003 Prometheus的数据模型
监控系统一般会从各个维度去获取监控数据,然后将其保存在监控系统中。

Prometheus从根本上所有的存储都是按时间序列去实现的。
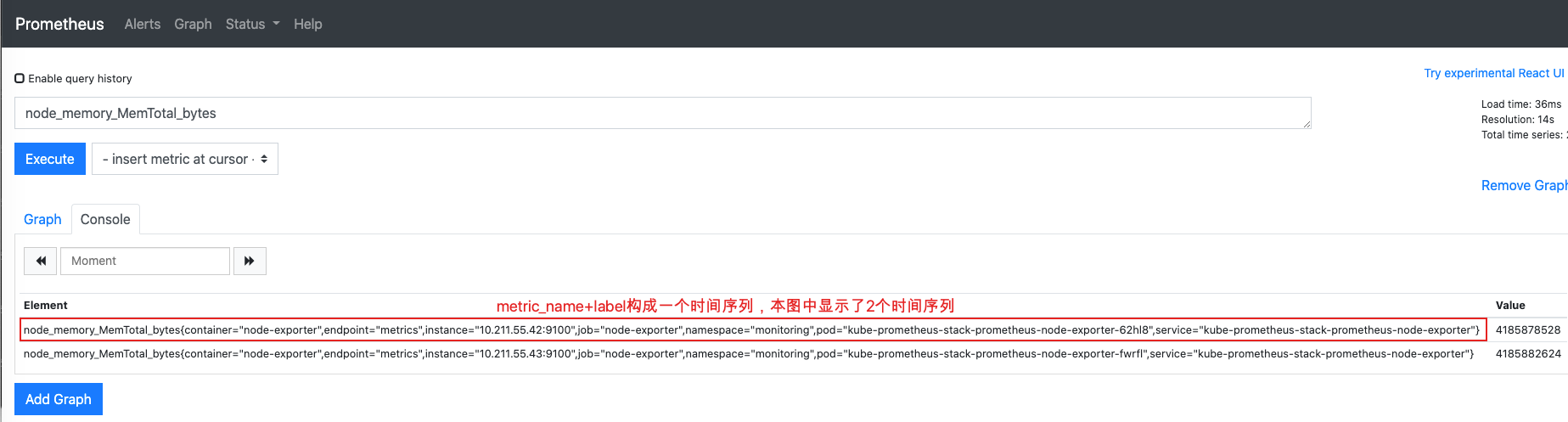
每个时间序列由2个元素唯一确定:metrics(指标名称) 、label组合(一个或多个标签) 。相同的metric_name和相同的label组合组成一条时间序列,不同的metric_name或不同的label组合都表示不同的时间序列。为了支持一些查询,有时还会临时产生一些时间序列存储
- 时间序列是以“键值”形式存储的时序式的聚合数据(底层还会保存时间戳信息),它并不支持存储文本信息(只支持双精度浮点型数据),即:
key value timestamp。例如下图中,key为时序(指标名称+标签)cpu_usage{core="1",ip="128.0.0.1"},value为14.04。 - 其中的“键”称为指标(Metric),它通常意味着CPU速率、内存使用率或分区空闲比例等;
- 同一指标可能会适配到多个目标或设备,因而它使用“标签”作为元数据,从而为Metric添加更多的信息描述纬度;
- 这些标签还可以作为过滤器进行指标过滤及聚合运算;
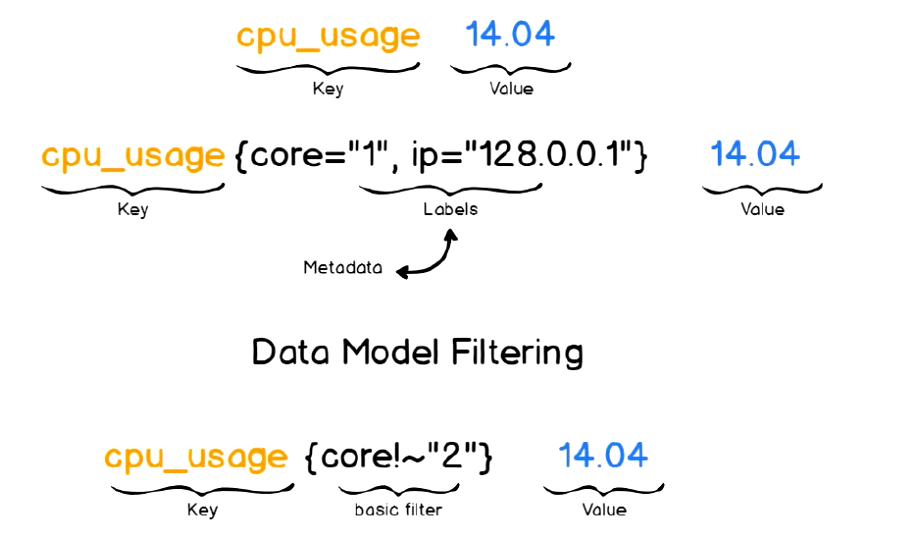
每条时间序列是由唯一的指标名称和一组标签 (key=value)的形式组成,即一个时间序列由指标名称和标签2部分共同组成。
- 指标名称 一般是给监测对像起一名字,例如 http_requests_total 这样,它有一些命名规则,可以包字母数字之类的的。通常是以应用名称开头监测对像数值类型单位这样。例如:
- push_total
- userlogin_mysql_duration_seconds
- app_memory_usage_bytes
- 标签 就是对一条时间序列不同维度的识别了,例如 一个http请求用的是POST还是GET,它的endpoint是什么,这时候就要用标签去标记了。最终形成的标识便是这样了
http_requests_total{method="POST",endpoint="/api/tracks"}
记住,针对http_requests_total这个metrics name 无论是增加标签还是删除标签都会形成一条新的时间序列。 查询语句就可以跟据上面标签的组合来查询聚合结果了。 如果以传统数据库的理解来看这条语句,则可以考虑 http_requests_total是表名,标签是字段,而timestamp是主键,还有一个float64字段是值了。(Prometheus里面所有值都是按float64存储)
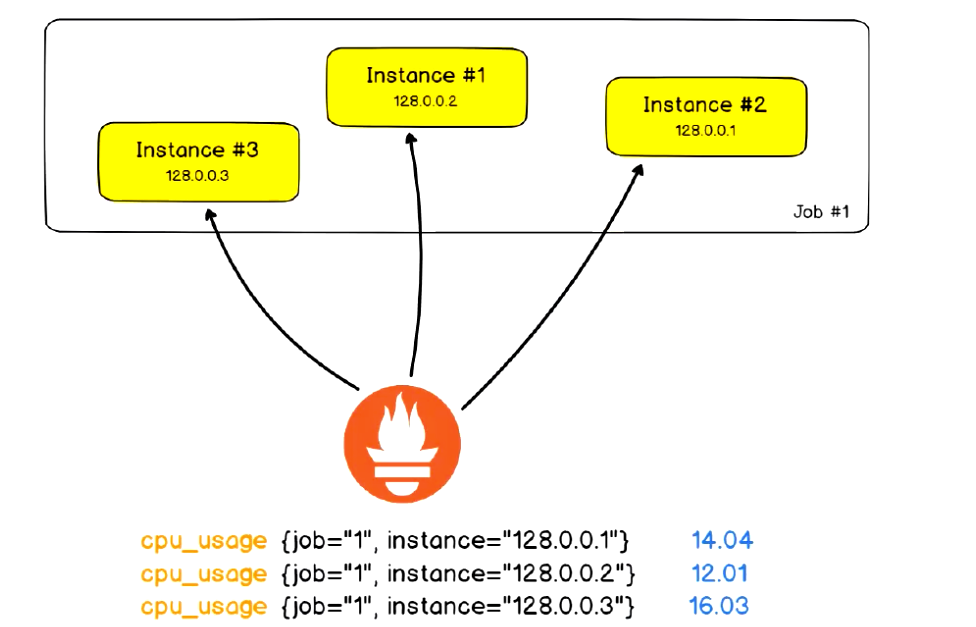
Target:又称Instance或endpoint,是metric的数据采集点。能够接收Prometheus Server数据Scrape操作的网络端点(endpoint),即为一个Instance(实例),每个Target用一个网络端点IP:PORT进行标识;每个target上有多个metric,一般通过请求IP:PORT/metrics获取。
Job:通常,具有类似功能的Instance/Target的集合称为一个Job,例如一个MySQL主从复制集群中的所有MySQL进程;
- job_name: 'mysql-server'
static_configs:
- targets: # 一个job中包含多个target
- '128.0.0.1:3306'
- '128.0.0.2:3306'
- '128.0.0.3:3306'
一个指标由指标名称和多个标签组成。而不同的标签组合会形成不同的时间序列。
job、target、metric、时间序列 的关系:
- 一个job包含多个target;
- 一个target中有多个metric;
- 一个metric包含多个时间序列;
上例中:
job为:mysql-server
target:‘128.0.0.1:3306’、‘128.0.0.2:3306’、‘128.0.0.3:3306’
metric:cpu_usage
时序:cpu_usage{job=“1”,instance=“128.0.0.1”}
时序值:14.04
当prometheus采集目标时,它会自动附加某些标签,用于识别被采集的目标。
- job: 配置目标所属的job名称
- instance: 目标 HTTP URL部分
如果任何一个标签已经存在于采集的数据中,则此行为依赖honor_labels 配置选项。
对于每个被采集的instance/target,Prometheus会自动附加存储如下的时间序列样本(指标):
- up{job=”xxx”,instance=”xxx”}:1 如果实例处于health,为1,否则为0
- scrape_duration_seconds{job=”xxx”,instance=”xxx”} 持续采集时间
“up”时间序列metric对于instance可用性监控是有效的。