7.1 K8s网络插件之flannel&canal
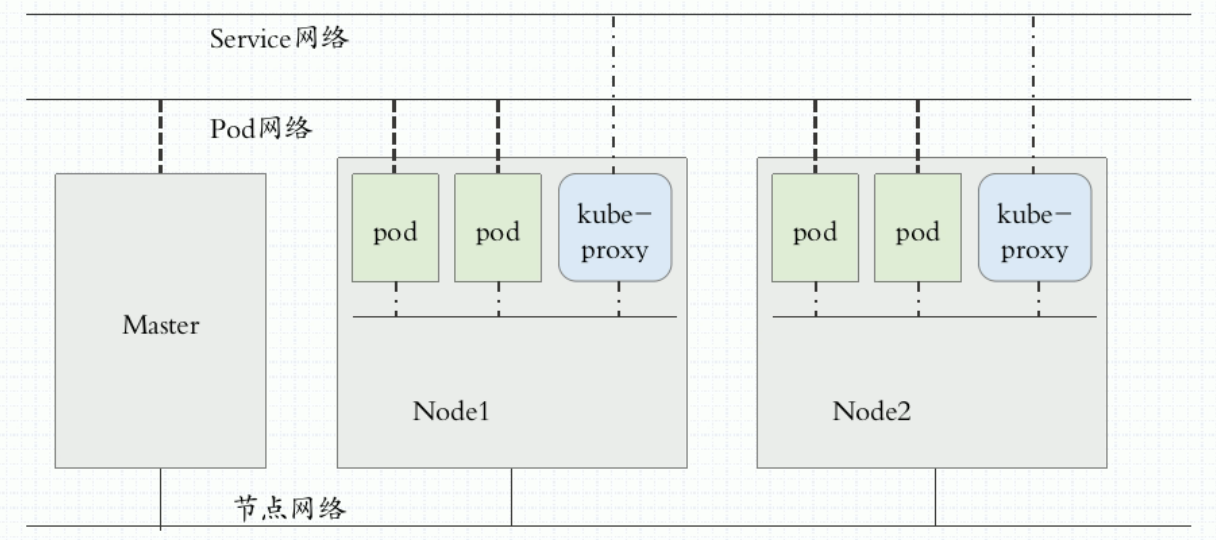
k8s网络模型要求k8s集群要有3种网络,分别处于不同的网段:
- 节点网络:node network ,是各主机(Master、Node和etcd等)自身所属的网络,其地址配置于主机的网络接口,用于各主机之间的通信,例如Master与各Node之间的通信。此地址配置于Kubernetes集群构建之前,它并不能由Kubernetes管理,管理员需要于集群构建之前自行确定其地址配置及管理方式。
- Pod网路:pod network,配置在pod上。所有的Pod运行在同一个网络中。是Kubernetes集群上专用于Pod资源对象的网络,它是一个虚拟网络,用于为各Pod对象设定IP 地址等网络参数,其地址配置于Pod中容器的网络接口之上。Pod网络需要借助kubenet插件或CNI插件实现,该插件可独立部署于Kubernetes集群之外,亦可托管于Kubernetes 之上,它需要在构建Kubernetes集群时由管理员进行定义,而后在创建Pod对象时由其自动完成各网络参数的动态配置。
- 集群网络:service network,是专用于Service资源对象的网络,它也是一个虚拟网络,用于为Kubernetes集群之中的Service配置IP 地址,但此地址并不配置于任何主机或容器的网络接口之上,而是通过Node之上的kube-proxy配置为iptables 或ipvs规则,从而将发往此地址的所有流量调度至其后端的各Pod对象之上。Service网络在Kubernetes集群创建时予以指定,而各Service的地址则在用户创建Service时予以动态配置。
外部访问:节点网络–>集群网络–>pod网络
- 同一个Pod内多个容器间通信:通过lo网卡通信
- 各pod之间的通信;k8s要求Pod与Pod之间通信要求通过IP直达,因此所有Pod应处于一同一个网络内,所以一个k8s集群内所有pod的IP不能相同。
- Pod1和Pod2不在同一个Node上:Pod的地址是与docker0网桥(网关)在同一个网段的,但docker0网段与宿主机网卡是两个完全不同的网段,并且不同Node间通信只能通过宿主机的物理网卡进行。将Pod的IP和所在的Node的IP关联起来(例如flannel的overlay network),通过这个关联让Pod可以相互访问。
- Pod1和Pod2在同一个Node上:由Docker0网桥直接转发请求到Pod2,不需要经过Flannel等网络插件。
- Pod与Service之间的通信;Pod IP与Cluster IP通信;两者处于不同的网路,需要为pod配置网关例如docker0网桥(k8s自动实现),然后pod通过网关转发报文到Service,Service内部就可以通过iptables或ipvs实现与后端pod通信
- Service与集群外部客户端的通信;外网访问Pod,通过ingress、LoadBanlance、NodePort实现;Pod想外网发送请求,查找路由表,转发数据包到宿主机网卡,宿主机网卡完成路由选择后,iptables执行Masquerade,把源IP更改为宿主机的网卡IP,然后向外网服务器发送请求。
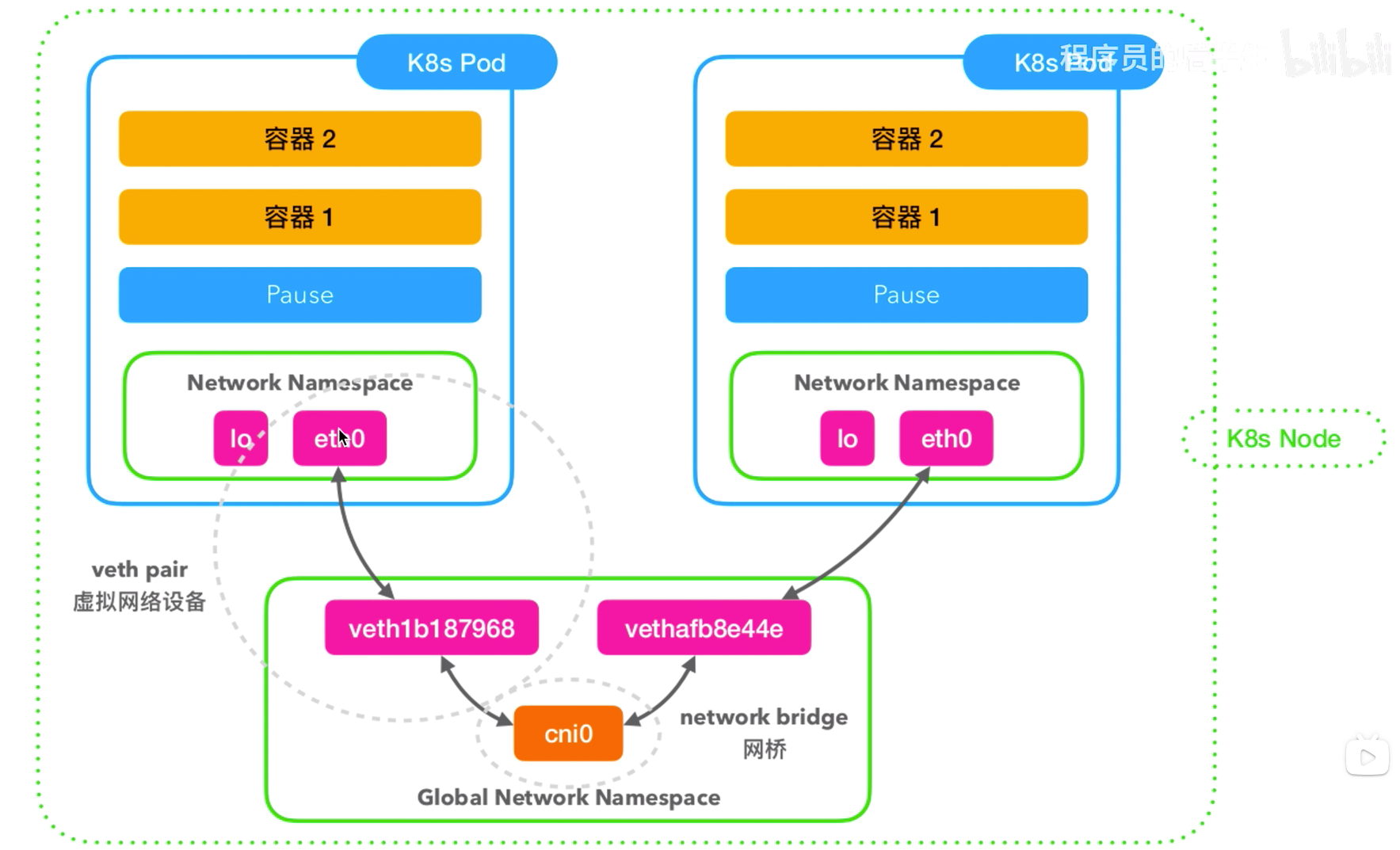
Pod间网络通信主要依赖于2个网络设备。
虚拟网桥:类似于交换机,位于宿主机的网络名称空间中。其上的一个端口可以将请求发送到其上的另一个端口。使用
brctl show可以查看宿主机虚拟网桥上连接的设备(interfaces)。虚拟网络设备veth pair:类似于一根网线,所有从这跟网线一端进入的数据包都将从另一端出来,反之也是一样。其一端在接入到Pod的网络名称空间中;另一端接入到宿主机的网络名称空间中 ;此外,接入到宿主机网络名称空间这个端又接入到了虚拟网桥中(例如cni0)。查看除了宿主机的网络名称空间外的其他名称空间,也就是各个Pod的名称空间,可以使用
ip netns list查看。
所以:
同一个Node上的不同Pod间通信时,例如Pod1(上图中左边的Pod)访问右边Pod2(上图中右边的Pod),2个Pod处于同一个网段中,可以通过交换机直接访问,此处的交换机就是cni0这个虚拟网桥。Pod1的报文经过eth0网卡后,到达cni0的一个端口上(veth1b187968),通过虚拟网桥会转发到另一个端口上(vethafb8e44e),此时,Pod2的eth0网卡就收到该报文了。
演示:
# 在宿主机上随便进入一个pod,查看网卡信息
[root@iZ2zehld5mqm155c5i504aZ ~]# docker exec -it aa9317d9a52f ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
3: eth0@if49: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP
link/ether ca:eb:f6:28:5d:c1 brd ff:ff:ff:ff:ff:ff
inet 172.20.1.195/24 brd 172.20.1.255 scope global eth0
valid_lft forever preferred_lft forever
# 上图中,eth0@if49表示,这个网卡的对端连接到宿主机的49号网卡上。
#查看宿主机的49号网卡:
[root@iZ2zehld5mqm155c5i504aZ ~]# ip a |grep -A 1 '^49:'
49: -: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master cni0 state UP group default
link/ether aa:58:d6:99:75:ce brd ff:ff:ff:ff:ff:ff link-netnsid 42
通过抓包验证报文的传递:
#查看Pod1的ip,为172.20.1.195
[root@iZ2zehld5mqm155c5i504aZ ~]# docker exec -it aa9317d9a52f ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
3: eth0@if49: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP
link/ether ca:eb:f6:28:5d:c1 brd ff:ff:ff:ff:ff:ff
inet 172.20.1.195/24 brd 172.20.1.255 scope global eth0
valid_lft forever preferred_lft forever
#查看Pod2的ip,为172.20.1.176
[root@iZ2zehld5mqm155c5i504aZ ~]# docker exec -it e49b787d3286 sh ip a
sh: can't open 'ip': No such file or directory
[root@iZ2zehld5mqm155c5i504aZ ~]# docker exec -it e49b787d3286 ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
3: eth0@if32: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP
link/ether 2e:18:da:32:6f:0c brd ff:ff:ff:ff:ff:ff
inet 172.20.1.176/24 brd 172.20.1.255 scope global eth0
valid_lft forever preferred_lft forever
#在宿主机上使用tcpdump工具对49号网卡的icmp协议进行抓包
[root@iZ2zehld5mqm155c5i504aZ ~]# tcpdump -nn -i veth47097500 icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on veth47097500, link-type EN10MB (Ethernet), capture size 262144 bytes
#我们在Pod1(aa9317d9a52f)中向Pod2(e49b787d3286)发送ping请求2次
/usr/share/nginx/html/release # ping -c 2 172.20.1.176
PING 172.20.1.176 (172.20.1.176): 56 data bytes
64 bytes from 172.20.1.176: seq=0 ttl=64 time=0.076 ms
64 bytes from 172.20.1.176: seq=1 ttl=64 time=0.057 ms
--- 172.20.1.176 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 0.057/0.066/0.076 ms
#查看tcpdump抓包的情况:发现确实是2个请求的4次报文
[root@iZ2zehld5mqm155c5i504aZ ~]# tcpdump -nn -i veth47097500 icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on veth47097500, link-type EN10MB (Ethernet), capture size 262144 bytes
15:43:55.413040 IP 172.20.1.195 > 172.20.1.176: ICMP echo request, id 8704, seq 0, length 64
15:43:55.413083 IP 172.20.1.176 > 172.20.1.195: ICMP echo reply, id 8704, seq 0, length 64
15:43:56.413125 IP 172.20.1.195 > 172.20.1.176: ICMP echo request, id 8704, seq 1, length 64
15:43:56.413153 IP 172.20.1.176 > 172.20.1.195: ICMP echo reply, id 8704, seq 1, length 64
# 我们可以同样地对Pod2对应在宿主机的32号网卡进行转包
[root@iZ2zehld5mqm155c5i504aZ ~]# ip a |grep -A 1 '^32:'
32: veth0e921722@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master cni0 state UP group default
link/ether 32:8f:ee:9c:d0:f8 brd ff:ff:ff:ff:ff:ff link-netnsid 25
[root@iZ2zehld5mqm155c5i504aZ ~]# tcpdump -nn -i veth0e921722 icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on veth0e921722, link-type EN10MB (Ethernet), capture size 262144 bytes
15:49:56.673430 IP 172.20.1.195 > 172.20.1.176: ICMP echo request, id 8960, seq 0, length 64
15:49:56.673448 IP 172.20.1.176 > 172.20.1.195: ICMP echo reply, id 8960, seq 0, length 64
15:49:57.673505 IP 172.20.1.195 > 172.20.1.176: ICMP echo request, id 8960, seq 1, length 64
15:49:57.673523 IP 172.20.1.176 > 172.20.1.195: ICMP echo reply, id 8960, seq 1, length 64
# 在虚拟网桥上镜像抓包
[root@iZ2zehld5mqm155c5i504aZ ~]# tcpdump -nn -i cni0 icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on cni0, link-type EN10MB (Ethernet), capture size 262144 bytes
15:56:46.307169 IP 172.20.1.195 > 172.20.1.176: ICMP echo request, id 9472, seq 0, length 64
15:56:46.307207 IP 172.20.1.176 > 172.20.1.195: ICMP echo reply, id 9472, seq 0, length 64
15:56:47.307273 IP 172.20.1.195 > 172.20.1.176: ICMP echo request, id 9472, seq 1, length 64
15:56:47.307301 IP 172.20.1.176 > 172.20.1.195: ICMP echo reply, id 9472, seq 1, length 64
# 在pod2内抓包:
[root@iZ2zehld5mqm155c5i504aZ ~]# docker exec -it e49b787d3286 sh
/usr/share/nginx/html/release # tcpdump -nn -i eth0 icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
07:55:50.385043 IP 172.20.1.195 > 172.20.1.176: ICMP echo request, id 9216, seq 0, length 64
07:55:50.385059 IP 172.20.1.176 > 172.20.1.195: ICMP echo reply, id 9216, seq 0, length 64
07:55:51.385107 IP 172.20.1.195 > 172.20.1.176: ICMP echo request, id 9216, seq 1, length 64
07:55:51.385123 IP 172.20.1.176 > 172.20.1.195: ICMP echo reply, id 9216, seq 1, length 64
至此,我们可以发现2个Pod间的报文经过的网络设备,已经能够全部抓到包了。
不同Node上Pod之间通信有2种方案:
- 覆盖网络方案:例如flannel,将pod网络的包封装成节点网络的包,到达目标节点后,再捷报还原成pod网络的包。 特点:不依赖于底层网络,但有封包解包的性能开销
- 路由方案:例如calico。特点:依赖于底层网络设备,但性能开销小。
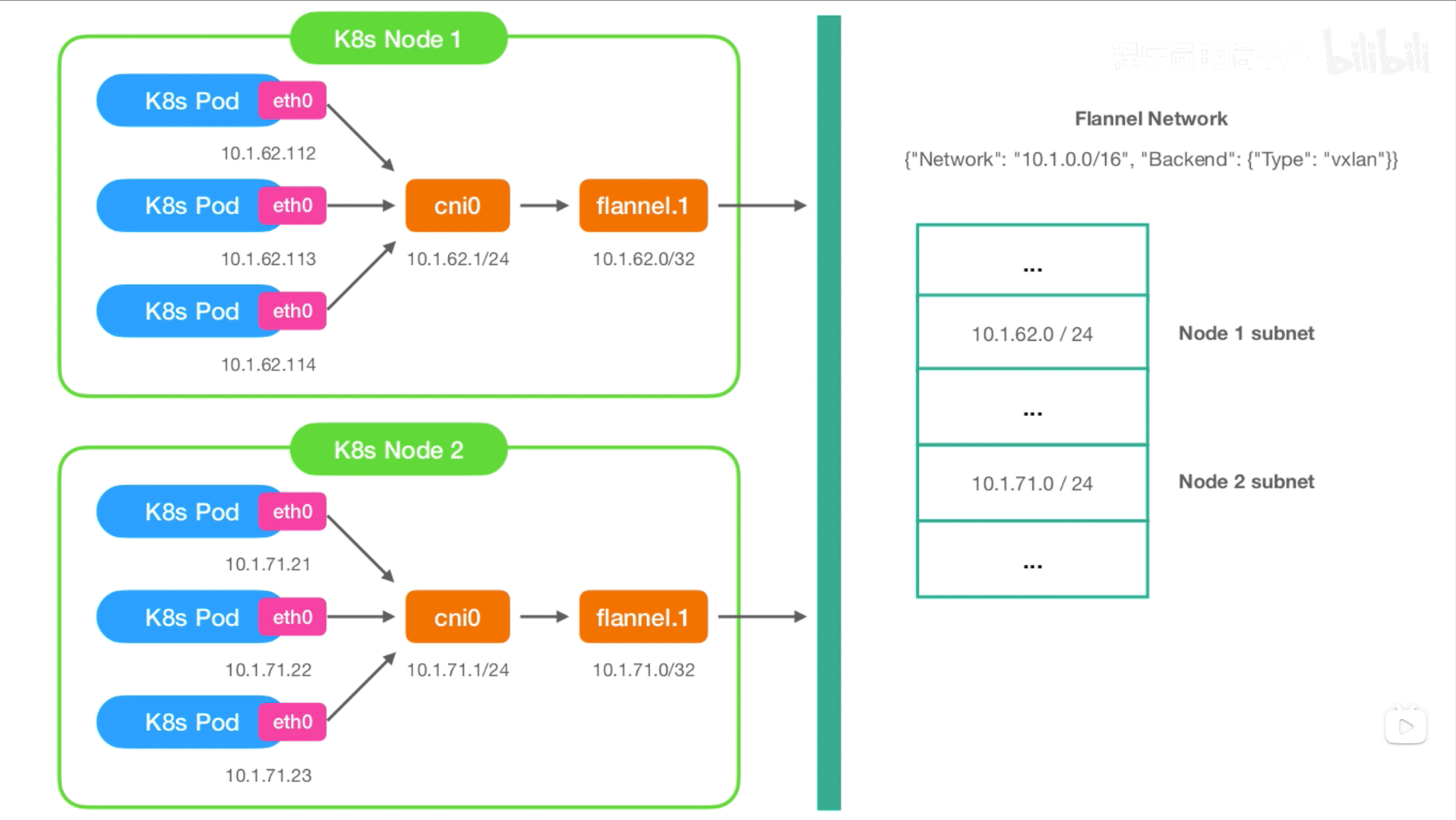
Flannel:
1、跨主机Pod间通信,flannel通过修改宿主机的路由,将报文发送到flannel.1虚拟网卡。
2、flannel会对到达flannel.1虚拟网卡的报文进行overlay封装。
3、到达目标宿主机的flannel.1网卡后,flannel会对overlay报文解包。
k8s自身不提供网络解决方案,它允许使用任何的第三方网络解决方案来实现,其网络实现是通过网络插件CNI实现的。第三方网络解决方案一般至少要实现pod网络和Service网络的管理。CNI既可以宿主机上的daemon运行,也可以以pod形式运行(但需要使用-n=host参数与宿主机节点共享网络名称空间)。
解决方案有:虚拟网桥、多路复用(MacVLAN)、硬件交换(SR-IOV,单根IO虚拟化),具体实现有:
- flannel:网络配置(例如分配ip等)
- calico:网络配置+网络策略(例如实现多租户网络隔离)
- canal:calico+flannel的结合体
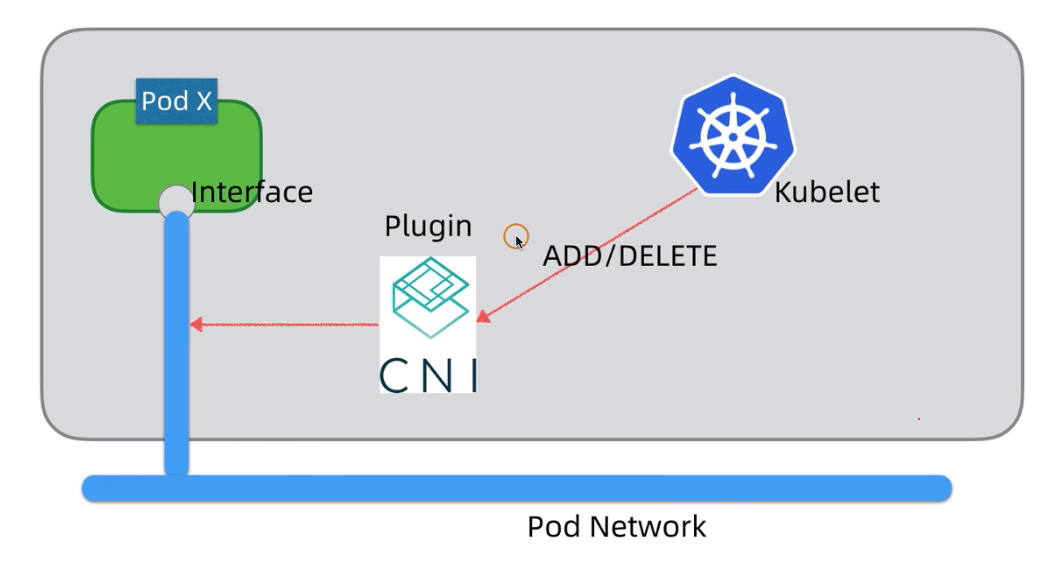
考虑到k8s的网络实现众多,为了简化集成,k8s支持CNI标准,不同的网络实现通过CNI以插件的形式和k8s进行集成。kubelet通过cni接口去操作Pod网络,比如添加/删除pod网络接口。
https://blog.csdn.net/liukuan73/article/details/78883847
https://blog.csdn.net/jessicaiu/article/details/84661243
直接在kubelet的配置文件中提供相应的配置(默认的CNI配置目录为/etc/cni/net.d),将cni插件的配置文件放在该目录下即可,该配置文件会被识别并加载为网络插件使用。当然也可以在kubelet的启动参数指定cni配置文件目录:/opt/kube/bin/kubelet --cni-bin-dir=/opt/kube/bin --cni-conf-dir=/etc/cni/net.d --network-plugin=cni
[root@k8smaster ~]# ls /etc/cni/net.d/
10-flannel.conflist
[root@k8smaster ~]# cat /etc/cni/net.d/10-flannel.conflist
{
"name": "cbr0",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
kubelet加载上面的配置文件后,必要时被kubelet将网络插件创建为一个Pod,这个pod有网络和网卡。这个网络和网卡是怎么生成的呢?kubelet会调用这个配置文件指定的网络插件,由网络插件代为实现地址分配、接口创建、网络创建等。
[root@iZ2zehld5mqm155c5i504aZ ~]# docker ps |grep flannel
c6a773e004fd 8caa9d51289e "/opt/bin/flanneld -…" 3 weeks ago Up 3 weeks k8s_kube-flannel_kube-flannel-ds-q4ttq_kube-system_da648036-072a-4823-b8d9-3a3967ea502f_1
a5e3e08533bb registry-vpc.cn-beijing.aliyuncs.com/acs/pause:3.2 "/pause" 3 weeks ago Up 3 weeks k8s_POD_kube-flannel-ds-q4ttq_kube-system_da648036-072a-4823-b8d9-3a3967ea502f_1
推荐阅读:
flannel默认使用VxLAN(扩展的虚拟局域网)方式作为后端网路传输机制。此外还支持host-gw(Host GateWay,主机网关)
flannel的后端backend实现:
- VxLAN:扩展的虚拟局域网(原生的VxLAN+host-gw)
- 原生的VxLAN
- Directrouting: true 启用同网络Node间通信使用host-gw模式,跨网段Node间通信使用VxLAN
- host-gw,最简单的backend实现。性能最好,但是多个宿主机不能跨网段
- UDP,性能最差,基本弃用。要求所有的主机都在一个子网内,即二层可达,否则就无法将目的主机当做网关,直接路由。
flannel如何启用Directrouting?
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan",
"Directrouting": true #添加此行
}
}
IPIP:ipip是在宿主机网络不完全支持bgp时,一种妥协的overlay机制,在宿主机创建1个”tunl0”虚拟端口;
- 设置为false时,路由即纯bgp模式,理论上ipip模式的网络传输性能低于纯bgp模式;
- 设置为true时,又分ipip always模式(纯ipip模式)与ipip cross-subnet模式(ipip-bgp混合模式)
- Always模式:纯ipip模式
- cross-subnet模式:指“同子网内路由采用bgp,跨子网路由采用ipip”
选择工作模式(CALICO_IPV4POOL_IPIP),支持BGP(Never)、IPIP(Always)、CrossSubnet(开启BGP并支持跨子网)
#如何将IPIP修改为CrossSubnet?
#第1步:
kubectl edit ds calico-node -n kube-system
- name: CALICO_IPV4POOL_IPIP
value: Always|CrossSubnet|Never
#第2步:
kubectl edit ippools default-ipv4-ippool -o yaml
spec:
blockSize: 26
cidr: 10.42.0.0/16
ipipMode: CrossSubnet #修改此处
natOutgoing: true
nodeSelector: all()
vxlanMode: Never
修改现有k8s集群中的calico网络,默认是ipip模式(在每台node主机创建一个tunl0网口,这个隧道链接所有的node容器网络,官网推荐不同的ip网段适合,比如aws的不同区域主机),修改成BGP模式,它会以daemonset方式安装在所有node主机,每台主机启动一个bird(BGP client),它会将calico网络内的所有node分配的ip段告知集群内的主机,并通过本机的网卡eth0或者ens160转发数据;
修改下默认集群为ipip模式的k8s集群:
kubectl edit -n kube-system daemonset.extensions/calico-node #编辑calico-node的daemonset
修改
- name: CALICO_IPV4POOL_IPIP #ipip模式关闭
value: "off"
- name: FELIX_IPINIPENABLED #felix关闭ipip
value: "false"
修改之后,集群会自动生效:
原有的tunl0接口会在主机重启后消失(不重启也不会影响效果)
networkpolicy简称netpol,类似于OS的防火墙规则,控制Pod/namespace之间的访问规则。
https://docs.projectcalico.org/v3.7/getting-started/kubernetes/installation/calico
**Installing Calico for policy and flannel for networking with the Kubernetes API datastore **
Ensure that the Kubernetes controller manager has the following flags set:
--cluster-cidr=10.244.0.0/16and--allocate-node-cidrs=true.Tip: If you’re using kubeadm, you can pass
--pod-network-cidr=10.244.0.0/16to kubeadm to set the Kubernetes controller flags.If your cluster has RBAC enabled, issue the following command to configure the roles and bindings that Calico requires.
kubectl apply -f \ https://docs.projectcalico.org/v3.2/getting-started/kubernetes/installation/hosted/canal/rbac.yamlNote: You can also view the manifest in your browser.
Issue the following command to install Calico.
kubectl apply -f \ https://docs.projectcalico.org/v3.2/getting-started/kubernetes/installation/hosted/canal/canal.yamlNote: You can also view the manifest in your browser.
If you wish to enforce application layer policies and secure workload-to-workload communications with mutual TLS authentication, continue to Enabling application layer policy (optional).
#准备名称空间和相关的测试Pod:
[root@k8smaster networkpolicy]# kubectl create ns dev
namespace/dev created
[root@k8smaster networkpolicy]# kubectl create ns prod
namespace/prod created
[root@k8smaster networkpolicy]# cat pod-a.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod1
labels:
app: myapp
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
[root@k8smaster networkpolicy]# kubectl apply -f pod-a.yaml -n dev
pod/pod1 created
[root@k8smaster networkpolicy]# kubectl apply -f pod-a.yaml -n prod
pod/pod1 created
[root@k8smaster networkpolicy]# kubectl get pod -o wide -n dev
NAME READY STATUS RESTARTS AGE IP NODE
pod1 1/1 Running 0 29s 10.244.2.3 k8snode02
[root@k8smaster networkpolicy]# kubectl get pod -o wide -n prod
NAME READY STATUS RESTARTS AGE IP NODE
pod1 1/1 Running 0 40s 10.244.1.3 k8snode01
[root@k8smaster networkpolicy]# curl 10.244.2.3
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
[root@k8smaster networkpolicy]# curl 10.244.1.3
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
#以上命令创建了两个名称空间,并在两个名称空间中各创建了一个pod,通过在master上访问各个名称空间中的Pod,发现都可以访问到。
#创建NetworkPolicy:拒绝访问dev中的所有Pod
[root@k8smaster networkpolicy]# cat ingress-deny-all.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: deny-all-ingress
spec:
podSelector: {} #表示所有的Pod
policyTypes:
- Ingress #表示启用Ingress规则,但是Ingress规则未定义任何规则,所以Ingress为拒绝所有
[root@k8smaster networkpolicy]# kubectl apply -f ingress-deny-all.yaml -n dev
networkpolicy.networking.k8s.io/deny-all-ingress created
[root@k8smaster networkpolicy]# curl 10.244.2.3
^C #请求被阻塞了,无法访问dev中的Pod
[root@k8smaster networkpolicy]# curl 10.244.1.3
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a> #prod中的Pod可以访问
#创建NetworkPolicy:10.244.0.0/16网段中除10.244.1.2/32外的所有IP允许访问app=myapp的Pod的80和443端口。
[root@k8smaster networkpolicy]# cat allow-ipBlock-demo.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-myapp-ingress
spec:
podSelector:
matchLabels:
app: myapp
ingress:
- from:
- ipBlock:
cidr: 10.244.0.0/16
except:
- 10.244.1.2/32
ports:
- protocol: TCP
port: 80
- protocol: TCP
port: 443
[root@k8smaster networkpolicy]# kubectl apply -f allow-ipBlock-demo.yaml -n dev
networkpolicy.networking.k8s.io/allow-myapp-ingress created
[root@k8smaster networkpolicy]# curl 10.244.2.3
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
[root@k8smaster networkpolicy]# curl 10.244.1.3
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
[root@k8smaster networkpolicy]# curl 10.244.2.3:443
curl: (7) Failed connect to 10.244.2.3:443; Connection refused #请求被linux内核拒绝了,而不是被阻塞。说明请求已经到达Pod,但是没有监听443端口,所有linux内核将请求拒绝了。
[root@k8smaster networkpolicy]# curl 10.244.2.3:6443
^C #请求被阻塞,说明请求根据就没有到达Pod。
#在dev名称空间中定义一个没有app=myapp标签的Pod
[root@k8smaster networkpolicy]# cat pod-b.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod2
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
[root@k8smaster networkpolicy]# kubectl apply -f pod-b.yaml -n dev
pod/pod2 created
[root@k8smaster networkpolicy]# kubectl get pods -n dev -o wide --show-labels
NAME READY STATUS RESTARTS AGE IP NODE LABELS
pod1 1/1 Running 0 20m 10.244.2.3 k8snode02 app=myapp
pod2 1/1 Running 0 1m 10.244.2.4 k8snode02 <none>
[root@k8smaster networkpolicy]# curl 10.244.2.4
^C #拒绝访问
[root@k8smaster networkpolicy]# curl 10.244.2.3
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a> #允许访问
#名称空间dev中有多个NetworkPolicy,他们哪个优先生效呢?
[root@k8smaster networkpolicy]# kubectl get netpol -n dev
NAME POD-SELECTOR AGE
allow-myapp-ingress app=myapp 5m
deny-all-ingress <none> 19m
[root@k8smaster networkpolicy]# curl 10.244.2.4
^C #此时,无法访问
[root@k8smaster networkpolicy]# kubectl delete -f ingress-deny-all.yaml -n dev
networkpolicy.networking.k8s.io "deny-all-ingress" deleted
[root@k8smaster networkpolicy]# curl 10.244.2.4
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a> #删除“拒绝所有ingress”,可以访问
[root@k8smaster networkpolicy]# kubectl apply -f ingress-deny-all.yaml -n dev
networkpolicy.networking.k8s.io/deny-all-ingress created
[root@k8smaster networkpolicy]# curl 10.244.2.4
^C #创建“拒绝所有ingress”,无法访问
#总结: 同一个名称空间中有多个NetworkPolicy,其优先生效规则跟创建顺序无关。生效策略为最小最优最佳匹配规则。所以我们在使用NetworkPolicy时,可以先配置一个默认策略,然后在默认策略的基础上定义细化的策略。
**几个NetworkPolicy资源配置文件示例: **
[root@k8smaster networkpolicy]# cat ingress-allow-all.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-ingress
spec:
podSelector: {} #表示所有的Pod,当然只对指定名称空间中的Pod生效
ingress: #定义ingress规则
- {} #{}表示入站允许所有规则,这些规则会被应用到podSelector匹配的pod上;如果ingress字段未定义,则表示没有规则,即禁止所有traffic
policyTypes:
- Ingress #表示生效规则为Ingress;Egress未写,表示不启用Egress规则,默认允许。
[root@k8smaster networkpolicy]# cat ingress-deny-all.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: deny-all-ingress
spec:
podSelector: {} #表示所有的Pod:pod选择器,基于标签选择与Network Policy处于同一namespace下的pod,如果pod被选中,则对其应用Network Policy中定义的规则。此为可选字段,当没有此字段时,表示选中所有pod。
policyTypes:
- Ingress #表示启用Ingress规则,但是Ingress规则未定义任何规则,所以Ingress为拒绝所有
#ingress: #定义ingress规则
[root@k8smaster networkpolicy]# cat allow-ipBlock-demo.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-myapp-ingress
spec:
podSelector:
matchLabels:
app: myapp
ingress:
- from:
- ipBlock:
cidr: 10.244.0.0/16
except:
- 10.244.1.2/32
ports:
- protocol: TCP
port: 80
- protocol: TCP
port: 443
[root@k8smaster networkpolicy]# cat egress-deny-all.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: deny-all-egress
spec:
podSelector: {}
policyTypes:
- Egress