002 Prometheus2.5 Grafana5.4二进制部署
prometheus大多数组件都是用Go编写的,他们可以非常轻松的基于二进制文件部署和构建.
wget https://github.com/prometheus/prometheus/releases/download/v2.12.0/prometheus-2.12.0.linux-amd64.tar.gz
useradd prometheus
tar xf /tmp/prometheus-2.12.0.linux-amd64.tar.gz -C /usr/local/
mv /usr/local/prometheus-* /usr/local/prometheus
chown -R prometheus:prometheus /usr/local/prometheus/
vim /etc/profile
PATH=/usr/local/prometheus/:$PATH:$HOME/bin
source /etc/profile
# promtool check config /usr/local/prometheus/prometheus.yml
Checking /usr/local/prometheus/prometheus.yml
SUCCESS: 0 rule files found
cat > /etc/systemd/system/prometheus.service <<EOF
[Unit]
Description=Prometheus
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
User=prometheus
ExecStart=/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml --storage.tsdb.retention.time=15d --storage.tsdb.path=/home/prometheus/data --web.listen-address=0.0.0.0:9090 --web.read-timeout=5m --web.max-connections=10 --query.max-concurrency=20 --query.timeout=2m
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
可以直接使用如下命令启动:
./prometheus
但是一般会传递一些参数,对prometheus做一下配置。例如:
./prometheus –config.file=/usr/local/cfg/prometheus.yml –web.listen-address=“0.0.0.0:9090” –web.read-timeout=5m –web.max-connections=10 –storage.tsdb.retention=15d –storage.tsdb.path="/usr/local/data/" –query.max-concurrency=20 –query.timeout=2m
常用参数如下:
- –web.read-timeout=5m #Maximum duration before timing out read of the request, and closing idle connections。请求链接的最大等待时间,防止太多的空闲链接占用资源。
防止太多的空闲链接占用资源
–web.max-connections=512 #Maximum number of simultaneous connections。最大同时连接数
–storage.tsdb.retention=15d #How long to retain samples in the storage.
prometheus开始采集监控数据后会存在内存中和硬盘中。对于保留期限的设置很重要,太长的话硬盘和内存都吃不消太短的话要查历史数据就没有了。企业中设置15天为宜。
–storage.tsdb.path="/usr/local/data/" #Base path for metrics storage。存储数据路径。
–query.timeout =2m #Maximum time a query may take before being aborted。用户执行prometheus查询的超时时间。防止用户执行过大的查询而一直不退出。
–query.max-concurrency=20 #Maximum number of queries executed concurrently。防止太多的用户同时查询。
上面这两项是对用户执行prometheus查询时候的优化设置,防止太多的用户同时查询,也防止单个用户执行过大的查询而一直不退出。
–web.enable-lifecycle ##提供类似nginx的reload功能。
curl -X POST http://localhost:9090/-/reload,或者使用kill -HUP PID–storage.tsdb.no-lockfile #不在数据目录下生成lock文件。如果用k8s的deployment管理要开启

其中这些长串字母的目录是历史数据保留;而当前近期数据实际上保留在内存中,并且按照一定间隔存放在wal/目录中防止突然断电或者重启,以用来恢复内存中的数据。(wal:write after log)
global:
scrape_interval: 15s # 设置抓取数据间隔为15s,默认为1min。
evaluation_interval: 15s # 设置评估告警规则的时间间隔,默认为1min。
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090','localhost:9100']
- job_name: 'nodes'
file_sd_configs:
- files: # 指定要加载的文件列表
- targets/nodes-*.yaml # 文件加载支持glob通配符
refresh_interval: 2m # 每隔2min重新加载一次文件中定义的target,默认为5min
- job_name: 'alertmanager'
file_sd_configs:
- files:
- targets/alertmanager-*.yaml
refresh_interval: 2m
[root@prometheus1 targets]# cat nodes-server.yaml
- targets:
- 10.211.55.38:9100
- 10.211.55.39:9100
labels:
app: node-exporter
component: monitor
region: B
- targets:
- 10.211.55.40:9100
labels:
app: node-exporter
component: monitor
region: A
[root@prometheus1 targets]# cat alertmanager-servers.yaml
- targets:
- 10.211.55.38:9093
labels:
app: alertmanager
component: monitor
region: A
注意:targets中的hostname必须能够解析,可以配置/etc/hosts文件。也可以直接使用ip。 示例:
# 全局配置
global:
scrape_interval: 30s # 每15秒抓取一次指标数据,默认值为1分钟
scrape_timeout: 30s # 全局设置抓取指标的超时时间
evaluation_interval: 60s # 每1分钟检测一次rule,默认值为1分钟
# Alertmanager配置,需要在targets添加ip和端口,也可以使用主机名和域名
alerting:
alertmanagers:
- static_configs:
- targets: ['127.0.0.1:9093']
# 根据全局文件 'evaluation_interval' 的时间,根据 rule 文件进行检查,可配置多个。
rule_files:
- "/data/prometheus/conf/rule/prod/*.yml"
- "/data/prometheus/conf/rule/op/*.yml"
- "/data/prometheus/conf/rule/ssl/*.yml"
# 抓取配置配置
scrape_configs:
- job_name: 'blackbox'
metrics_path: /probe
params:
module: [http_2xx] # Look for a HTTP 200 response.
scrape_interval: 30s
file_sd_configs:
- files:
- /data/prometheus/conf/prod/domain_config/*.yml
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 127.0.0.1:9115 # The blackbox exporter's real hostname:port.
- job_name: 'prom'
#honor_labels: true
scrape_interval: 10s
static_configs:
- targets: ['172.26.42.229:9100']
labels:
op_region: 'cn-north-1'
app: 'Prometheus'
env: 'Server'
systemctl daemon-reload
systemctl enable prometheus.service
systemctl start prometheus.service
# systemctl status prometheus.service
● prometheus.service - Prometheus
Loaded: loaded (/etc/systemd/system/prometheus.service; enabled; vendor preset: disabled)
Active: active (running) since 日 2018-12-09 22:21:52 CST; 4min 59s ago
Docs: https://prometheus.io/
Main PID: 1308 (prometheus)
CGroup: /system.slice/prometheus.service
└─1308 /usr/local/bin/prometheus --config.file=/usr/local/cfg/prometheus.yml --storage.tsdb.path=/usr/local/data
12月 09 22:21:52 qas-prometheus prometheus[1308]: level=info ts=2018-12-09T14:21:52.190312051Z caller=main.go:245 build_context="(go=go1.11.1, user=root@578ab108d0b9, date=20...-11:40:44)"
12月 09 22:21:52 qas-prometheus prometheus[1308]: level=info ts=2018-12-09T14:21:52.190327105Z caller=main.go:246 host_details="(Linux 3.10.0-862.el7.x86_64 #1 SMP Fri Apr 20...us (none))"
12月 09 22:21:52 qas-prometheus prometheus[1308]: level=info ts=2018-12-09T14:21:52.190342191Z caller=main.go:247 fd_limits="(soft=1024, hard=4096)"
12月 09 22:21:52 qas-prometheus prometheus[1308]: level=info ts=2018-12-09T14:21:52.190351846Z caller=main.go:248 vm_limits="(soft=unlimited, hard=unlimited)"
12月 09 22:21:52 qas-prometheus prometheus[1308]: level=info ts=2018-12-09T14:21:52.192559162Z caller=main.go:562 msg="Starting TSDB ..."
12月 09 22:21:52 qas-prometheus prometheus[1308]: level=info ts=2018-12-09T14:21:52.204059097Z caller=main.go:572 msg="TSDB started"
12月 09 22:21:52 qas-prometheus prometheus[1308]: level=info ts=2018-12-09T14:21:52.204101343Z caller=main.go:632 msg="Loading configuration file" filename=/usr/local/cf...metheus.yml
12月 09 22:21:52 qas-prometheus prometheus[1308]: level=info ts=2018-12-09T14:21:52.204905309Z caller=main.go:658 msg="Completed loading of configuration file" filename=/app/...metheus.yml
12月 09 22:21:52 qas-prometheus prometheus[1308]: level=info ts=2018-12-09T14:21:52.204919014Z caller=main.go:531 msg="Server is ready to receive web requests."
12月 09 22:21:52 qas-prometheus prometheus[1308]: level=info ts=2018-12-09T14:21:52.20493548Z caller=web.go:399 component=web msg="Start listening for connections" address=0.0.0.0:9090
Hint: Some lines were ellipsized, use -l to show in full.
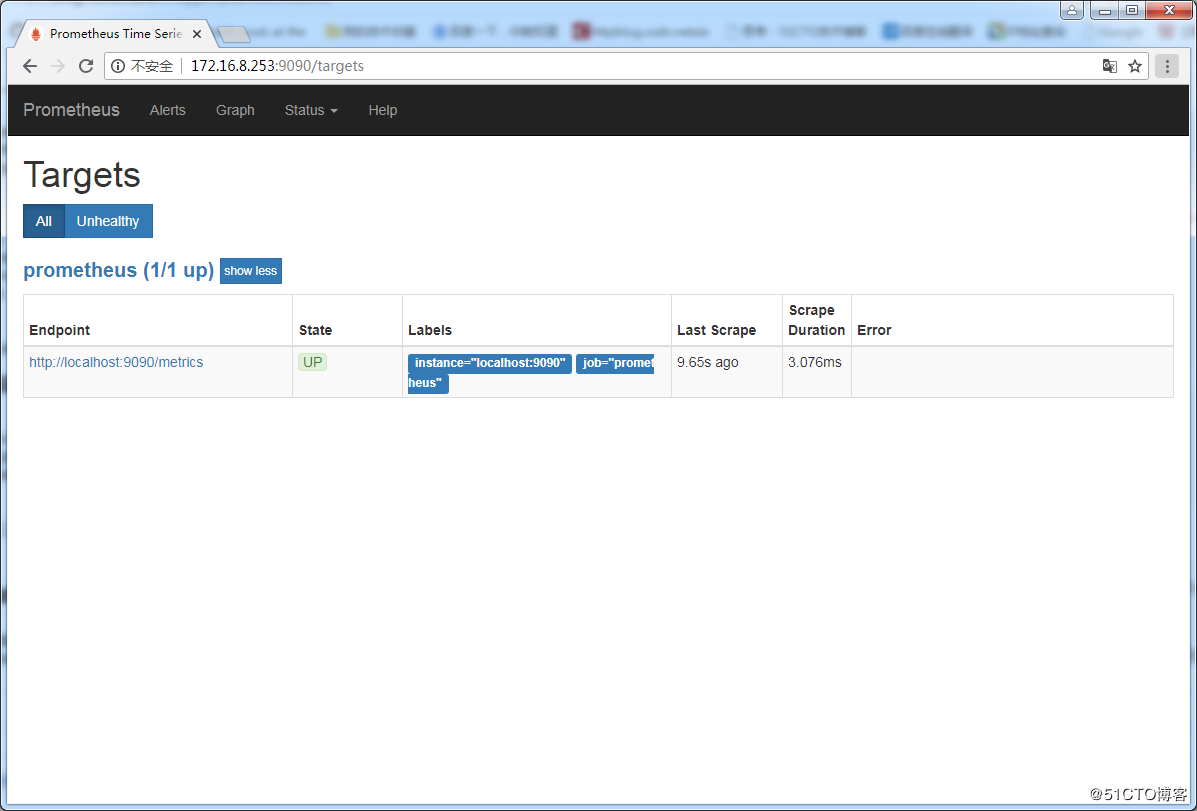
Prometheus自带有简单的UI,http://172.16.8.253:9090/
常用的exporter:
- node_export ##主机监控
- Redis/memcache/mongo/mysql/kafka/rabbitmq等db及缓存
- Blackbox_export (黑盒)一些http/tcp/ping/dns监控等等
- haproxy_exporter/
- consul_exporter ##支持外接配置中心
- graphite_exporter/ ##第三方数据源
直接运行:
./node_exporter
规范安装:
wget https://github.com/prometheus/node_exporter/releases/download/v0.18.0/node_exporter-0.18.0.linux-amd64.tar.gz
tar xf /tmp/node_exporter-0.18.1.linux-amd64.tar.gz -C /usr/local/
mv /usr/local/node_exporter-0.18.1.linux-amd64/ /usr/local/node_exporter
useradd prometheus
chown -R prometheus:prometheus /usr/local/node_exporter/
cat > /usr/lib/systemd/system/node_exporter.service <<EOF
[Unit]
Description=node_exporter
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
User=prometheus
ExecStart=/usr/local/node_exporter/node_exporter
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable node_exporter.service
systemctl start node_exporter.service
firewall-cmd --add-port=9100/tcp
firewall-cmd --add-port=9100/tcp --permanent
]# systemctl status node_exporter.service
● node_exporter.service - node_exporter
Loaded: loaded (/usr/lib/systemd/system/node_exporter.service; enabled; vendor preset: disabled)
Active: active (running) since 日 2018-12-09 22:45:10 CST; 4min 8s ago
Docs: https://prometheus.io/
Main PID: 1515 (node_exporter)
CGroup: /system.slice/node_exporter.service
└─1515 /usr/local/node_exporter/node_exporter
12月 09 22:45:10 qas-prometheus node_exporter[1515]: time="2018-12-09T22:45:10+08:00" level=info msg=" - sockstat" source="node_exporter.go:97"
12月 09 22:45:10 qas-prometheus node_exporter[1515]: time="2018-12-09T22:45:10+08:00" level=info msg=" - stat" source="node_exporter.go:97"
12月 09 22:45:10 qas-prometheus node_exporter[1515]: time="2018-12-09T22:45:10+08:00" level=info msg=" - textfile" source="node_exporter.go:97"
12月 09 22:45:10 qas-prometheus node_exporter[1515]: time="2018-12-09T22:45:10+08:00" level=info msg=" - time" source="node_exporter.go:97"
12月 09 22:45:10 qas-prometheus node_exporter[1515]: time="2018-12-09T22:45:10+08:00" level=info msg=" - timex" source="node_exporter.go:97"
12月 09 22:45:10 qas-prometheus node_exporter[1515]: time="2018-12-09T22:45:10+08:00" level=info msg=" - uname" source="node_exporter.go:97"
12月 09 22:45:10 qas-prometheus node_exporter[1515]: time="2018-12-09T22:45:10+08:00" level=info msg=" - vmstat" source="node_exporter.go:97"
12月 09 22:45:10 qas-prometheus node_exporter[1515]: time="2018-12-09T22:45:10+08:00" level=info msg=" - xfs" source="node_exporter.go:97"
12月 09 22:45:10 qas-prometheus node_exporter[1515]: time="2018-12-09T22:45:10+08:00" level=info msg=" - zfs" source="node_exporter.go:97"
12月 09 22:45:10 qas-prometheus node_exporter[1515]: time="2018-12-09T22:45:10+08:00" level=info msg="Listening on :9100" source="node_exporter.go:111"
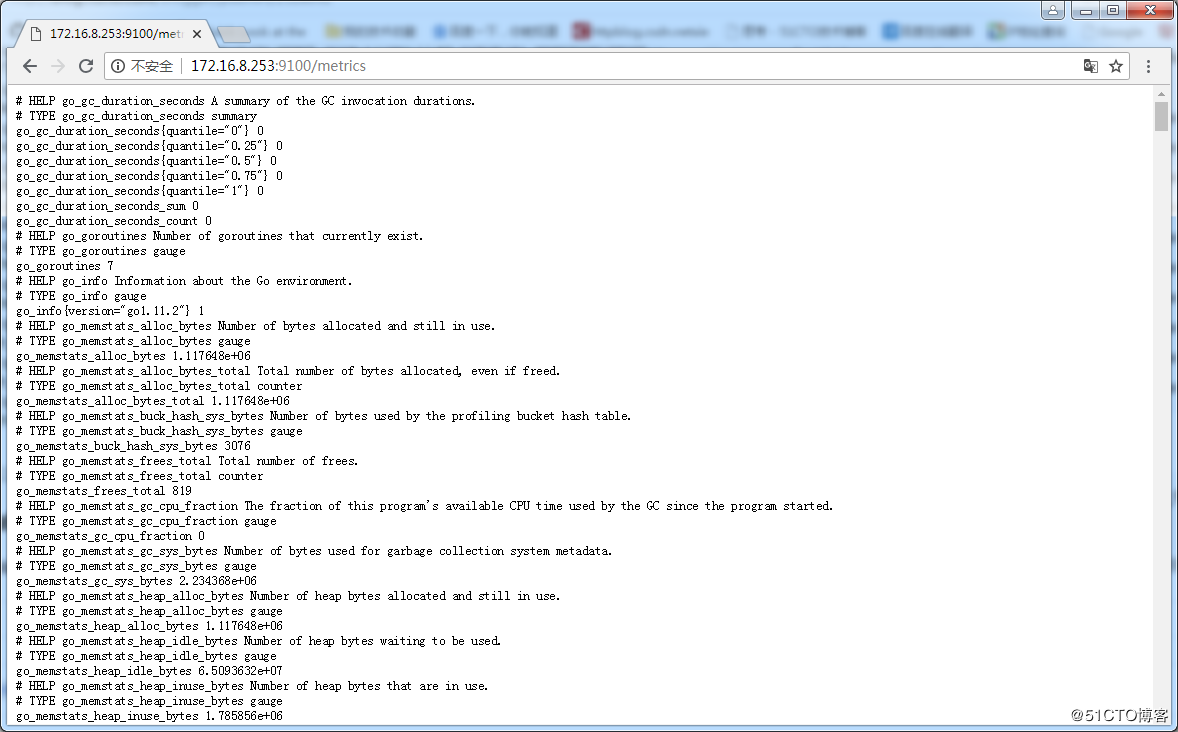
访问:http://172.16.8.253:9100/metrics,查看从exporter具体能抓到的数据.如下:有数据返回表示成功
pushgateway是另一种获取监控数据的prometheus 插件,采用被动推送的方式来接收exporter的推送的数据(而不是向exporter主动获取) 。它是可以单独运行在任何节点上的插件(并不一定要在被监控客户端),然后通过用户自定义开发脚本把需要监控的数据发送给pushgateway,prometheus server再向pushgateway拉取数据。
下载地址:https://github.com/prometheus/pushgateway
./pushgateway
可能涉及到参数:
–web.listen-address=“0.0.0.0:9091”
–persistence.file="/tmp/pushgateway.data"
【补充】手动测试
metrics格式:/metrics/job/<jobname>{/<label>/<label>}
# 发送metrics
echo "batchjob1_user_counter 8976.98" | curl -data-binary @- http://192.168.20.177:9091/metrics/job/batchjob1
echo 'batchjob1_user_counter{job_id="123abc"} 2' | curl -data-binary @- http://192.168.20.177:9091/metrics/job/batchjob1/instance/sidekiq_server
# 查看metrics
curl http://192.168.20.177:9091/metrics
# 删除metrics
curl -X DELETE http://192.168.20.177:9091/metrics/job/batchjob1
推荐阅读:https://mp.weixin.qq.com/s/CRwsEbpzwoWj5AF_wxScOA
curl -O https://dl.grafana.com/oss/release/grafana-6.3.5-1.x86_64.rpm
sudo yum localinstall grafana-6.3.5-1.x86_64.rpm
# 安装饼图、Consul数据源插件 grafana-cli plugins install grafana-piechart-panel grafana-cli plugins install sbueringer-consul-datasource systemctl restart grafana-server.service
systemctl daemon-reload
systemctl enable grafana-server.service
systemctl start grafana-server.service
可以看到监听端口address=0.0.0.0:3000
http://172.16.9.253:3000
默认账号/密码:admin/admin
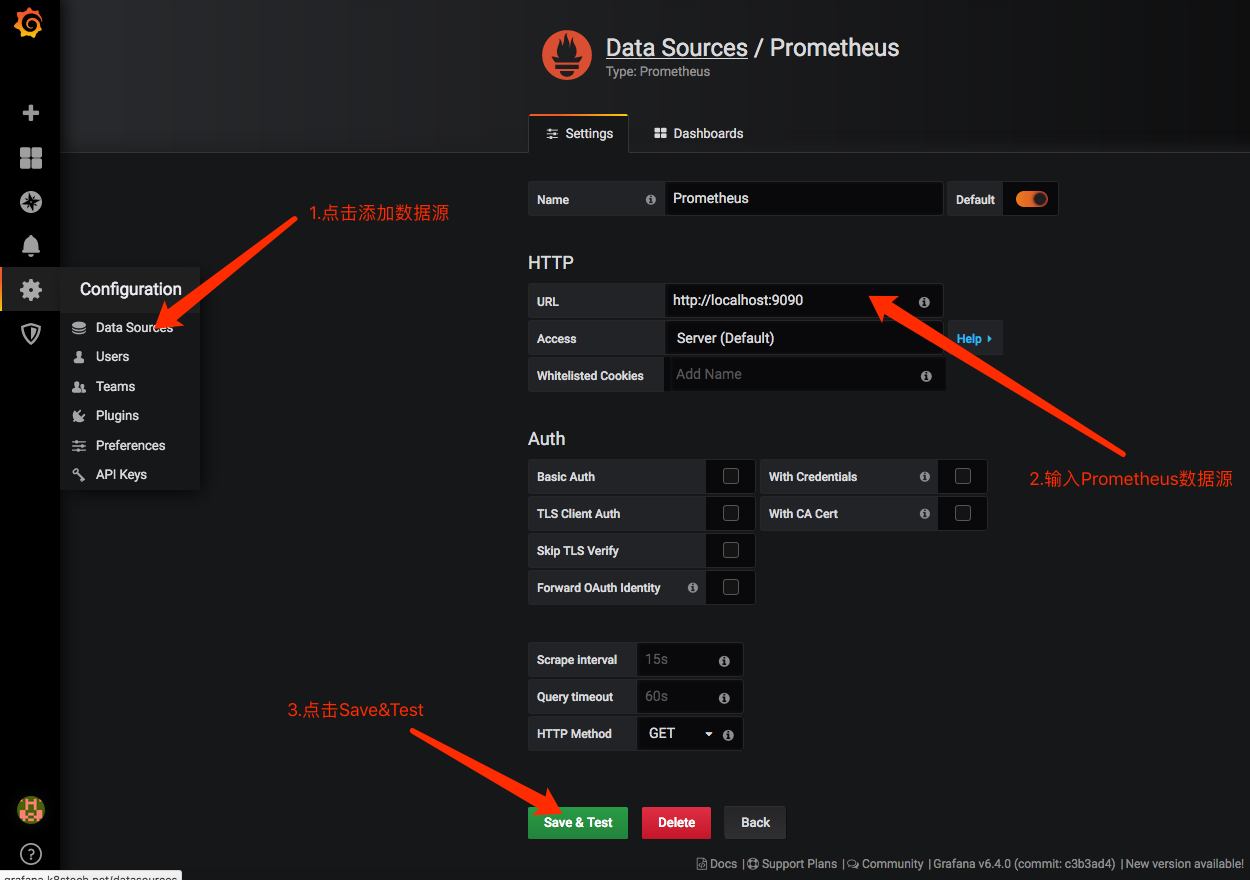
在登陆首页,点击"Configuration->Data Sources"按钮,跳转到添加数据源页面,配置如下:
Name: prometheus # (任意)
Type: prometheus
URL: http://172.16.9.253:9090/ #prometheus的访问地址
Access: Server #以server的身份访问Prometheus,其他值browser:以流量器的身份访问
点击"Save&Test",如下:
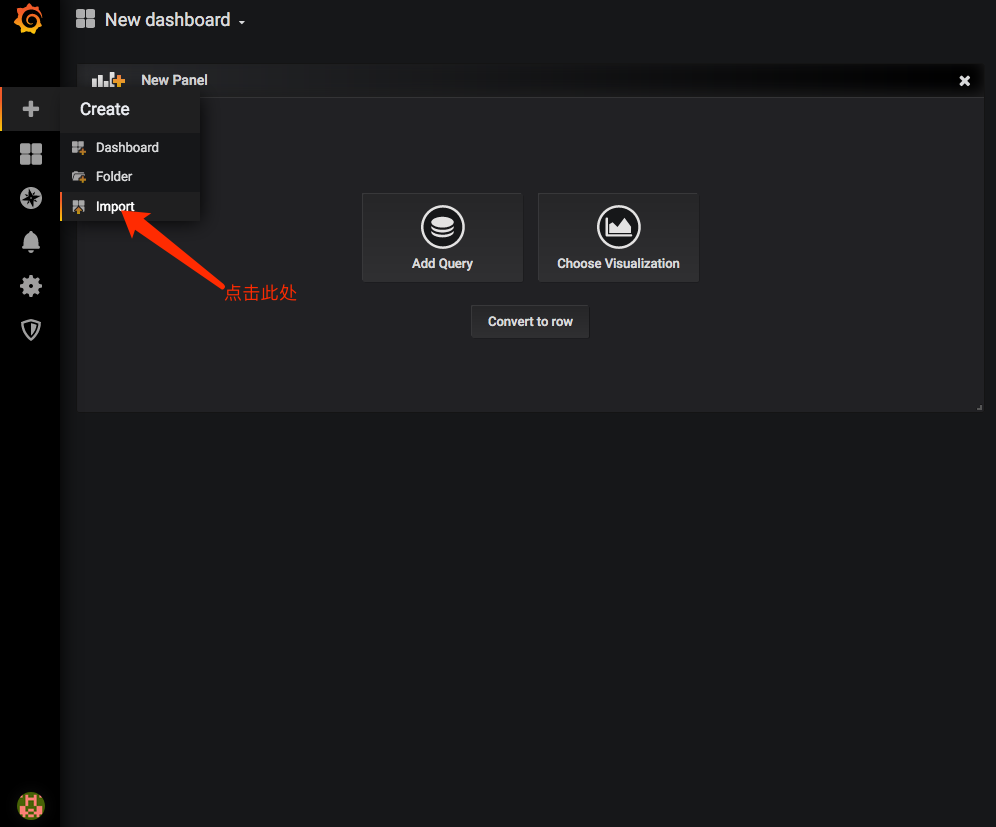
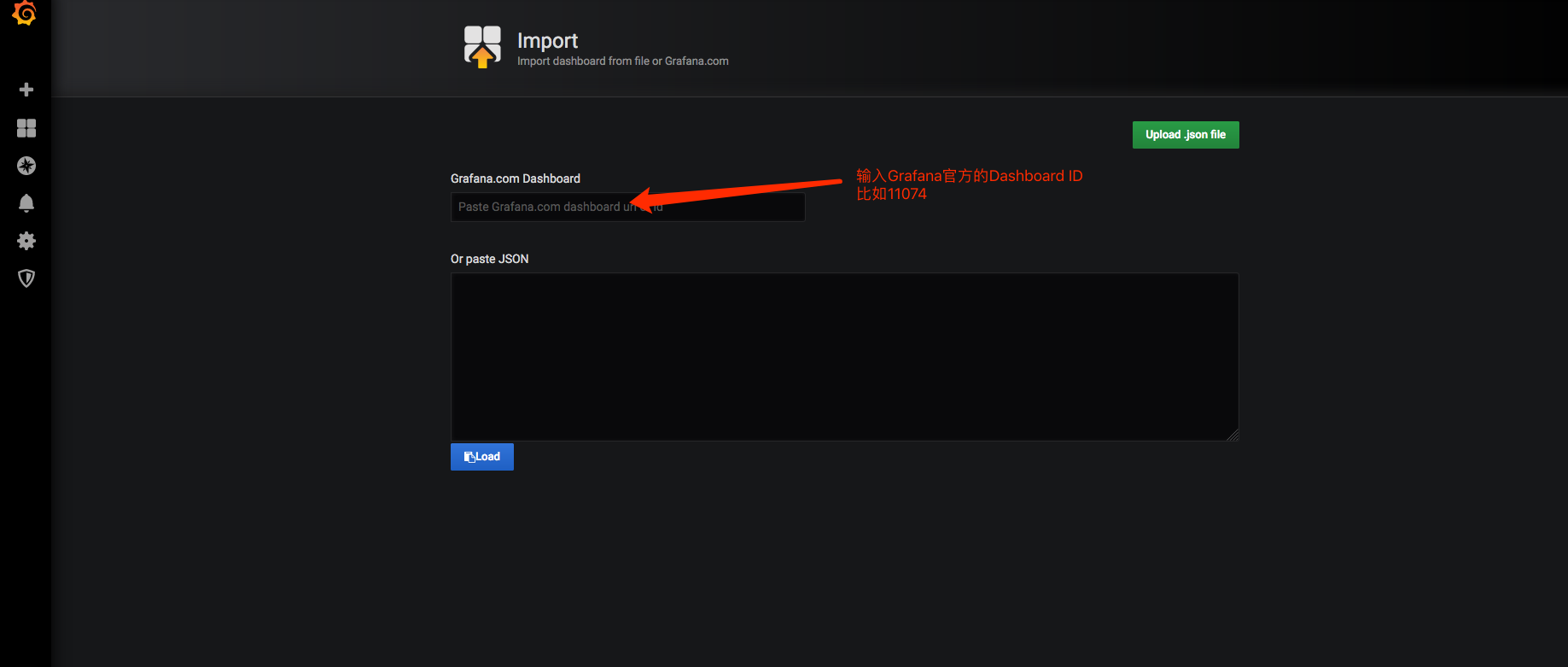
在https://grafana.com/grafana/dashboards上查询dashboard模板,找到想使用的模板的id或者json文件。
在grafana中import即可。
tar -xvf alertmanager-0.15.3.linux-amd64.tar.gz -C /usr/local/
cd /usr/local/
mv alertmanager-0.15.3.linux-amd64 alertmanager
mkdir alertmanager/data
chown -R prometheus:sprometheus alertmanager
cat > /usr/lib/systemd/system/alertmanager.service <<"EOF"
[Unit]
Description=alertmanager
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
User=prometheus
ExecStart=/usr/local/alertmanager/alertmanager \
--config.file=/usr/local/alertmanager/alertmanager.yml \
--web.listen-address=0.0.0.0:9093 \
--cluster.listen-address=0.0.0.0:8001 \
--storage.path=/usr/local/alertmanager/data \
--log.level=info
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
Alertmanager 参数
| 参数 | 描述 |
|---|---|
--config.file="alertmanager.yml" | 指定Alertmanager配置文件路径 |
--storage.path="data/" | Alertmanager的数据存放目录 |
--data.retention=120h | 历史数据保留时间,默认为120h |
--alerts.gc-interval=30m | 警报gc之间的间隔 |
--web.external-url=WEB.EXTERNAL-URL | 外部可访问的Alertmanager的URL(例如Alertmanager是通过nginx反向代理) |
--web.route-prefix=WEB.ROUTE-PREFIX | wen访问内部路由路径,默认是 --web.external-url |
--web.listen-address=":9093" | 监听端口,可以随意修改 |
--web.get-concurrency=0 | 并发处理的最大GET请求数,默认为0 |
--web.timeout=0 | web请求超时时间 |
--cluster.listen-address="0.0.0.0:9094" | 集群的监听端口地址。设置为空字符串禁用HA模式 |
--cluster.advertise-address=CLUSTER.ADVERTISE-ADDRESS | 配置集群通知地址 |
--cluster.gossip-interval=200ms | 发送条消息之间的间隔,可以以增加带宽为代价更快地跨集群传播。 |
--cluster.peer-timeout=15s | 在同级之间等待发送通知的时间 |
| … | … |
--log.level=info | 自定义消息格式 [debug, info, warn, error] |
--log.format=logfmt | 日志消息的输出格式: [logfmt, json] |
--version | 显示版本号 |
cat > /usr/local/alertmanager/alertmanager.yml <<EOF
global:
resolve_timeout: 5m
# smtp配置
smtp_from: "prom-alert@example.com"
smtp_smarthost: 'email-smtp.us-west-2.amazonaws.com:465'
smtp_auth_username: "user"
smtp_auth_password: "pass"
smtp_require_tls: true
templates:
- '/data/alertmanager/templates/*.tmpl'
route:
receiver: test1
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
group_by: [alertname]
routes:
# ads webhook
- receiver: test1
group_wait: 10s
match:
team: ads
# ops webhook
- receiver: test2
group_wait: 10s
match:
team: operations
receivers:
- name: test1
email_configs:
- to: '9935226@qq.com'
headers: { Subject: "[ads] 报警邮件"} # 接收邮件的标题
webhook_configs:
- url: http://localhost:8060/dingtalk/ads/send
- name: test2
#邮件
email_configs:
- to: '9935226@qq.com,deniss.wang@gmail.com'
send_resolved: true
headers: { Subject: "[ops] 报警邮件"} # 接收邮件的标题
#钉钉webhook
webhook_configs:
- url: http://localhost:8060/dingtalk/ops/send #"ops"是钉钉webhook中的profile
# wx config
wechat_configs:
- corp_id: 'wwxxxxxxxxxxxxxx'
api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'
send_resolved: true
to_party: '2'
agent_id: '1000002'
api_secret: '1FvHxuGbbG35FYsuW0YyI4czWY/.2'
EOF
上面的钉钉webhook可以使用如下方式实现:
docker run -d –restart always -p 8060:8060 timonwong/prometheus-webhook-dingtalk:v0.3.0 \
–ding.profile=“ads=https://oapi.dingtalk.com/robot/send?access_token=284de68124e97420a2ee8ae1b8f12fabe3213213213”
–ding.profile=“ops=https://oapi.dingtalk.com/robot/send?access_token=8bce3bd11f7040d57d44caa5b6ef9417eab24e1123123123213”
systemctl daemon-reload
systemctl enable alertmanager.service
systemctl start alertmanager.service
# tail -f /var/log/messages
Dec 11 10:51:11 prometheus-node2 systemd: Stopping alertmanager...
Dec 11 10:51:11 prometheus-node2 alertmanager: level=info ts=2018-12-11T02:51:11.118658711Z caller=main.go:426 msg="Received SIGTERM, exiting gracefully..."
Dec 11 10:51:11 prometheus-node2 systemd: Started alertmanager.
Dec 11 10:51:11 prometheus-node2 systemd: Starting alertmanager...
Dec 11 10:51:11 prometheus-node2 alertmanager: level=info ts=2018-12-11T02:51:11.156033311Z caller=main.go:174 msg="Starting Alertmanager" version="(version=0.15.3, branch=HEAD, revision=d4a7697cc90f8bce62efe7c44b63b542578ec0a1)"
Dec 11 10:51:11 prometheus-node2 alertmanager: level=info ts=2018-12-11T02:51:11.156186095Z caller=main.go:175 build_context="(go=go1.11.2, user=root@4ecc17c53d26, date=20181109-15:40:48)"
Dec 11 10:51:11 prometheus-node2 alertmanager: level=info ts=2018-12-11T02:51:11.179081721Z caller=cluster.go:155 component=cluster msg="setting advertise address explicitly" addr=172.16.9.202 port=8001
Dec 11 10:51:11 prometheus-node2 alertmanager: level=info ts=2018-12-11T02:51:11.182933235Z caller=main.go:322 msg="Loading configuration file" file=/usr/local/alertmanager/cfg/alertmanager.yml
Dec 11 10:51:11 prometheus-node2 alertmanager: level=info ts=2018-12-11T02:51:11.1953798Z caller=main.go:398 msg=Listening address=172.16.9.202:9093
Dec 11 10:51:11 prometheus-node2 alertmanager: level=info ts=2018-12-11T02:51:11.203980995Z caller=cluster.go:570 component=cluster msg="Waiting for gossip to settle..." interval=2s
Dec 11 10:51:13 prometheus-node2 alertmanager: level=info ts=2018-12-11T02:51:13.205051348Z caller=cluster.go:595 component=cluster msg="gossip not settled" polls=0 before=0 now=1 elapsed=2.000725532s
Dec 11 10:51:21 prometheus-node2 alertmanager: level=info ts=2018-12-11T02:51:21.208105947Z caller=cluster.go:587 component=cluster msg="gossip settled; proceeding" elapsed=10.003795489s
vim alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.163.com:25' # 邮箱smtp服务器代理
smtp_from: 'xxxxxxx@163.com' # 发送邮箱名称
smtp_auth_username: 'xxxxxx@163.com' # 邮箱名称
smtp_auth_password: 'xxxxx' # 邮箱密码或授权码
smtp_require_tls: false
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'mail'
receivers:
- name: 'mail'
email_configs:
- to: 'xxxxxxxx@qq.com'
### rules配置告警规则
```
vim qas.yml
groups:
- name: 主机状态-监控告警
rules:
- alert: 主机状态
expr: up == 0
for: 1m
labels:
status: 非常严重
annotations:
summary: "{{$labels.instance}}:服务器宕机"
description: "{{$labels.instance}}:服务器延时超过5分钟"
- alert: CPU使用情况
expr: 100-(avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)* 100) > 60
for: 1m
labels:
status: 一般告警
annotations:
summary: "{{$labels.mountpoint}} CPU使用率过高!"
description: "{{$labels.mountpoint }} CPU使用大于60%(目前使用:{{$value}}%)"
- alert: 内存使用
expr: 100 -(node_memory_MemTotal_bytes -node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes ) / node_memory_MemTotal_bytes * 100> 80
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.mountpoint}} 内存使用率过高!"
description: "{{$labels.mountpoint }} 内存使用大于80%(目前使用:{{$value}}%)"
- alert: IO性能
expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.mountpoint}} 流入磁盘IO使用率过高!"
description: "{{$labels.mountpoint }} 流入磁盘IO大于60%(目前使用:{{$value}})"
- alert: 网络
expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.mountpoint}} 流入网络带宽过高!"
description: "{{$labels.mountpoint }}流入网络带宽持续2分钟高于100M. RX带宽使用率{{$value}}"
- alert: 网络
expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.mountpoint}} 流出网络带宽过高!"
description: "{{$labels.mountpoint }}流出网络带宽持续2分钟高于100M. RX带宽使用率{{$value}}"
- alert: TCP会话
expr: node_netstat_Tcp_CurrEstab > 1000
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.mountpoint}} TCP_ESTABLISHED过高!"
description: "{{$labels.mountpoint }} TCP_ESTABLISHED大于1000%(目前使用:{{$value}}%)"
- alert: 磁盘容量
expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 80
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.mountpoint}} 磁盘分区使用率过高!"
description: "{{$labels.mountpoint }} 磁盘分区使用大于80%(目前使用:{{$value}}%)"
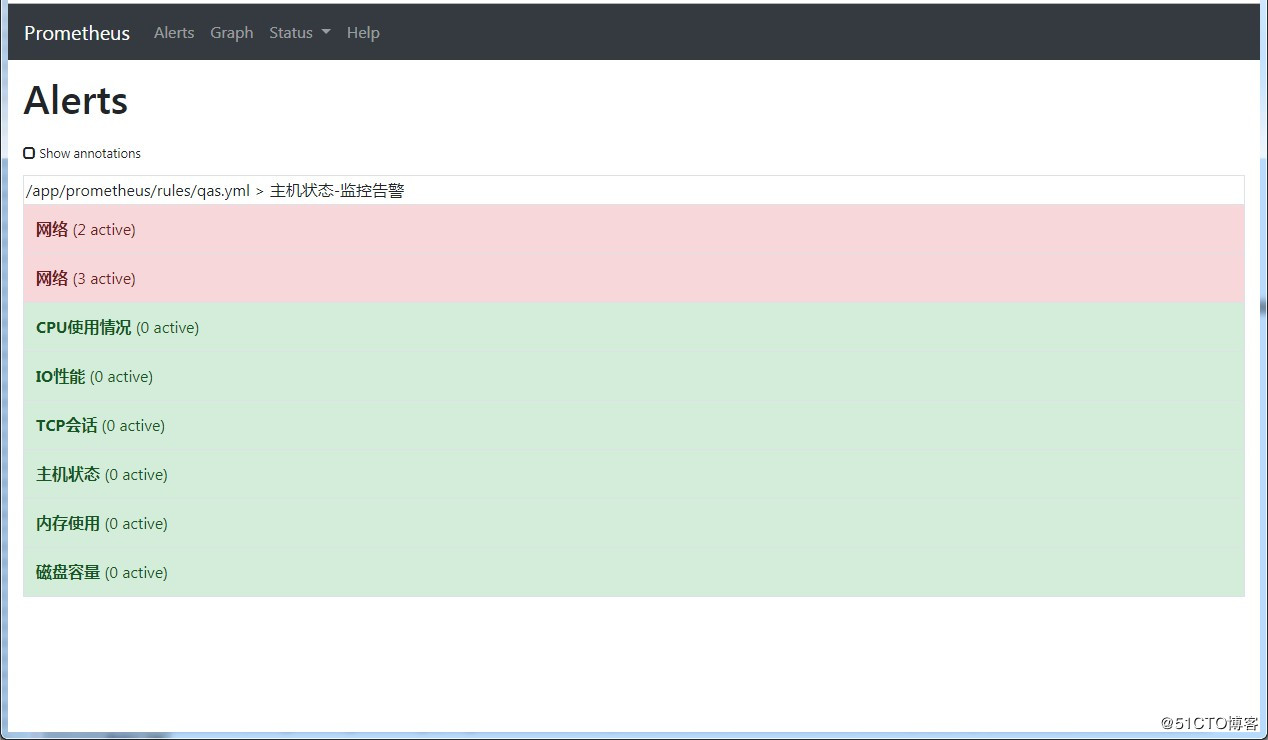
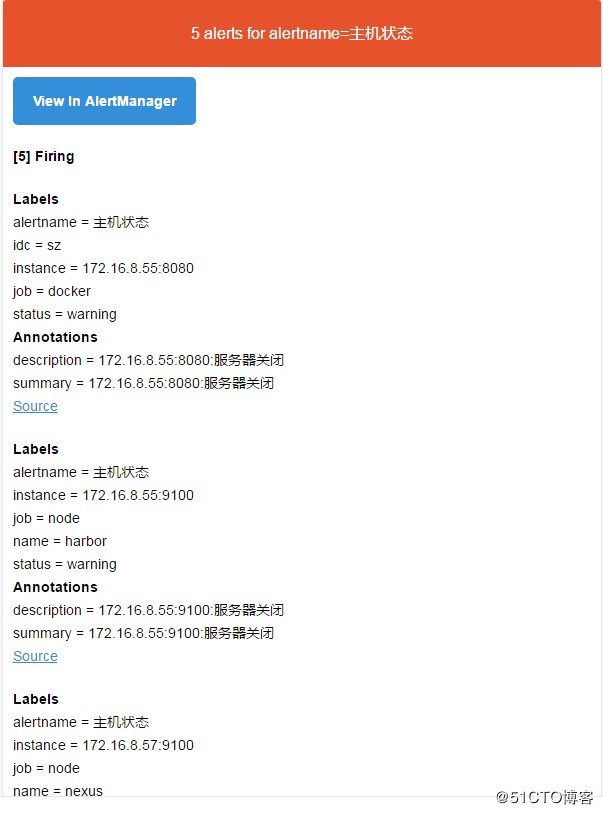
为了提升Prometheus的服务可靠性,我们会部署两个或多个的Prometheus服务,两个Prometheus具有相同的配置(Job配、告警规则、等),当其中一个Down掉了以后,可以保证Prometheus持续可用。
AlertManager自带警报分组机制,即使不同的Prometheus分别发送相同的警报给Alertmanager,Alertmanager也会自动把这些警报合并处理。
| 去重 | 分组 | 路由 |
|---|---|---|
| Daduplicates | Groups | Route |
| 将相同的警报合并成一个 | 根据定义的分组 | 经过路由分发给指定的receiver |
虽然Alertmanager 能够同时处理多个相同的Prometheus的产生的警报,如果部署的Alertmanager是单节点,那就存在明显的的单点故障风险,当Alertmanager节点down机以后,警报功能则不可用。
解决这个问题的方法就是使用传统的HA架构模式,部署Alertmanager多节点。但是由于Alertmanager之间关联存在不能满足HA的需求,因此会导致警报通知被Alertmanager重复发送多次的问题。
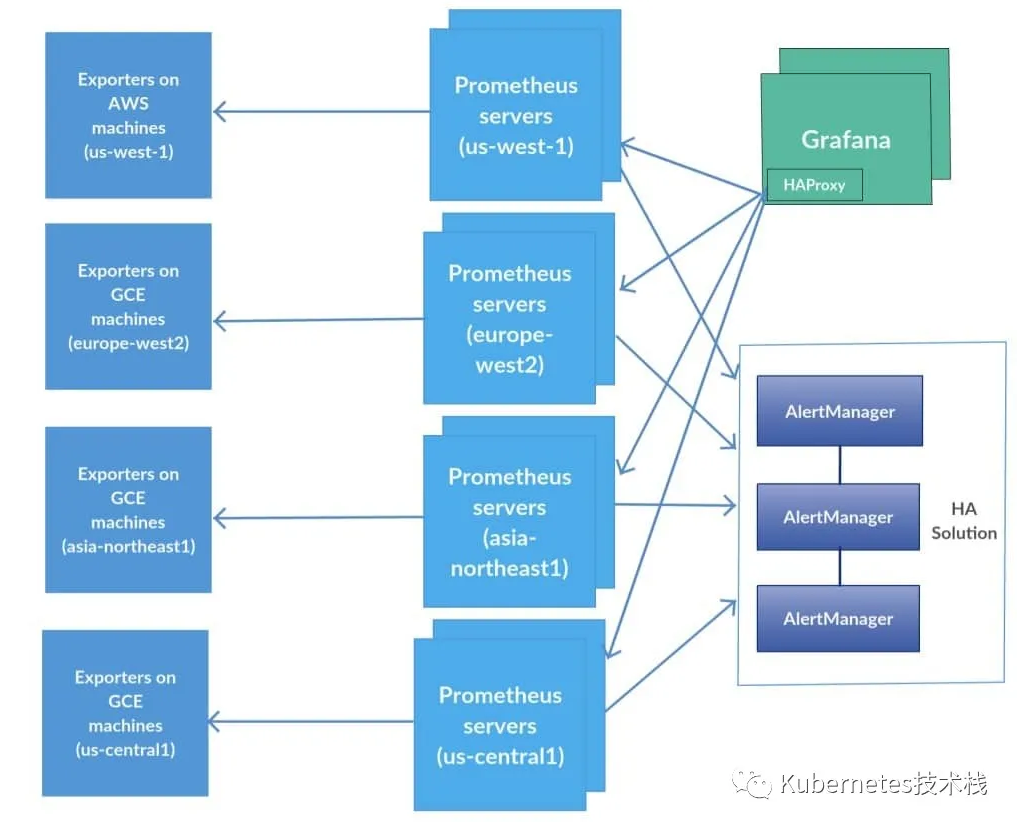
Alertmanager为了解决这个问题,引入了Gossip机制,为多个Alertmanager之间提供信息传递机制。确保及时的在多个Alertmanager分别接受到相同的警报信息的情况下,不会发送重复的警报信息给Receiver.
要知道什么是Gossip机制,必须了解清楚Alertmanager中的每一次警报通知是如何产生的,下面一图很详细的阐述了警报个流程:
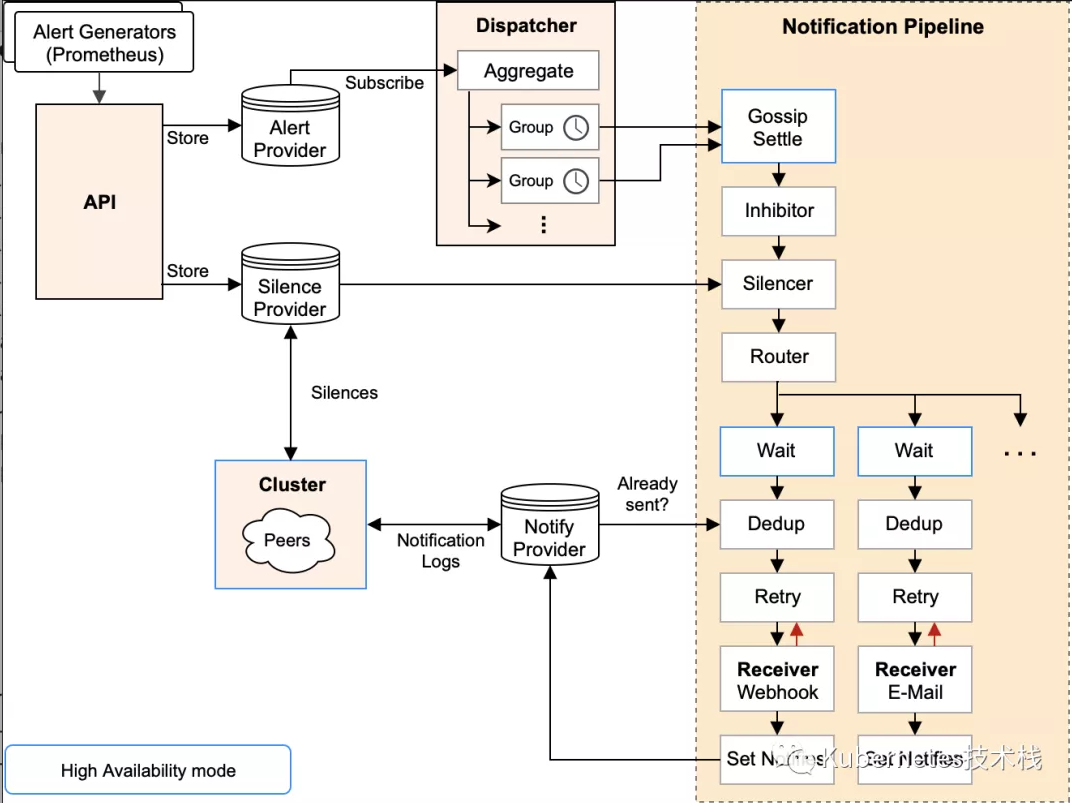
| 阶段 | 描述 |
|---|---|
Silence | 在这个阶段中Alertmanager会判断当前通知是否匹配任何静默规则;如果没有则进入下一个阶段,否则会中断流程不发送通知。 |
Wait | Alertmanager 会根据当前集群中所处在的顺序[index],等待 index * 5s 的时间。 |
Dedup | 当等待结束完成,进入 Dedup 阶段,这时会判断当前Alertmanager TSDB中警报是否已经发送,如果发送则中断流程,不发送警报。 |
Send | 如果上面的未发送,则进入 Send 阶段,发送警报通知。 |
Gossip | 警报发送成功以后,进入最后一个阶段 Gossip ,通知其他Alertmanager节点,当前警报已经发送成功。其他Alertmanager节点会保存当前已经发送过的警报记录。 |
Gossip俩个关键:
- Alertmanager 节点之间的Silence设置相同,这样确保了设置为静默的警报都不会对外发送
- Alertmanager 节点之间通过Gossip机制同步警报通知状态,并且在流程中标记Wait阶段,保证警报是依次被集群中的Alertmanager节点读取并处理。
Alertmanager支持配置以创建高可用性集群。可以使用--cluster- *标志进行配置。启动Alertmanager集群之前,需要了解一些集群相关的参数。
| 参数 | 说明 |
|---|---|
--cluster.listen-address="0.0.0.0:9094" | 集群服务监听端口,默认为9094 |
--cluster.peer | 初始化关联其他节点的监听地址 |
--cluster.advertise-address | 广播地址 |
--cluster.gossip-interval | 集群消息传播时间,默认 200s |
--cluster.probe-interval | 集群各个节点的探测时间间隔 |
# 直接复制之前已经安装过的Alertmanager文件夹
cp -r alertmanager/ /usr/local/alertmanager01
cp -r alertmanager/ /usr/local/alertmanager02
cp -r alertmanager/ /usr/local/alertmanager03
# 复制完成以后,写入启动脚本,
# Alertmanager01
cat << EOF> /lib/systemd/system/alertmanager01.service
[Unit]
Description=alertmanager
Documentation=https://prometheus.io/
After=network.target
StartLimitIntervalSec=0
[Service]
Type=simple
User=prometheus
ExecStart=/usr/local/alertmanager01/bin/alertmanager \
--config.file=/usr/local/alertmanager01/conf/alertmanager.yml \
--storage.path=/usr/local/alertmanager01/data \
--web.listen-address=":19093" \
--cluster.listen-address=192.168.1.220:19094 \
--log.level=debug
Restart=always
RestartSec=1
[Install]
WantedBy=multi-user.target
EOF
# Alertmanager02
cat << EOF> /lib/systemd/system/alertmanager02.service
[Unit]
Description=alertmanager
Documentation=https://prometheus.io/
After=network.target
StartLimitIntervalSec=0
[Service]
Type=simple
User=prometheus
ExecStart=/usr/local/alertmanager02/bin/alertmanager \
--config.file=/usr/local/alertmanager02/conf/alertmanager.yml \
--storage.path=/usr/local/alertmanager02/data \
--web.listen-address=":29093" \
--cluster.listen-address=192.168.1.220:29094 \
--cluster.peer=192.168.1.220:19094 \ #指定node1
--log.level=debug
Restart=always
RestartSec=1
[Install]
WantedBy=multi-user.target
EOF
# Alertmanager03
cat <<EOF > /lib/systemd/system/alertmanager03.service
[Unit]
Description=alertmanager
Documentation=https://prometheus.io/
After=network.target
StartLimitIntervalSec=0
[Service]
Type=simple
User=prometheus
ExecStart=/usr/local/alertmanager03/bin/alertmanager \
--config.file=/usr/local/alertmanager03/conf/alertmanager.yml \
--storage.path=/usr/local/alertmanager03/data \
--web.listen-address=":39093" \
--cluster.listen-address=192.168.1.220:39094 \
--cluster.peer=192.168.1.220:19094 \ #指定node1
--log.level=debug
Restart=always
RestartSec=1
[Install]
WantedBy=multi-user.target
EOF
# 开启systemd脚本启动
systemctl enable alertmanager01 alertmanager02 alertmanager03
systemctl start alertmanager01 alertmanager02 alertmanager03
启动完成后,就可以访问http://192.168.1.220:19093可以看到以下集群状态了,我这里是为了测试,本地启动了多个端口,如果是实际生产环境中,是不同节点以及不同的IP,这些根据自己的需求设计即可。
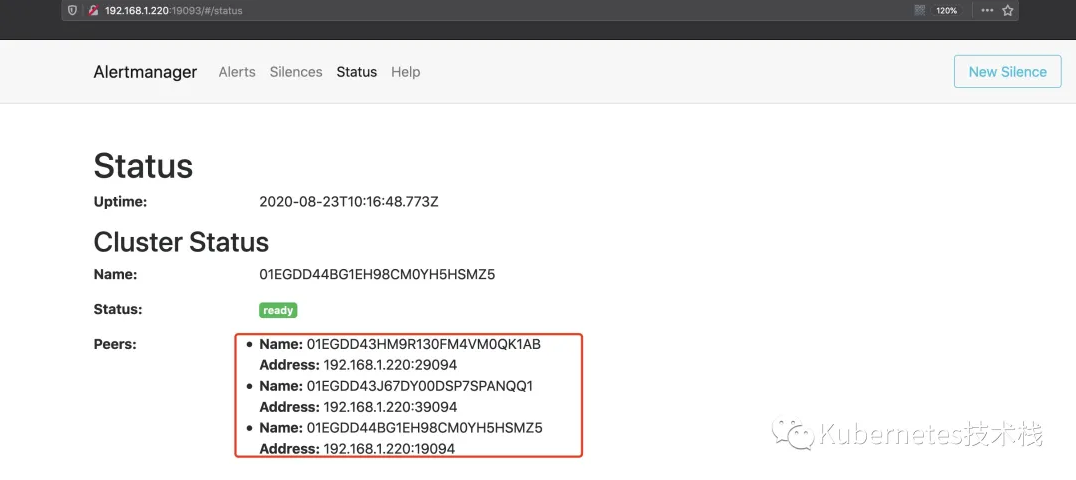
Prometheus中的配置:
注意不要让Prometheus指向Alertmanagers的负载均衡器,而是将Prometheus指向所有Alertmanagers的列表。例如:
alerting:
alert_relabel_configs:
- source_labels: [dc]
regex: (.+)\d+
target_label: dc
alertmanagers:
- static_configs:
#- targets: ['127.0.0.1:9093']
- targets: ['192.168.1.220:19093','192.168.1.220:29093','192.168.1.220:39093']
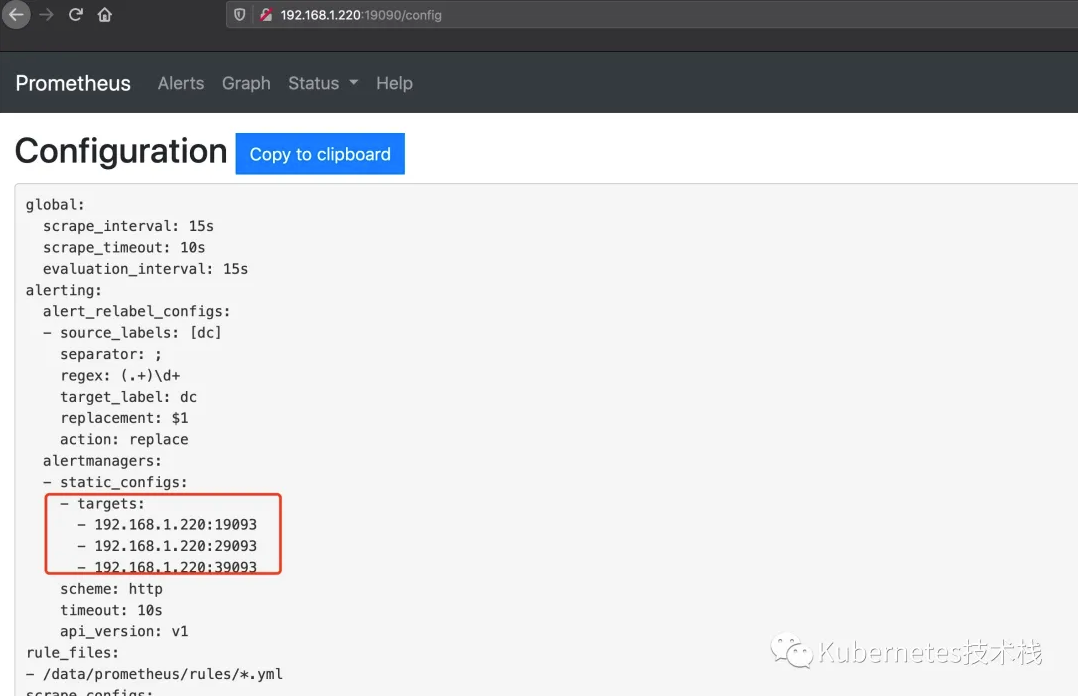
配置完成以后,重启或者reload Prometheus服务,访问http://192.168.1.220:19090/config就可以看到具体的配置信息了。
到此,Alertmanager集群配置就完成了,对于进群中的警报测试很简单,直接down掉一个端口,然后触发警报,看看警报是否可以正常发送。