manager
appinstance: lcm-manager
application: lcm-manager
deployment: lcm-manager
user: lcm
user_group: group-cloud-operator
type: ClusterIP
root@mgt03:~# kubectl get svc lcm-manager -n lcm
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
lcm-manager ClusterIP 100.105.26.62 10.200.8.71,10.110.62.71 8094/TCP 37d
root@mgt03:~# ip a |grep -E '10.200.8.71|10.110.62.71'
inet 10.110.62.71/32 scope global br-mgm
inet 10.200.8.71/32 scope global control
root@mgt03:~# ss -tnlp|grep 8094
LISTEN 0 65535 10.200.8.71:8094 0.0.0.0:* users:(("kube-proxy",pid=6302,fd=89))
LISTEN 0 65535 10.110.62.71:8094 0.0.0.0:* users:(("kube-proxy",pid=6302,fd=59))
apiVersion: v1
kind: Service
metadata:
name: redis #该名称会自动被k8s dns记录并解析,例如使用“redis.default.svc.cluster.local.”引用
namespace: default
spec:
selector: #注意Service.spec.selector与其他资源对象不同,无需matchLabels或matchExpressions来嵌套
app: redis
release: stable
clusterIP: 10.97.97.97 #Service的IP;缺省为随机分配,手动指定时注意范围,为10.96.0.0/12的子网,不建议指定。如果该值指定为"None",则该Service为无头Service(headless),其EndPoints为后端Pod的ip。
type: ClusterIP #默认为ClusterIP,可选值为:ExternalName, ClusterIP, NodePort, LoadBalancer
ports:
- name: redis
protocol: TCP #Servcie监听协议:TCP|UDP,默认为TCP
port: 6379 #Service上的端口;required选项
targetPort: 6379 #Service后端Pod上的端口,缺省时同port。
#nodePort: 6379 #Node上的端口;只有type为NodePort时,此项才生效;注意如果指定该值,需要保证所有Node上该端口未使用。如果不指定该值,随机分配。无论手动指定还是随机分配,可用端口范围:30000-32767
service的作用,主要是代理一组pod容器负载均衡服务,但是有时候我们不需要这种负载均衡场景,比如下面的两个例子。
比如kubernetes部署某个kafka集群,这种就不需要service来代理,客户端需要的是一组pod的所有的ip。
还有一种场景客户端自己处理负载均衡的逻辑,比如kubernates部署两个mysql,有客户端处理负载请求,或者根本不处理这种负载,就要两套mysql。
像 elasticsearch, etcd 这种分布式服务, 在集群初期 setup 时, 配置文件中就要写上集群中所有节点的IP(或是域名)。但是由于k8s集群的特性, Pod 是没有固定IP的, 所以配置文件里不能写IP. 但是用 Service 也不合适, 因为 Service 作为 Pod 前置的 LB, 一般是为一组后端 Pod 提供访问入口的, 而且 Service 的
selector也没有办法区别同一组 Pod, 没有办法为每个 Pod 创建单独的 Serivce。于是有了 Statefulset,它为每个 Pod 做一个编号, 就是为了能在这一组服务内部区别各个 Pod, 各个节点的角色不会变得混乱。同时创建所谓的 headless service 资源, 这个 headless service 不分配 ClusterIP, 因为根本不会用到. 集群内的节点是通过Pod名称+序号.Service名称确定彼此进行通信的, 只要序号不变, 访问就不会出错.比如es:
node.name: es-01 network.host: 0.0.0.0 ## 对客户端提供服务的端口 http.port: 9200 ## 集群内与其他节点交互的端口 transport.tcp.port: 9300 ## 这里的数组成员为各节点的 node.name 值. cluster.initial_master_nodes: - es-01 - es-02 - es-03 ## 配置该节点会与哪些候选地址进行通信. discovery.seed_hosts: - 192.168.80.1:9300 - 192.168.80.2:9300 - 192.168.80.3:9300
基于上面的例子,kubernates增加了headless serivces功能,字面意思无service其实就是改service对外无提供IP。 其实headless service就是普通的Service资源, 且类型为ClusterIP, 只不过把clusterIP字段显示地设置为了None。
apiVersion: v1
kind: Service
metadata:
name: myapp-svc
namespace: default
spec:
selector:
app: myapp
release: canary
clusterIP: None #设置为None,表示启用headless Service
type: ClusterIp #无头服务只支持ClusterIP类型
ports:
- name: http
protocol: TCP
port: 80
targetPort: 80
其他可用设置:会话粘性spec.sessionAffinity: ClientIP|None
apiVersion: v1
kind: Service
metadata:
name: myapp-svc
namespace: default
spec:
selector: #注意Service.spec.selector无需matchLabels或matchExpressions来嵌套
app: myapp
release: canary
clusterIP: 10.97.97.98
type: NodePort
ports:
- name: http
protocol: TCP
port: 80 #Service上的端口
targetPort: 80 #Pod上的端口
nodePort: 30080 #Node上的端口,可用端口范围:30000-32767
使用阿里云的slb:阿里云的k8s集群中有一个系统组件:Cloud Controller Manager(简称CCM),会为Type=LoadBalancer类型的Service创建或配置阿里云负载均衡(SLB),包含SLB、监听、虚拟服务器组等资源。
参考文档:
https://help.aliyun.com/knowledge_detail/142097.html?spm=5176.13910061.0.0.6dc05a49OStyrF
创建一个公网类型的负载均衡:
LoadBalancer创建后,会自动创建一个公网的SLB。
apiVersion: v1
kind: Service
metadata:
labels:
app: nginx-ingress-lb
name: nginx-ingress-lb
namespace: kube-system
spec:
externalTrafficPolicy: Local
ports:
- name: http
port: 80
protocol: TCP
targetPort: 80
- name: https
port: 443
protocol: TCP
targetPort: 443
selector:
app: ingress-nginx
sessionAffinity: None
type: LoadBalancer
使用阿里云事先存在的slb创建LoadBalancer类型的Service:
如果已经实现存在了一个SLB,在创建LoadBalancer类型的SVC时想复用这个SLB,可以通过添加如下注解实现。
apiVersion: v1
kind: Service
metadata:
annotations:
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-address-type: "intranet" ## intranet是私网 internet是公网;缺省时为公网SLB
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-id: "${YOUR_LOADBALACER_ID}" ## 替换为slb id
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-force-override-listeners: "true" ## 强制覆盖已有slb的监听器
labels:
app: nginx-ingress-lb
name: nginx-ingress-lb
namespace: kube-system
spec:
externalTrafficPolicy: Local
ports:
- name: http
port: 80
protocol: TCP
targetPort: 80
- name: https
port: 443
protocol: TCP
targetPort: 443
selector:
app: ingress-nginx
sessionAffinity: None
type: LoadBalancer
注:
alicloud-loadbalancer-address-type: intranet选项指明SLB实例地址类型为私网类型。internet则为公网类型。- ${YOUR_LOADBALACER_ID}为SLB实例ID。
alicloud-loadbalancer-force-override-listeners: 'true'选项自动创建SLB端口监听。(对于指定已有SLB,系统默认不再为该SLB处理监听。可以通过该配置启用)
实战:
需求:新创建的托管版k8s集群,会自动创建一个按量付费的公网的slb。 我想对这个按量付费的slb做一个峰值带宽的限制,比如设置为100M。貌似公网类型的slb没有这方面的设置。 我的方案是:私网的slb+eip。对eip做峰值带宽限制。
解决方案:把原来的kube-system命名空间下的nginx-ingress-lb这个service删掉,参考上例,创建一个yaml,然后重新创建svc。这里有一个坑:上面的这个slb是私有slb,即使绑定了公网eip后,它的类型依然是私网ip,所以service.beta.kubernetes.io/alibaba-cloud-loadbalancer-address-type: "intranet"。建议备份好yaml 在业务不繁忙时操作下 删除会影响已有的ingress不能访问 。
示例:
前提:先手动创建内网slb。获取其id,例如本例为lb-2zeup6j3e0suuymgsj9ch
apiVersion: v1
kind: Service
metadata:
annotations:
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-address-type: intranet
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-force-override-listeners: "true"
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-id: lb-2zeup6j3e0suuymgsj9ch
labels:
app: nginx-ingress-lb
name: nginx-ingress-lb
namespace: kube-system
spec:
externalTrafficPolicy: Local
ports:
- name: http
port: 80
protocol: TCP
targetPort: 80
- name: https
port: 443
protocol: TCP
targetPort: 443
selector:
app: ingress-nginx
sessionAffinity: None
type: LoadBalancer
traefik:
apiVersion: v1
kind: Service
metadata:
annotations:
meta.helm.sh/release-name: traefik
meta.helm.sh/release-namespace: traefik
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-address-type: intranet
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-force-override-listeners: "true"
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-id: lb-2zebweusr0iznwe1843hz
labels:
app.kubernetes.io/instance: traefik
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: traefik
helm.sh/chart: traefik-9.14.2
name: traefik
namespace: traefik
spec:
ports:
- name: web
port: 80
protocol: TCP
targetPort: web
- name: websecure
port: 443
protocol: TCP
targetPort: websecure
selector:
app.kubernetes.io/instance: traefik
app.kubernetes.io/name: traefik
sessionAffinity: None
type: LoadBalancer
我们可以用ExternalName对Service名称和集群外部服务地址做一个映射,使之访问Service名称就是访问外部服务。ExternalName Service 是没有选择器的特殊服务,它没有定义任何端口或端点。
以下面的例子为例,查找主机 mysql-service-domain.default.svc.CLUSTER 时,集群DNS服务将返回值为 mysql.anoyi.com 的一条CNAME记录。访问这种服务的方式与其他服务一样,唯一的区别在于重定向发生在DNS级别,并且没有代理或转发发生。
externalName Service是k8s中一个特殊的service类型,它不需要指定selector去选择哪些pods实例提供服务,而是使用DNS CNAME机制把自己CNAME到你指定的另外一个域名上,也可以提供集群内的名字,比如mysql.db.svc这样的建立在db命名空间内的mysql服务,也可以指定http://mysql.example.com这样的外部真实域名。
kind: Service
apiVersion: v1
metadata:
name: mysql
namespace: databases
spec:
type: ExternalName
externalName: rm-2zecbr40735wh172y.mysql.rds.aliyuncs.com #将Service映射到指定的外部DNS名称,该名称会被k8s-dns解析为一个外部服务的CNAME记录。
root@test-749fdc9984-bjngh:/# dig -t A mysql.databases.svc.cluster.local @172.21.0.10
; <<>> DiG 9.11.5-P4-5.1+deb10u2-Debian <<>> -t A mysql.databases.svc.cluster.local @172.21.0.10
;; global options: +cmd
;; Got answer:
;; WARNING: .local is reserved for Multicast DNS
;; You are currently testing what happens when an mDNS query is leaked to DNS
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 24687
;; flags: qr aa rd; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
; COOKIE: 44fb8a962c38e4a6 (echoed)
;; QUESTION SECTION:
;mysql.databases.svc.cluster.local. IN A
;; ANSWER SECTION:
mysql.databases.svc.cluster.local. 30 IN CNAME rm-2zecbr40735wh172y.mysql.rds.aliyuncs.com. #此处解析为CNAME记录
rm-2zecbr40735wh172y.mysql.rds.aliyuncs.com. 30 IN A 172.17.252.168
;; Query time: 1 msec
;; SERVER: 172.21.0.10#53(172.21.0.10)
;; WHEN: Thu Jan 28 01:10:07 UTC 2021
;; MSG SIZE rcvd: 223
不过,ExternalName 类型的服务适用于外部服务使用域名的方式。另外,要实现集群内访问集群外服务的这个需求,也是非常简单的。因为集群内的Pod会继承Node上的DNS解析规则。因此只要Node可以访问的服务,Pod中也可以访问到。
1、如果DNS add-on存在,那么每当Service创建完,都会在集群dns中自动动态插入一条资源记录,添加后我们就可以直接解析服务名。资源记录格式如下:
格式:SVC_NAME.NameSpace_NAME.DOMAIN.LTD.
默认的域名后缀:svc.cluster.local.
pod内默认的搜索域:NameSpace_NAME.svc.cluster.local svc.cluster.local cluster.local
所以redis服务的服务名示例:
redis
redis.default
redis.default.svc
redis.default.svc.cluster.local.
2、流量不会从Service直接到Pod的,它中间还会经过另一个k8s的标准对象EndPoints(本质是IP:Port)。
coredns 自带 hosts 插件, 允许像配置 hosts 一样配置自定义 DNS 解析,修改 kube-system 中 configMap 的 coredns 添加如下设置即可。
hosts {
192.168.6.124 harbor.ljzsdut.com notary.harbor.ljzsdut.com
192.168.6.125 harbor.ljzsdut.com notary.harbor.ljzsdut.com
fallthrough
}
修改后文件如下:
]# cc-main kubectl get cm coredns -n kube-system -o yaml
apiVersion: v1
data:
Corefile: |
.:53 {
errors
health
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
hosts {
192.168.6.124 harbor.ljzsdut.com notary.harbor.ljzsdut.com
192.168.6.125 harbor.ljzsdut.com notary.harbor.ljzsdut.com
fallthrough
}
prometheus :9153
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
kind: ConfigMap
metadata:
creationTimestamp: "2019-11-11T04:09:35Z"
name: coredns
namespace: kube-system
resourceVersion: "2939186"
selfLink: /api/v1/namespaces/kube-system/configmaps/coredns
uid: a5042c71-a923-42df-9b45-b33f4d302d03
无需重启coredns,自动生效。
Pod的hosts文件具有特定的模板,一般不直接修改。我们可以通过 spec.HostAliases 向 hosts 文件添加增加额外的条目:
apiVersion: v1
kind: Pod
metadata:
name: hostaliases-pod
spec:
restartPolicy: Never
hostAliases:
- ip: "127.0.0.1"
hostnames:
- "foo.local"
- "bar.local"
- ip: "10.1.2.3"
hostnames:
- "foo.remote"
- "bar.remote"
containers:
- name: cat-hosts
image: busybox
command:
- cat
args:
- "/etc/hosts"
kind: Service
apiVersion: v1
metadata:
name: mysql
namespace: databases
spec:
ports:
- port: 3306
name: mysql
targetPort: 3306
---
kind: Endpoints
apiVersion: v1
metadata:
name: mysql
namespace: databases
subsets:
- addresses:
- ip: 10.15.9.211
ports:
- port: 3306
name: mysql
