001 Calico参考架构
原文:https://tanzu.vmware.com/developer/guides/container-networking-calico-refarch/
Calico 是一个 CNI 插件,为 Kubernetes 集群提供容器网络。它使用 Linux 原生工具来促进流量路由和执行网络策略。它还托管一个 BGP 守护进程,用于将路由分发到其他节点。Calico 的工具作为 DaemonSet 在 Kubernetes 集群上运行。这使管理员能够安装 Calico, kubectl apply -f ${CALICO_MANIFESTS}.yaml而无需设置额外的服务或基础设施。
- 使用 Kubernetes 数据存储。
- 安装 Typha 以确保数据存储可扩展性。
- 对单个子网集群不使用封装。
- 对于多子网集群,在 CrossSubnet 模式下使用 IP-in-IP。
- 根据网络 MTU 和选择的路由模式配置 Calico MTU。
- 为能够增长到 50 个以上节点的集群添加全局路由反射器。
- 将 GlobalNetworkPolicy 用于集群范围的入口和出口规则。通过添加 namespace-scoped 来修改策略NetworkPolicy。
[root@k8s-1 ~]# kubectl get pods -o wide -A| grep calico
kube-system calico-kube-typha-69496dddsde 1/1 Running 1 123d 10.244.231.129 k8s-1 <none> <none>
kube-system calico-kube-controllers-69496d8b75-tvgzw 1/1 Running 1 123d 10.244.231.199 k8s-1 <none> <none>
kube-system calico-node-ktrhr 1/1 Running 1 123d 172.12.1.11 k8s-1 <none> <none>
kube-system calico-node-m8n5d 1/1 Running 1 123d 172.12.1.12 k8s-2 <none> <none>
[root@k8s-1 ~]#
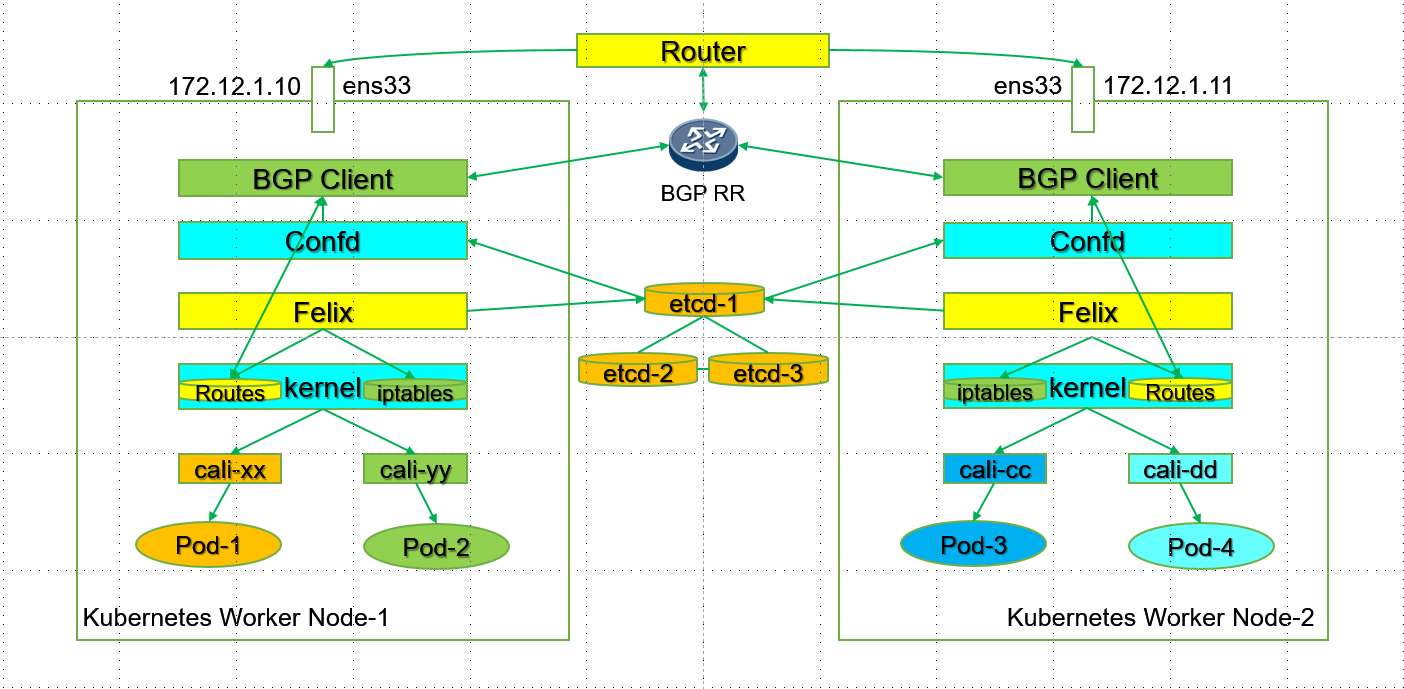
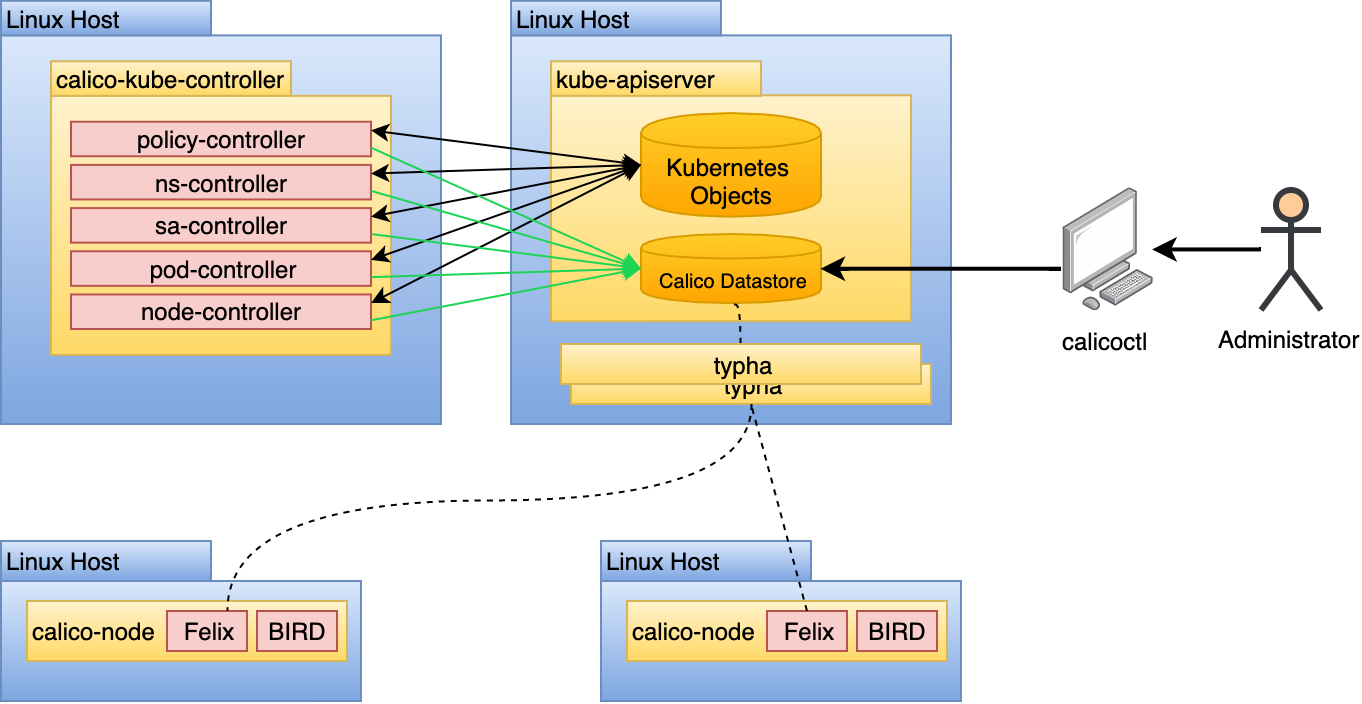
用于数据存储可扩展性。可选。
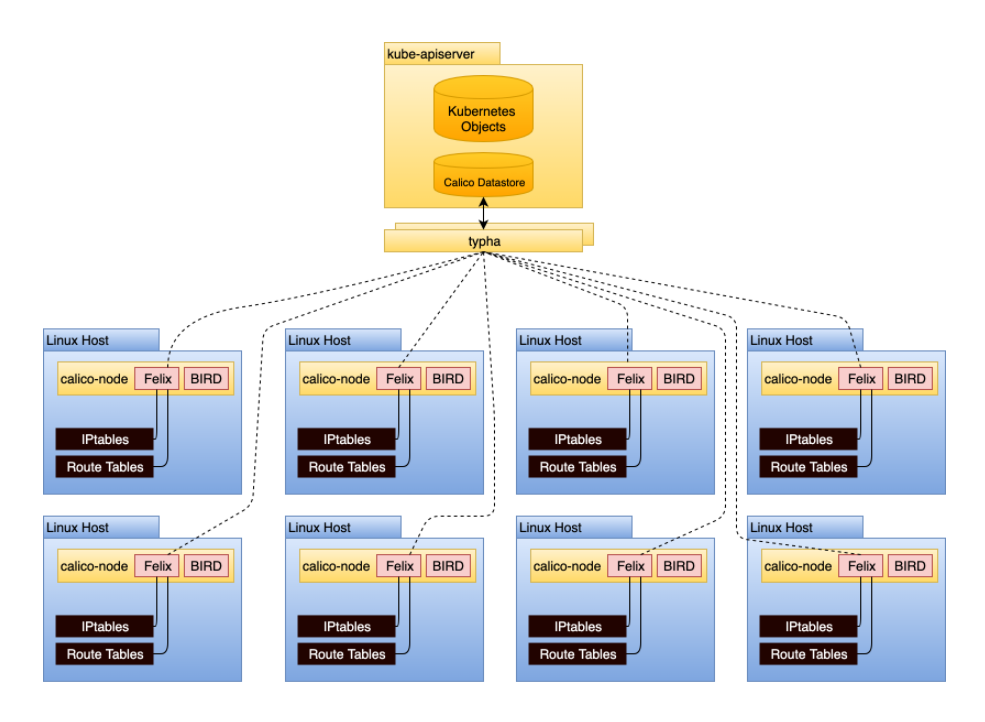
Typha 是一个将配置扇出到集群中所有 calico-node 实例的进程。它充当缓存,可以从 API 服务器中删除重复事件,从而显着减轻负载。随着 Calico 数据存储的更改,这些更改必须传播到 calico-node 的每个实例,可能是数百或数千个实例。这会在具有 50 多个节点的集群中产生扩展问题,因为每个节点都将监视 API 服务器事件。 Typha 通过作为 API 服务器和 calico-node 的所有实例之间的中介来解决这个问题。
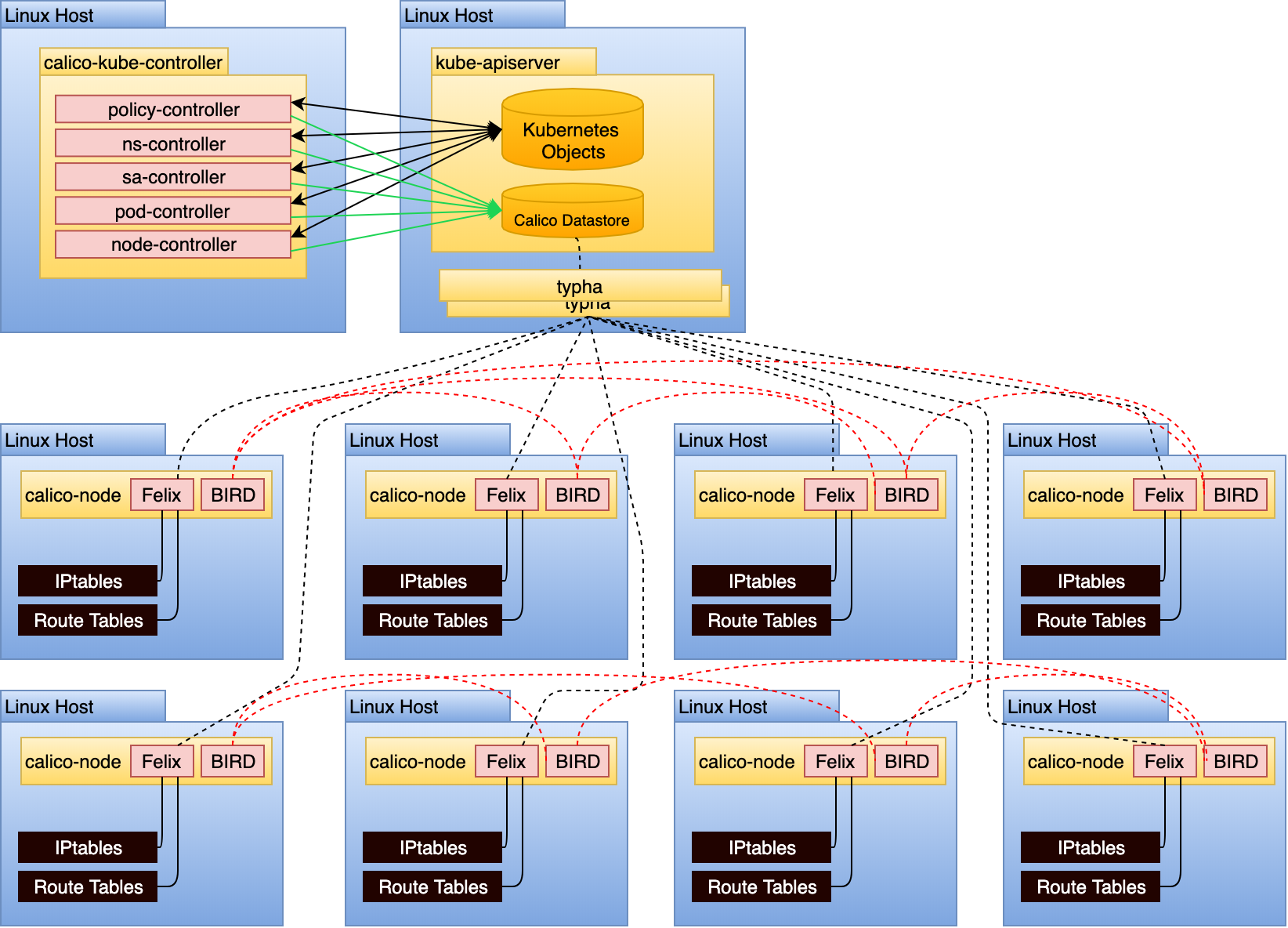
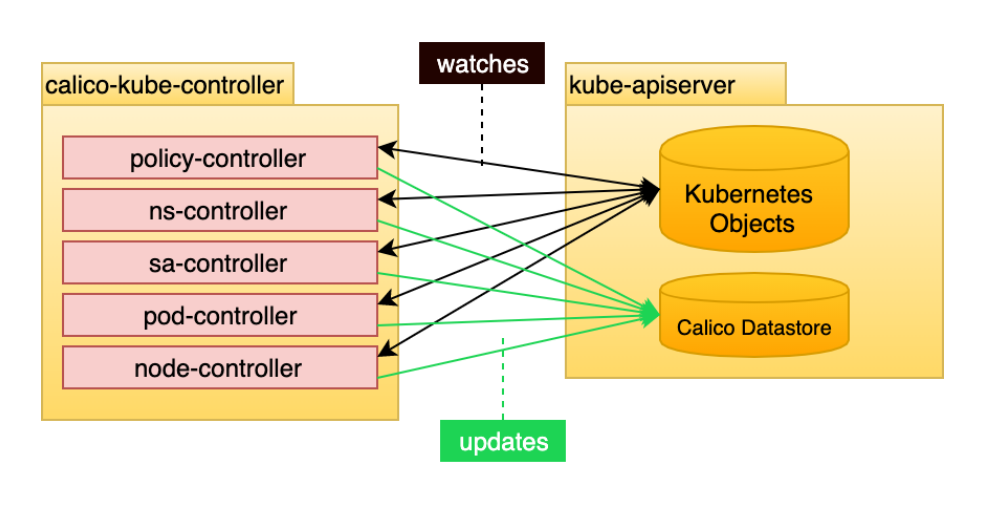
calico-kube-controller 负责识别影响路由变化的Kubernetes对象。控制器内部包含多个控制器:
- policy-controller
- ns-controller
- sa-controller
- pod-controller
- node-controller
这些控制器主要watch如下对象的变化:
- Network Policies :网络策略,被用作编写iptables来执行网络访问的能力
- Pods (e.g. labels) :观察Pod的变化,比如标签的变化
- Namespaces (used to determine if enforcement is needed for the new namespace) # 名称空间的变化
- Service Accounts (used for setting up Calico profiles) # SA 设置Calico的配置文件
- Nodes (used to determine the associated subnet and inform the routing topology) # 通知节点路由变化
拓扑图:
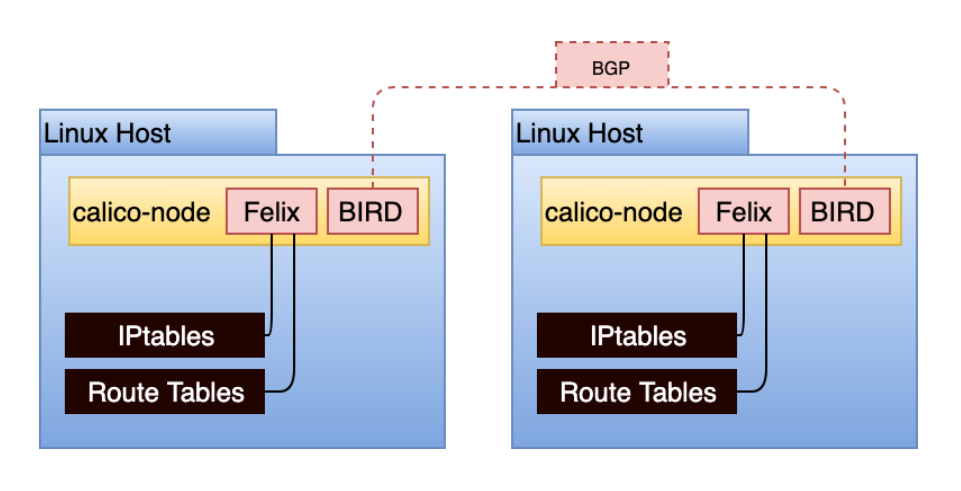
calico-node以daemonSet的形式运行在集群的每一个主机上。它负责两个功能:
- 路由配置:根据 Kubernetes 集群中到达 pod 的已知路由,配置 Linux 主机路由。
- 路由共享:基于该主机上运行的 pod,提供与其他主机共享已知路由的机制。通常通过边界网关协议 (BGP) 完成。
为了实现以上的两个功能,calico-node运行了两个进程:
- Felix:Felix负责对主机进行编程以满足 pod 路由和网络策略。为此,它与 Linux 内核的路由表和 Linux IPtables(用于网络策略)交互。Felix 将静态配置路由表,将学到的内容转换为主机路由表中的静态路由。Calico 使用 IPtables 会引起对可扩展性的担忧,但是使用 IPtables 的时间复杂度为 O(1)。 Calico 依赖 kube-proxy 来促进服务,这(在 IPtables 模式下)可能具有更接近于 O(n). 对于具有数千个服务的集群,应该考虑这一点。
- BIRD :BIRD采用 Felix 编写的路由规则,并与默认情况下在所有主机上运行的其他 BIRD 实例对等。这些 BGP 对等体不断共享有关其已知路由的路由信息。BIRD 是一个功能强大的守护进程,它支持多种拓扑。
在几乎所有情况下,最好使用 Kubernetes 数据存储而不是使用独立的etcd。在此模型中,Calico 使用的所有持久化数据都通过 Kubernetes API 服务器存储为自定义资源定义 (CRD)。
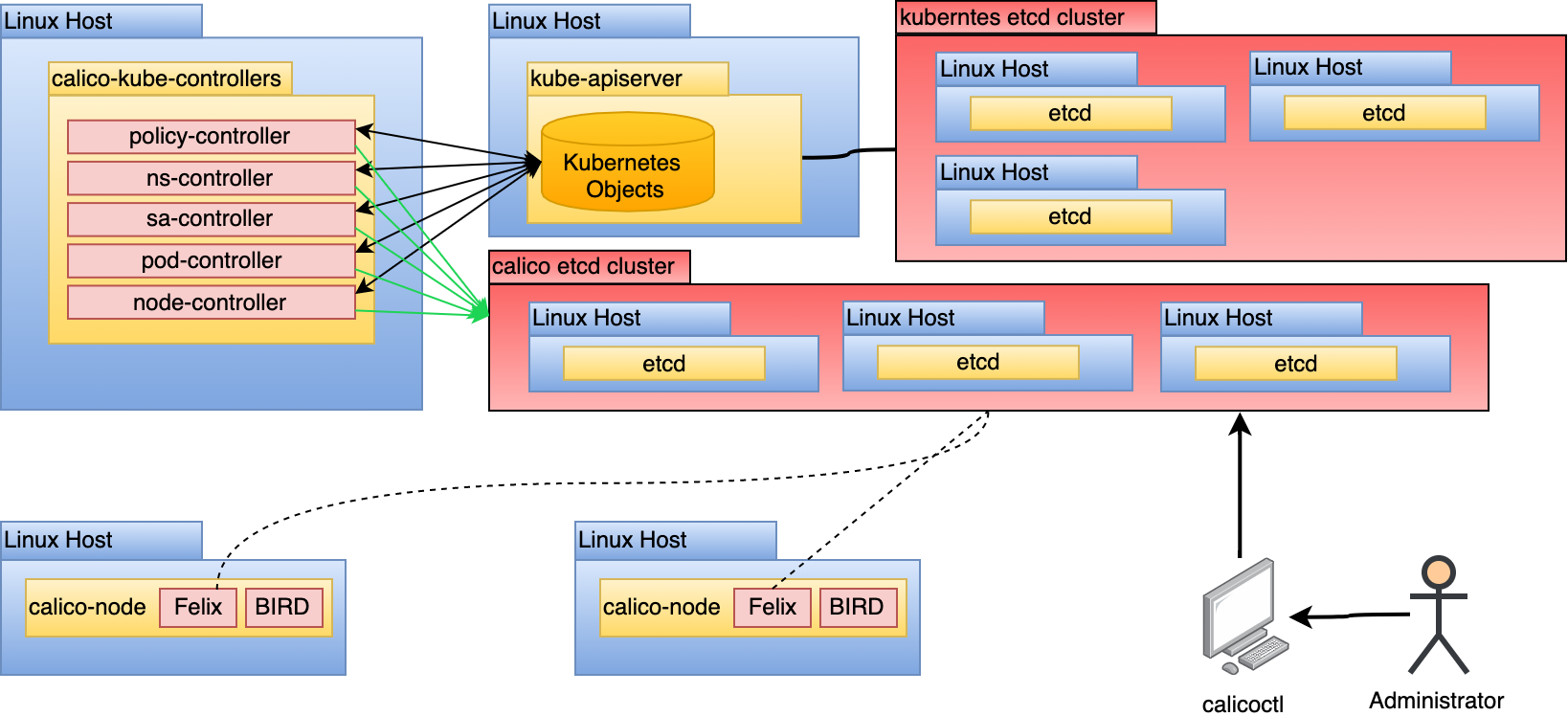
推荐使用Kubernetes来作为数据存储而非使用etcd。主要有一下原因:
- 直接使用etcd使得集群需要维护另外一套etcd环境。
- SA和RBAC问题。
Support for a Kubernetes backend was introduced after the etcd backend. For some time after its release, it did not offer the same features as the etcd backend. In current Calico (3.9+), feature parity has been achieved. Another issue with the Kubernetes backend was its inability to scale. With hundreds of Felix instances trying to interact with the kube-apiserver to get the latest updates and changes, it had a negative impact on the system. This has been remedied with the introduction of Typha. With the feature parity and scalability solved, the etcd mode incurs an unnecessary cost of administering a second etcd cluster. It also requires the implementation of authentication and authorization controls to prevent unauthorized modification of the Calico datastore. In the Kubernetes backend mode, it uses the administrator’s kubeconfig, which means access to Calico resources can be controlled by Kubernetes RBAC.
For the reasons stated in the previous section, this approach is not recommended as it introduces unnecessary complexity and security risk. If this model is used, do not use the Kubernetes etcd cluster as the datastore for Calico. No process outside of core Kubernetes should have access to the cluster’s etcd for security and performance reasons.
curl -O -L https://github.com/projectcalico/calicoctl/releases/download/v3.11.1/calicoctl
chmod +x calicoctl
配置 calicoctl 以连接到 Kubernetes API 数据存储
export DATASTORE_TYPE=kubernetes
export KUBECONFIG=~/.kube/config
[root@k8s-1 ~]# calicoctl node status
Calico process is running.
IPv4 BGP status
+--------------+-------------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+--------------+-------------------+-------+----------+-------------+
| 172.12.1.12 | node-to-node mesh | up | 07:38:53 | Established |
+--------------+-------------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
[root@k8s-1 ~]#
[root@k8s-1 ~]# calicoctl get wep -o wide
NAME WORKLOAD NODE NETWORKS INTERFACE PROFILES NATS
k8s--1-k8s-cni--j7klb-eth0 cni-j7klb k8s-1 10.244.231.200/32 cali0949f5d22ad kns.default,ksa.default.default
k8s--2-k8s-cni--mm9pd-eth0 cni-mm9pd k8s-2 10.244.200.194/32 calif83b17275a0 kns.default,ksa.default.default
[root@k8s-1 ~]# calicoctl get ippool -o wide
NAME CIDR NAT IPIPMODE VXLANMODE DISABLED SELECTOR
default-ipv4-ippool 10.244.0.0/16 true Always Never false all()
calico 支持多种路由模式,每种模式都有独特的权衡。本节详细介绍了这些路由模式的差异。
- Native:数据包按原样路由,没有封装。
- IP-in-IP:最小封装;外部标头包括主机源/目标 IP,内部标头包括 pod 源/目标。
- VXLAN:使用 UDP over IP 的封装(MAC in UDP);外部标头包括主机源/目标 IP 地址,内部标头包括 pod 源/目标 IP 地址以及以太网标头。
本机路由不封装进出 pod 的数据包。因此,它是一种高性能路由方法,因为您不会产生封装、解封装和更大标头的开销。它还使故障排除更简单,因为分析网络流量不涉及在数据包内部查找另一个数据包。在此模式下运行时,数据包结构如下图所示:
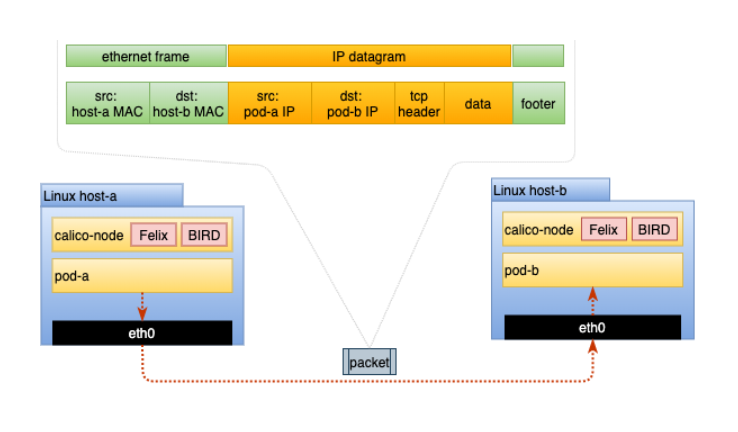
IP-in-IP 是一种简单的封装形式,它使用外部 IP 标头包装数据包,看起来好像源和目标是主机而不是 pod。因此,当主机收到 IP-in-IP 数据包时,它会检查内部 IP 标头以确定目标 pod。这是 Calico 的默认路由方式。虽然这种路由方法比本机路由产生更多开销,但它确实可以在大多数环境中工作而无需修改,尤其是在跨多个子网的环境中。在此模式下运行时,数据包结构如下图所示:
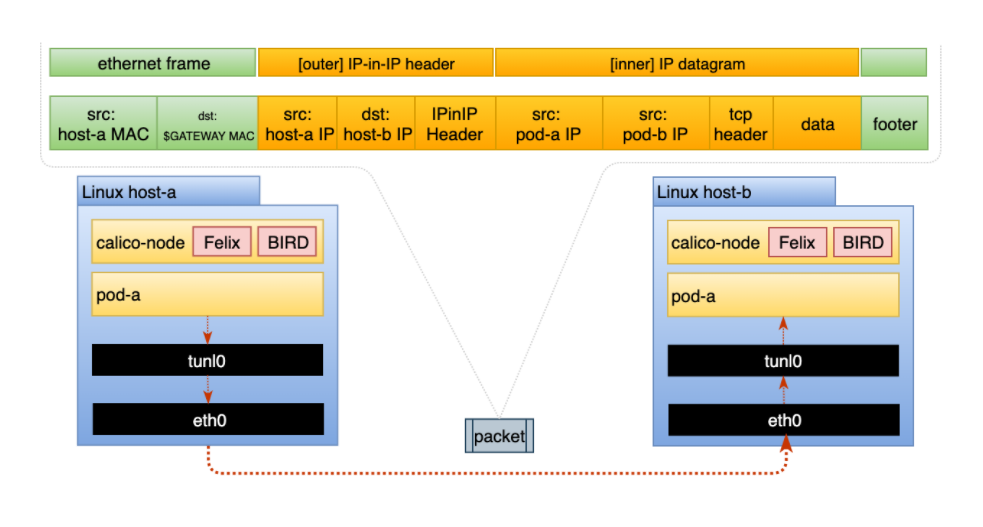
VXLAN 是一种功能丰富的封装形式,可以创建虚拟的2 层网络(大二层)。这是通过完全封装 pod 的以太网帧并添加一些特定于 VXLAN 的标头信息来实现的。 VXLAN 模式不需要 BGP,非常适合无法实现 BGP 对等互连的环境。在此模式下运行时,数据包结构如下图所示:
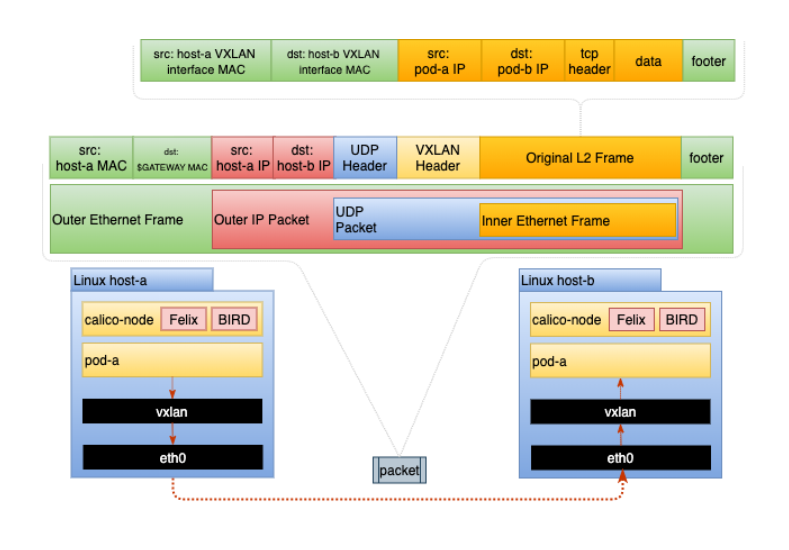
对于部署在单个子网中的集群,请使用 Native 路由模式。这将提供最佳性能和最简单的网络模型,因为没有封装。穿越网络的数据包将在其 IP 标头中包含 pod 的源 IP 和目标 IP。如果出于任何原因,网络或主机不允许这种类型的配置,您需要查看完整的 IP-in-IP 配置。
要启用Native 路由模式,集群中的 IPPools 必须将 ipipMode 和 vxlanMode 设置为 Never。这应该在部署 Calico 期间完成,但之后可以更改。为确保在部署期间设置了本机路由,请验证是否在 calico-node 容器清单中设置了以下内容:
env:
# other variables removed for brevity
# Enable IPIP
- name: CALICO_IPV4POOL_IPIP
value: "Never"
使用 calicoctl,可以验证(或修改)IPPool 设置。默认池公开如下:
输出应显示 ipipMode 和 vxlanMode 的当前设置。这两个都必须设置为"Never",如下所示:
# calicoctl get ippool default-ipv4-ippool -oyaml
apiVersion: projectcalico.org/v3
kind: IPPool
metadata:
name: default-ipv4-ippool
spec:
blockSize: 26
cidr: 192.168.0.0/16
ipipMode: Never
natOutgoing: true
nodeSelector: all()
vxlanMode: Never
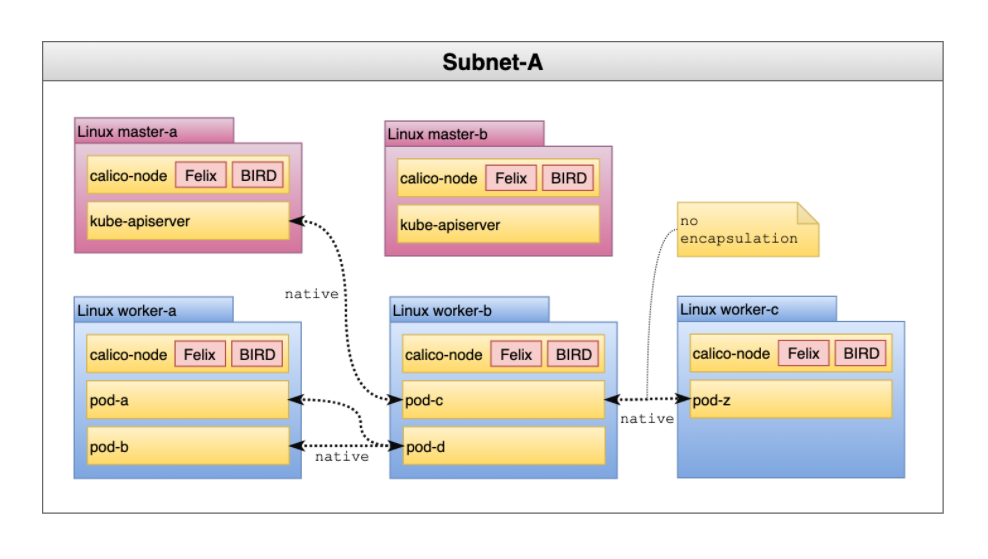
对于跨子网集群,本机路由很可能适用于子网内流量。但是,当 pod 跨子网边界进行通信时,它们通常会遇到一个路由器,该路由器依赖于目标 IP 来确定要路由到的主机。 IP-in-IP 可以解决了这个问题,但是,您对子网内流量的性能和复杂性造成了不必要的影响。
对于这些情况,推荐的选项是在 CrossSubnet 中运行 ipipMode。启用此设置后,本机路由将用于所有子网内通信,并且在跨越子网边界时使用 IP-in-IP(封装),如下图所示:
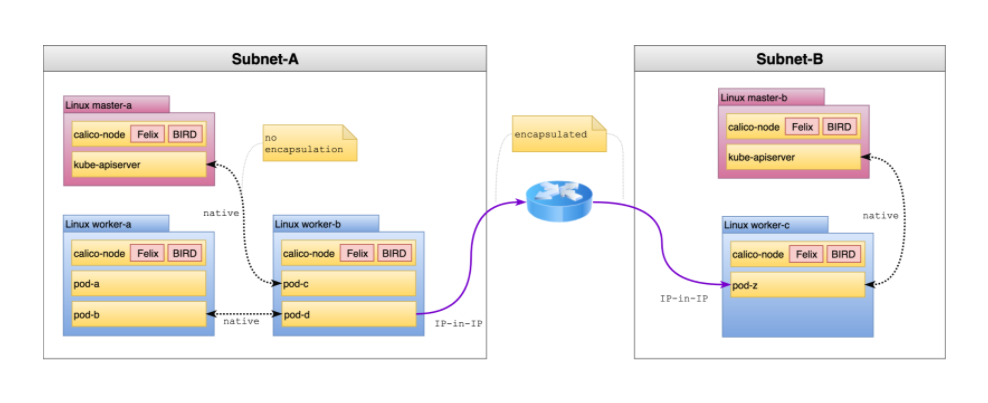
根据我们的经验,大多数集群跨越子网。因此,这是最常见的推荐拓扑。
为了确保在部署期间已经启用CrossSubnet模式,验证是否在 calico-node 容器清单中设置了以下内容:
env:
# other variables removed for brevity
# Enable IPIP
- name: CALICO_IPV4POOL_IPIP
value: "CrossSubnet"
使用 calicoctl,可以验证(或修改)IPPool 设置。默认池如下:
应将 ipipMode 的当前设置显示为 CrossSubnet,将 vxlanMode 显示为 Never:
# calicoctl get ippool default-ipv4-ippool -oyaml
apiVersion: projectcalico.org/v3
kind: IPPool
metadata:
name: default-ipv4-ippool
spec:
blockSize: 26
cidr: 192.168.0.0/16
ipipMode: CrossSubnet
natOutgoing: true
nodeSelector: all()
vxlanMode: Never
如果在您的环境中无法实现子网内流量的本地路由,例如网络对 IP 数据报执行源/目标检查,您可以使用完整的 IP-in-IP 配置。这是大多数 Calico 部署的默认设置。要验证这一点,您可以在 calico-node 清单中检查以下内容:
env:
# other variables removed for brevity
# Enable IPIP
- name: CALICO_IPV4POOL_IPIP
value: "Always"
使用 calicoctl,您可以验证(或修改)IPPool 设置。默认池配置如下:
输出应将 ipipMode 的当前设置显示为 Always,将 vxlanMode 显示为 Never:
# calicoctl get ippool default-ipv4-ippool -oyaml
apiVersion: projectcalico.org/v3
kind: IPPool
metadata:
name: default-ipv4-ippool
spec:
blockSize: 26
cidr: 192.168.0.0/16
ipipMode: Always
natOutgoing: true
nodeSelector: all()
vxlanMode: Never
IP-in-IP 和 Native 都需要 BGP 在节点之间分配路由。在某些环境中,可能无法进行 BGP 对等互连。在这些情况下,最好考虑 VXLAN,其中 BGP 是可选的。
对于首选 VXLAN 或无法使用 BGP 的环境,可以将 Calico 配置为在此模式下运行。由于 Native/IP-in-IP 和 VXLAN 之间路由和路由共享的变化,请勿在正在运行的集群中更改此设置。相反,请按照以下步骤确保集群启用了 VXLAN。除非您计划将 IPPools 与现有网络硬件对等,否则应禁用 BGP 对等以减少开销:
calico-config configmap 的后端设置为 vxlan,如下所示:
kind: ConfigMap
apiVersion: v1
metadata:
name: calico-config
namespace: kube-system
data:
# other settings removed for brevity
# value changed from bird to vxlan
calico_backend: “vxlan”
calico-node 清单将 CALICO_IPVPOOL_VXLAN 设置为 Always,如下所示:
env:
# other variables removed for brevity
# Enable VXLAN
- name: CALICO_IPV4POOL_VXLAN
value: "Always"
calico 节点清单未设置 CALICO_IPVPOOL_IPIP。
calico-node 清单禁用了所有与 BIRD 相关的活动性和就绪性检查,如下所示:
livenessProbe:
exec:
command:
- /bin/calico-node
- -felix-live
# disable bird liveness test
# - -bird-live
periodSeconds: 10
initialDelaySeconds: 10
failureThreshold: 6
readinessProbe:
exec:
command:
- /bin/calico-node
- -felix-ready
# disable bird readiness test
#- -bird-ready
periodSeconds: 10
如果上述情况属实,Calico 将以 VXLAN 模式运行所有流量。
除非在 VXLAN 模式下运行,否则 Calico 需要边界网关协议 (BGP) 在主机之间共享路由。 BGP 是许多路由器能够与之对等的通用协议。默认情况下,Calico 不需要部署支持 BGP 的路由器。相反,它在每个节点中运行一个路由守护程序 (BIRD),创建一个 BGP 网格。
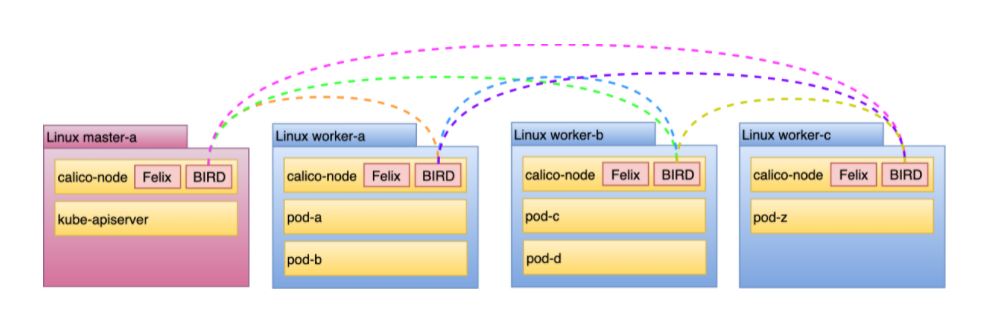
上图中,每条彩色线代表一个对等关系。该模型被称为节点到节点网格,因为它不存在集中路由分布。
使用 calicoctl 查看对等关系(在 4 台主机中的 1 台上):
# sudo calicoctl node status
Calico process is running.
IPv4 BGP status
+--------------+-------------------+-------+----------+--------------------------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+--------------+-------------------+-------+----------+--------------------------------+
| 10.30.0.17 | node-to-node mesh | up | 01:17:08 | Established |
| 10.30.0.16 | node-to-node mesh | up | 01:17:07 | Established |
| 10.30.0.14 | node-to-node mesh | up | 01:29:06 | Established |
+--------------+-------------------+-------+----------+--------------------------------+
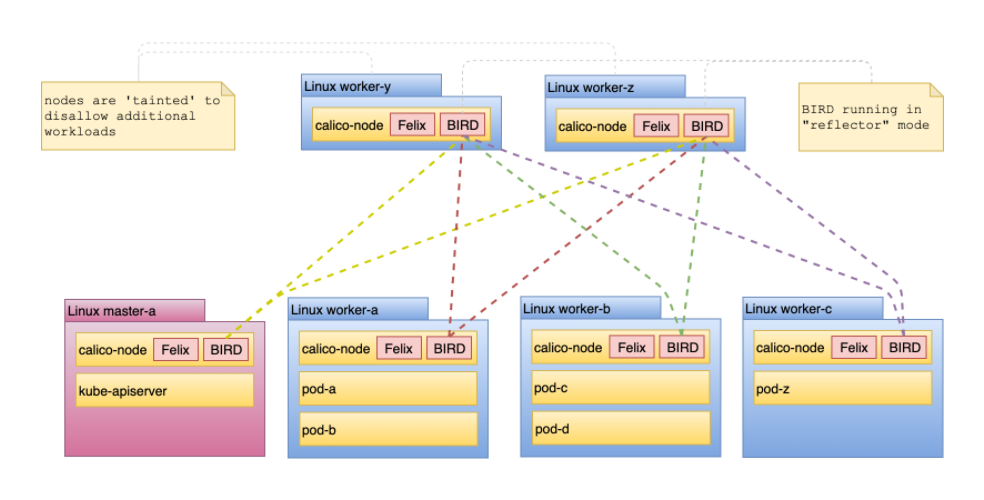
在 4 台主机中的 1 台上运行上述命令显示该主机与其他 3 台主机对等。对于小型集群(50 个节点以下),此模型已足够,无需更改。但是,当集群运行 50 到数千个节点时,每个节点之间的这种对等关系就会成为瓶颈。对于计划扩展到数百个节点的集群,应该利用路由反射器。
Calico 可以配置两种类型的目标来对等路由:
- calico-node configured reflector
在这个模型中,节点运行负责充当反射器的专用 calico-node 实例。该模型的配置在下面的全局路由反射部分中演示。
- Top of rack (ToR) switch or router
在此模型中,Calico 配置为与支持 BGP 的现有网络设备对等。这是使 pod IPPools 可路由到网络结构的有效方法。该模型的配置在下面的节点特定路由反射部分演示。
BGP 路由反射器提供集中的、高度可用的路由共享集线器,节点可以与之对等。在默认的节点到节点网状拓扑中,节点对等点的数量为 N-1,其中 N 是集群中的主机总数。在路由反射器模型中,对等点的数量成为部署的反射器的数量。对于超过 50 个节点并可能增长得远远超出此范围的集群,建议使用此拓扑。应用后,路由共享模型如下图所示: