004 Prom Ql详解
Prometheus提供了内置的数据查询语言PromQL (全称为Prometheus Query Language),支持用户进行实时的数据查询及聚合操作;
- PromQL使用表达式(expression)来表述查询需求
- 根据其使用的指标和标签,以及时间范围,表达式的查询请求可灵活地覆盖在一个或多个时间序列的一定范围内的样本之上,甚至是只包含单个时间序列的单个样本
基于PromQL表达式,用户可以针对指定的特征及其细分的纬度进行过滤、聚合、统计等运算从而产生期望的计算结果。
PromQL支持基于定义的指标维度进行过滤和聚合:
- 更改任何标签值,包括添加或删除标签,都会创建一个新的时间序列
- 应该尽可能地保持标签的稳定性,否则,则很可能创建新的时间序列,更甚者会生成一个动态的数据环境,并使得监控的数据源难以跟踪,从而导致建立在该指标之上的图形、告警及记录规则变得无效
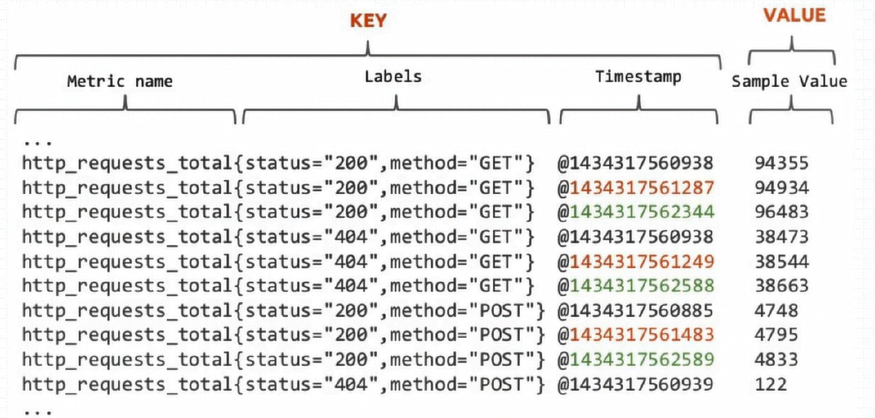
Prometheus中,每个时间序列都由指标名称(Metric Name)和标签(Label)来唯一标识,格式为<metric name>{<label name>=<label value>,…};
指标名称:通常用于描述系统上要测定的某个特征;例如,http_requests_total表示接收到的HTTP请求总数;支持使用字母、数字、下划线和冒号,且必须能匹配R规范的正则表达式;
标签:键值型数据,附加在指标名称之上,从而让指标能够支持多纬度特征;可选项;例如,
http_requests.total{method=GET}和http_requests.total{method=POST}代表着两个不同的时间序列;标签名称可使用字母、数字和下划线,且必须能匹配RE2规范的正则表达式;以__为前缀的名称为Prometheus系统预留使用;如下图所示,Metric Name的表示方式有两种。后一种通常用于Prometheus内部,但是其更加灵活,比如可以对指标名称进行正则匹配等。

指标名称和标签的特定组合代表着一个时间序列;
- 指标名称相同,但标签不同的组合分别代表着不同的时间序列;
- 不同的指标名称自然更是代表着不同的时间序列;
PromQL支持基于定义的指标维度进行过滤和聚合
- 更改任何标签值,包括添加或删除标签,都会创建一个新的时间序列
- 应该尽可能地保持标签的稳定性,否则,则很可能创建新的时间序列,更甚者会生成一个动态的数据环境,并使得监控的数据源难以跟踪,从而导致建立在该指标之上的图形、告警及记录规则变得无效
Prometheus的内部,每个样本数据都是k/v格式的数据,而且都是单独存放的。
key由metric name、labels、timestamp组成;timestamp是毫秒精度的时间戳
value是float64格式的数据
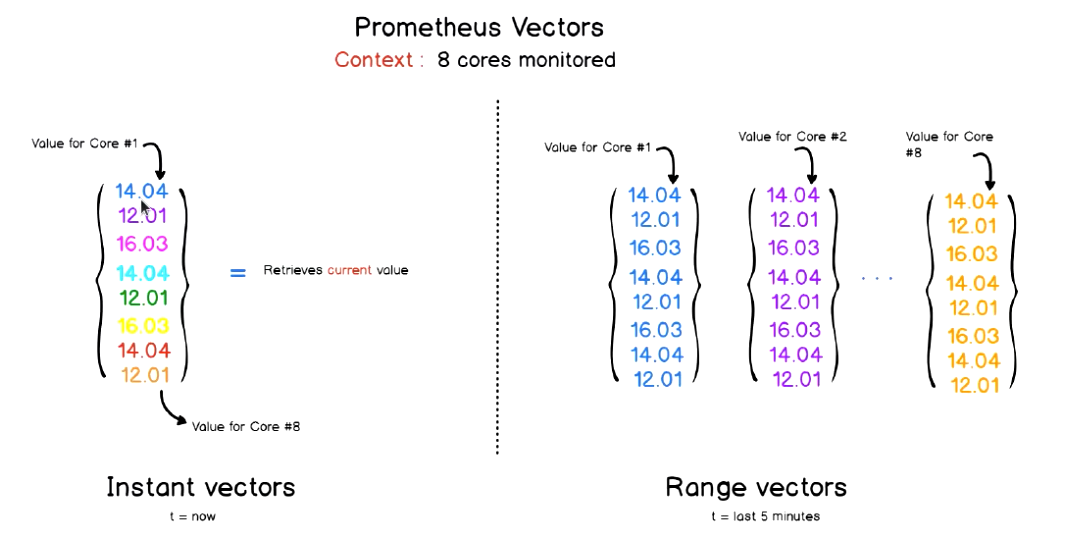
时间序列数据:按照时间顺序记录系统、设备状态变化的数据,每个数据称为一个样本;
- 数据采集以特定的时间周期进行,因而,随着时间流逝,将这些样本数据记录下来,将生成一个离散的样本数据序列;
- 时间序列也称为向量(Vector) ;而将多个序列(向量)放在同一个坐标系内(以时间为横轴,以序列为纵轴),将形成一个由数据点组成的矩阵;

上图中:
每一行表示一个时间序列;
每一列表示一个即时向量;
多个连续的列表示一个时间范围向量;
Prometheus基于指标名称(metrics name)以及附属的标签集合(labelset)唯一定义一条时间序列。
- 指标名称代表着监控目标上某类可测量属性的基本特征标识
- 标签则是这个基本特征上再次细分的多个可测量维度
注意:
指标名称和标签的特定组合代表着一个时间序列;
指标名称相同,但标签不同的组合分别代表着不同的时间序列;不同的指标名称自然更是代表着不同的时间序列;
PromQL支持处理两种向量,并内置提供了一组用于数据处理的函数
- 即时向量:最近一次的时间戳上跟踪的数据指标;
- 时间范围向量:指定时间范围内的所有时间戳上的数据指标;
PromQL的表达式中支持4种数据类型:
- 即时向量(Instant Vector):特定或全部的时间序列集合上,具有相同时间戳的一组样本值称为即时向量;
- 范围向量(Range Vector):特定或全部的时间序列集合上,在指定的同一时间范围内的所有样本值;
- 标量(Scalar):一个浮点型的数据值;
- 字符串(String) :支持使用单引号、双引号或反引号进行引用,但反引号中不会对转义字符进行转义;
理解向量与标量:
向量,无论是即时向量还是范围向量,它们时时间序列的上样本值。
标量,只是一个浮点型或整形的数值。
PromQL的查询操需要针对有限个时间序列上的样本数据进行,挑选出目标时间序列是构建表达式时最为关键的一步。
时间序列选择器的作用是:挑选出符合条件的时间序列。
时间序列选择器=指标名称+匹配器
用户可使用向量选择器表达式来挑选出给定指标名称下的所有时间序列或部分时间序列的即时(当前)样本值或至过去某个时间范围内的样本值,前者称为即时向量选择器,后者称为范围向量选择器。
- 即时向量选择器(Instant Vector Selectors):返回0个、1个或多个时间序列上在给定时间戳(instant)上的各自的一个样本,该样本也可称为即时样本;
- 范围向量选择器(Range Vector Selectors):返回0个、1个或多个时间序列上在给定时间范围内的各自的一组样本;

向量表达式使用要点:
向量表达式的返回值类型是 即时向量、范围向量、标量或字符串4种数据类型其中之一,但是,有些使用场景要求表达式返回值必须满足特定的条件,例如
需要将返回值绘制成图形时,仅支持即时向量类型的数据;
对于诸如rate一类的速率函数来说,其要求使用的必须是范围向量型的数据;
由于范围向量选择器的返回的是范围向量型数据,它不能用于表达式浏览器中图形绘制功能,否则,表达式浏览器会返回“Error executing query: invalid expressiontype "range vector" for range query, must be Scalar or instant Vector”一类的错误。事实上,范围向量选择几乎总是结合速率类的函数rate一同使用。
向量选择器由两部分组成:指标名称、匹配器,例如:http_requests_total{method ="get",env="prod"}
指标名称:用于限定特定指标下的时间序列,即负责过滤指标;可选;
匹配器(Matcher):或称为标签选择器,用于过滤时间序列上的标签;定义在{}之中;可选;
显然,定义即时向量选择器时,以上两个部分应该至少给出一个,即指标名称和标签都可以用于过滤时间序列;于是,这将存在以下三种组合;
- 仅给定指标名称,或在标签名称上使用了空值的匹配器:返回给定的指标下的所有时间序列各自的即时样本;例如,
http_requests_total和http_requests_total{}的功能相同,都是用于返回http_requests_total指标下各时间序列的即时样本; - 仅给定匹配器:返回所有符合给定的匹配器的所有时间序列上的即时样本;注意:这些时间序列可能会有着不同的指标名称;例如,
{job=".*", method="get"} - 指标名称和匹配器的组合:返回给定的指标下的,且符合给定的标签过滤器的所有时间序列上的即时样本;例如,
http_requests_total{method="get"}
匹配器用于定义标签过滤条件,其格式为:{label_name operater value,...},目前支持如下4种匹配操作符(operater);
=: Select labels that are exactly equal to the provided string.(精确等于)!=: Select labels that are not equal to the provided string.(精确不等于)=~: Select labels that regex-match the provided string.(正则匹配)!~: Select labels that do not regex-match the provided string.(正则不匹配)
注意事项:
- 匹配到空标签值的匹配器时,所有未定义该标签的时间序列同样符合条件;例如,
http_requests_total{env=""},则该指标名称上所有未使用env标签的时间序列也符合条件,比如时间序列http_requests_total{method ="get"}也会被匹配到;但是http_requests_total{method ="get",env="prod"}不会被匹配到。 - 正则表达式将执行完全锚定机制,它需要匹配指定的标签的整个值(相当于
^正则字符串$); - 向量选择器至少要包含一个指标名称,或者至少有一个不会匹配到空字符串的匹配器;例如,
{job=""}为非法的选择器;(相当于指标名称和匹配器都没有指定) - 使用特殊标签
__name__做为标签名称,还能够对指标名称进行过滤;例如,{__name__=~"http_requests_.*"}能够匹配所有以“http_requests_”为前缀的所有指标;
同即时向量选择器的唯一不同之处在于,范围向量选择器需要在表达式后紧跟一个方括号[]来表达需在时间时序上返回的样本所处的时间范围;
- 时间范围:以当前时间为基准时间点,指向过去一个特定的时间长度;例如
[5m]便是指过去5分钟之内;
时间格式:一个整数后紧跟一个时间单位,例如“5m”中的“m”即是时间单位
- 可用的时间单位有ms(毫秒)、s(秒)、m(分钟)、h(小时)、d(天)、w(周)和y (年);
- 必须使用整数时间,且能够将多个不同级别的单位进行串联组合,以时间单位由大到小为顺序,例如1h30m,但不能使用1.5h;
需要注意的是,范围向量选择器返回的是一定时间范围内的数据样本,虽然不同时间序列的数据抓取时间点相同,但它们的时间戳并不会严格对齐;
- 多个Target上的数据抓取需要分散在抓取时间点前后一定的时间范围内,以均衡Prometheus Server的负载;因而,Prometheus在趋势上准确,但并非绝对精准;
默认情况下,即时向量选择器和范围向量选择器都以当前时间为基准时间点,而偏移量修改器能够修改该基准;
偏移量修改器的使用方法是紧跟在选择器表达式之后使用“offset”关键字指定
http_requests_total offset 5m,表示获取以http_requests_total为指标名称的所有时间序列在过去5分钟之时的即时样本;http_requests_total[5m] offset 1d,表示获取距此刻1天时间之前的5分钟之内的所有样本;
PromQL有四个指标类型,它们主要由Prometheus的客户端库使用;
- Counter:计数器,单调递增,除非重置(例如服务器或进程重启);
- Gauge:仪表盘,可增可减的数据;
- Histogram:直方图,将时间范围内的数据划分成不同的时间段,并各自评估其样本个数及样本值之和,因而可计算出分位数;可用于分析因异常值而引起的平均值过大的问题;分位数计算要使用专用的histogram_quantile函数;
- Summary:类似于Histogram,但客户端会直接计算并上报分位数;
Prometheus Server并不使用类型信息,而是将所有数据展平为时间序列。
用于保存单调递增型的数据,例如站点访问次数等;不能为负值,也不支持减少,但可以重置回0;
- 计数器,用于累计值,例如 记录 请求次数、任务完成数、错误发生次数。
- 单调递增:一直增加,不会减少。
- 重启进程后,会被重置。
例如:
http_response_total{method="GET",endpoint="/api/tracks"} 10
10秒后抓取:
http_response_total{method="GET",endpoint="/api/tracks"} 100
通常,Counter的总数并不会被直接使用,而是需要借助于rate()、topk()、increase()和irate()等函数来生成样本数据的变化状况(增长率);
rate(http_requests_total[2h]),获取2小内,该指标下各时间序列上的http总请求数的增长速率;如果将此表达式绘制成图形,对于每一个样本数据的值,都会向前取2h的平均值,然后将每个平均值作图,而不是将整个时间序列按照2h的单位进行切割。topk(3,http_requests_total),获取该指标下http请求总数排名前3的时间序列;irate(http_requests_total[2h])),高灵敏度函数,用于计算指标的瞬时速率;基于样本范围内的最后两个样本进行计算,相较于rate函数来说,irate更适用于短期时间范围内的变化速率分析;
Gauge,[ɡeɪdʒ],用于存储有着起伏特征(可增可减)的指标数据,例如内存空闲大小等;
- Gauge 常规数值,例如 温度变化、CPU,内存,网络使用变化。
- 可变大,可变小。
- 重启进程后,会被重置
- Gauge是Counter的超集;但存在指标数据丢失的可能性时,Counter能让用户确切了解指标随时间的变化状态,而Gauge则可能随时间流逝而精准度越来越低;
例如:
memory_usage_bytes{host="master-01"} 100
memory_usage_bytes{host="master-01"} 30
memory_usage_bytes{host="master-01"} 50
memory_usage_bytes{host="master-01"} 80
Gauge用于存储其值可增可减的指标的样本数据,常用于进行求和sum()、取平均值avg()、最小值min()、最大值max()等聚合计算;也会经常结合PromQL的predict_linear()和delta()函数使用;
predict_linear(v range-vector,t,scalar)函数可以预测时间序列v在t秒后的值,它通过线性回归的方式来预测样本数据的Gauge变化趋势;delta(v range-vector)函数计算范围向量中每个时间序列元素的第一个值与最后一个值之差,从而展示不同时间点上的样本值的差值;例如delta(cpu_temp_celsius{host="node01"}[2h]),返回该服务器上的CPU温度与2小时之前的差异;
它会在一段时间范围内对数据进行采样,将采集到的所有数据的取值范围划分成不同的区段即bucket,每次采样的样本值并不会被记录,而只是将该值映射入其所处的bucket中,对该bucket中的计数加1,各个bucket各自评估其样本个数及样本值之和,因而可计算出分位数;
- 可用于分析因异常值而引起的平均值过大的问题;
- 分位数计算要使用专用的histogram_quantile函数;
Histogram能够存储更多的信息,包括样本值分布在每个bucket(bucket自身的可配置)中的数量、所有样本值之和以及总的样本数量,从而Prometheus能够使用内置的函数进行如下操作:
- 计算样本平均值:以值的总和除以值的数量;
- 计算样本分位值:分位数有助于了解符合特定标准的数据个数;例如评估响应时长超过1秒钟的请求比例,若超过20%即发送告警等;
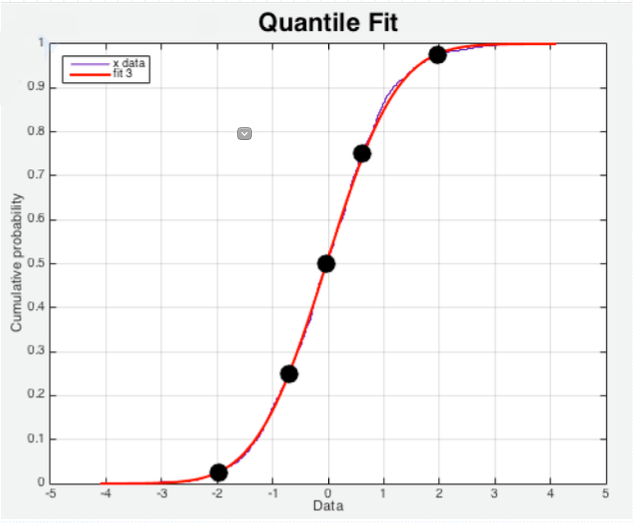
什么是99%分位数(分位值):
统计学中,把所有数值由小到大排列,并将样本数量分成100等份,位于99份位置的值,称之为99%分位数。比如一个班级里有100名学生的数学考试分数,将所有成绩从小到大排序后,第99名学生的考试分数的即为99%分位数。再例如,网站请求响应时间的99%分位数为1.2s,则表示99%的请求响应时间都低于1.2s。
Histogram 可以理解为柱状图的意思,常用于跟踪事件发生的规模,例如:请求耗时、响应大小。它特别之处是可以对记录的内容进行分组,提供 count 和 sum 全部值的功能。
例如:
# HELP prometheus_http_request_duration_seconds Histogram of latencies for HTTP requests.
# TYPE prometheus_http_request_duration_seconds histogram
prometheus_http_request_duration_seconds_bucket{handler="/-/reload",le="0.1"} 0
prometheus_http_request_duration_seconds_bucket{handler="/-/reload",le="0.2"} 19546
prometheus_http_request_duration_seconds_bucket{handler="/-/reload",le="0.4"} 19762
prometheus_http_request_duration_seconds_bucket{handler="/-/reload",le="1"} 19766
prometheus_http_request_duration_seconds_bucket{handler="/-/reload",le="3"} 19766
prometheus_http_request_duration_seconds_bucket{handler="/-/reload",le="8"} 19766
prometheus_http_request_duration_seconds_bucket{handler="/-/reload",le="20"} 19766
prometheus_http_request_duration_seconds_bucket{handler="/-/reload",le="60"} 19766
prometheus_http_request_duration_seconds_bucket{handler="/-/reload",le="120"} 19766
prometheus_http_request_duration_seconds_bucket{handler="/-/reload",le="+Inf"} 19766
prometheus_http_request_duration_seconds_sum{handler="/-/reload"} 2877.6365913859995
prometheus_http_request_duration_seconds_count{handler="/-/reload"} 19766
le="0.4"时,19762/19766*100=99.98%,表示所有的请求中有99.98%的请求的响应时间≤0.4s。
Histogram是一种对数据分布情况的图形表示,由一系列高度不等的长条图(bar)或线段表示,用于展示单个测度的值的分布。
- 它一般用横轴表示某个指标维度的数据取值区间,用纵轴表示样本统计的频率或频数,从而能够以二维图的形式展现数值的分布状况
- 为了构建Histogram,首先需要将值的范围进行分段,即将所有值的整个可用范围分成一系列连续、相邻(相邻处可以是等同值)但不重叠的间隔,而后统计每个间隔中有多少值。
- 从统计学的角度看,分位数不能被聚合,也不能进行算术运算;
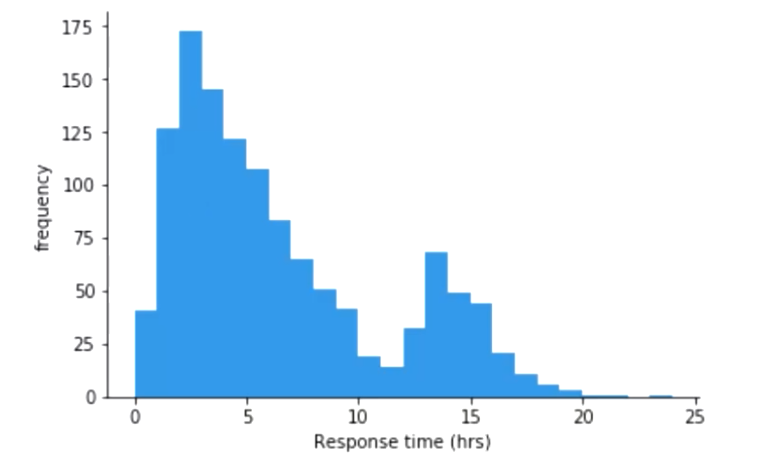
对于Prometheus来说,Histogram会在一段时间范围内对数据进行采样(通常是请求持续时长或响应大小等),并将其计入可配置的bucket(存储桶)中
- Histogram事先将特定测度可能的取值范围分隔为多个样本空间(bucket),并通过对落入bucket内的观测值进行计数以及求和操作。
- 与常规方式略有不同的是,Prometheus取值间隔的划分采用的是累积(Cumulative)区间间隔机制,即每个bucket中的样本均包含了其前面所有bucket中的样本,因而也称为累积直方图。这样的好处:可降低Histogram的维护成本;支持粗略计算样本值的分位数;单独提供了
_sum和_count指标,从而支持计算平均值。

Histogram类型的每个指标有一个基础指标名称<basename>,它会提供多个时间序列:
<basename>_bucket{le="<upper inclusive bound>"}:观测桶的上边界(upper inclusive bound),即样本统计区间上限。例如,最大区间(包含所有样本)的名称为<basename>_bucket{le="+Inf"};“le”指小于等于“≤”。<basename>_sum:所有样本的值之和;<basename>_count:所有样本的个数,它自身本质上是一个Counter类型的指标;
累计间隔机制生成的样本数据需要额外使用内置的histogram_quantile()函数即可根据Histogram指标来计算相应的分位数(quantile),即某个bucket的样本数在所有样本数中占据的比例
histogram_quantile()函数在计算分位数时会假定每个区间内的样本满足线性分布状态,因而它的结果仅是一个预估值,并不完全准确;- 预估的准确度取决于bucket区间划分的粒度;粒度越大,准确度越低;
类似于Histogram,是Histogram的扩展类型,但它是直接由被监测端(客户端)自行聚合计算出分位数;并将计算结果响应给Prometheus Server的样本采集请求;因而,其分位数计算是由监控端完成的。
Summary和Histogram十分相似,常用于跟踪事件(通常是要求持续时间和响应大小)发生的规模,例如:请求耗时、响应大小。同样提供 count 和 sum 全部值的功能。 例如:count=7次,sum=7次的值求值 它提供一个quantiles的功能,可以按百分比划分跟踪的结果。例如:quantile取值0.95,表示取采样值里面的95%数据。
指标类型是客户端库的特性,而Histogram在客户端仅是简单的桶划分和分桶计数分位数计算由Prometheus Server基于样本数据进行估算,因而其结果未必准确,甚至不合理的bucket划分会导致较大的误差;
Summary是一种类似于Histogram的指标类型,但它在客户端于一段时间内(默认为10分钟)的每个采样点进行统计,计算并存储了分位数数值,Server端直接抓取相应值即可;但Summary不支持sum或avg类的聚合运算,而且其分位数由客户端计算并生成,Server端无法获取客户端未定义的分位数,而Histogram可通过PromQL任意定义,有着较好的灵活性;
prometheus_rule_evaluation_duration_seconds{quantile="0.5"} 0.001077325
prometheus_rule_evaluation_duration_seconds{quantile="0.9"} 0.001439236
prometheus_rule_evaluation_duration_seconds{quantile="0.99"} 0.002016637 #采样值中,99%的数据值满足≤0.002016637
prometheus_rule_evaluation_duration_seconds_sum 0.031004541000000007
prometheus_rule_evaluation_duration_seconds_count 3
对于每个指标,Summary以指标名称<basename>为前缀,生成如下几个个指标序列
<basename>{quantile="<φ>"},其中φ是分位点,其取值范围是(0≤φ≤1);计数器类型指标;如下是几种典型的常用分位点;- 0、0.25、0.5、0.75和1几个分位点;
- 0.5、0.9和0.99几个分位点;
- 0.01、0.05、0.5、0.9和0.99几个分位点;
<basename>_sum:抓取到的所有样本值之和;<basename>_count:抓取到的所有样本总数;
一般说来,单个指标的价值不大,监控场景中往往需要联合并可视化一组指标,这种联合机制即是指“聚合”操作,例如,将计数、求和、平均值、分位数、标准差及方差等统计函数应用于时间序列的样本之上生成具有统计学意义的结果等;
对查询结果事先按照某种分类机制进行分组(groupby)并将查询结果按组进行聚合计算也是较为常见的需求,例如分组统计、分组求平均值、分组求和等;
聚合操作由聚合函数针对一组值进行计算并返回单个值或少量几值作为结果
- Prometheus内置提供的11个聚合函数,也称为聚合运算符
- 这些运算符仅支持应用于单个即时向量的元素,其返回值也是具有少量元素的新向量或标量(划重点:聚合函数只能用于即时向量)
- 这些聚合运行符既可以基于向量表达式返回结果中的时间序列的所有标签维度进行分组聚合,也可以仅基于指定的标签维度分组后再进行分组聚合
11个聚合函数:
- sum():对样本值求和;
- avg():对样本值求平均值,这是进行指标数据分析的标准方法;
- count():对分组内的时间序列进行数量统计;
- stddev():对样本值求标准差,以帮助用户了解数据的波动大小(或称之为波动程度);
- stdvar():对样本值求方差,它是求取标准差过程中的中间状态;
- min():求取样本值中的最小者;
- max():求取样本值中的最大者;
- topk():逆序返回分组内的样本值最大的前k个时间序列及其值;
- bottomk ():顺序返回分组内的样本值最小的前k个时间序列及其值;
- quantile():分位数用于评估数据的分布状态,该函数会返回分组内指定的分位数的值,即数值落在小于等于指定的分位区间的比例;
- count_values():对分组内的时间序列的样本值进行数量统计;
最后4个聚合函数,需要指定parameter。
PromQL中的聚合操作语法格式可采用如下面两种格式之一
<aggr-op>([parameter,]<vector expression>)[without|by(<label list>)]
<aggr-op>[without|by(<label list>)]([parameter,]<vector expression>)
分组聚合:先分组、后聚合
如何分组?
- without:从结果向量中删除由without子句指定的标签,未指定的那部分标签则用作分组标准;(without排除指定标签后,再使用剩余的标签做聚合)
- by:功能与without刚好相反,它仅使用by子句中指定的标签进行聚合,结果向量中出现但未被by子句指定的标签则会被忽略;
- 为了保留上下文信息,使用by子句时需要显式指定其结果中原本出现的job、instance等一类的标签
事实上,各函数工作机制的不同之处也仅在于计算操作本身,PromQL对于它们的执行逻辑相似;
sum (node_filesystem_avail_bytes) by (instance) #*每个*节点上,所有磁盘的剩余磁盘空间之和
参考文档:https://prometheus.io/docs/prometheus/latest/querying/operators/
PromQL支持基本的算术运算和逻辑运算,这类运算支持使用操作符连接两个操作数,因而也称为二元运算符或二元操作符; 支持的运算:
- 两个标量间运算;例如
1+2,5%2 - 即时向量和标量间的运算:将运算符应用于向量上的每个样本;例如,3个时间序列的即时向量✖️2:
(1,2,3)* 2 =(2,4,5),例如0.1 * rate(http_requests_total[5m] - 两个即时向量间的运算:遵循向量匹配机制(见下文);将运算符用于两个即时向量间的运算时,可基于向量匹配模式(Vector Matching)定义其运算机制;
常用的二元运算:
算术运算:支持的运算符:+(加)、-(减)、*(乘)、/(除)、%(取模)和^(幂运算);
比较运算:支持的运算符:==(等值比较)、!=(不等)、>、く、>=和<=(小于等于);
逻辑/集合运算:支持的运算符:and (并且) 、or(或者)和unless(除了);目前,该运算仅允许在两个即时向量间进行,尚不支持标量参与运算;
即时向量间的运算是PromQL的特色之一;运算时,PromQL会为左侧向量中的每个元素找到匹配的元素,其匹配行为有两种基本类型:
- 一对一(One-to-One)
- 一对多或多对一(Many-to-One,One-to-Many)


即时向量的一对一匹配
- 从运算符的两边表达式所获取的即时向量间依次比较,并找到唯一匹配(标签完全一致,指标名称不做比较)的样本值;
- 找不到匹配项的值则不会出现在结果中;
匹配表达式语法
<vector expr> <bin-op> ignoring(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) <vector expr>
- ignoring:定义匹配检测时要忽略的标签;其他标签一致即可
- on:定义匹配检测时只使用的标签;默认所有标签
示例1:
时间序列:http_requests_total{status_code=,path=}
rate(http_requests_total{status_code=~"5.*"}[5m]) > 0.1 * sum by(path)(rate(http_requests_total[5m]))
rate(prometheus_http_requests_total{code=~'2.*'}[5m]) > on (handler) 0.1*sum by (handler)(rate(prometheus_http_requests_total{}[5m]))
#每个path下,5xx的请求占比
左侧会生成一个即时向量,它计算出5xx响应码的各类请求的增长速率;除了status_code标签外,该指标通常还有其它标签;于是,status_code的值为500的标签同其它标签的每个组合将代表一个时间序列,其相应的即时样本即为结果向量的一个元素;
右侧会生成一个即时向量,它计算出所有标签组合所代表的各类请求的增长速率;
计算时,PromQL会在操作符左右两侧的结果元素中找到标签完全一致的元素进行比较;其意义为,计算出每类请求中的5xx响应码在该类请求中所占的比例;
示例2:

示例3:对于prometheus_http_requests_total指标,如何求出每个handler下,2xx响应码的占比是否大于10%?
1、先查看2XX响应码的rate值:rate(prometheus_http_requests_total{code=~'2.*'}[5m])
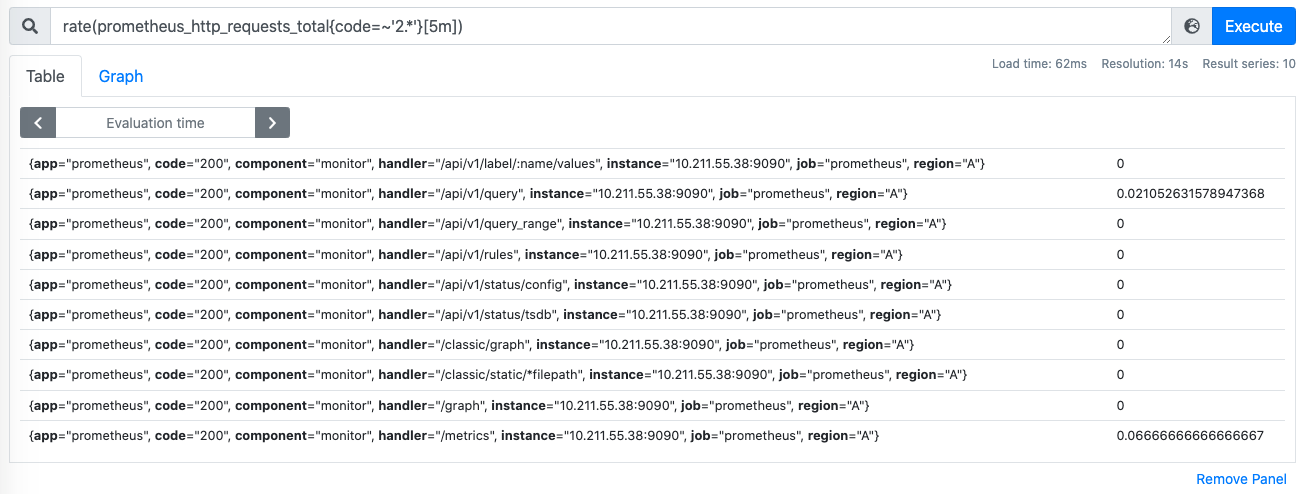
2、查看所有响应码的时间序列:rate(prometheus_http_requests_total{}[5m])
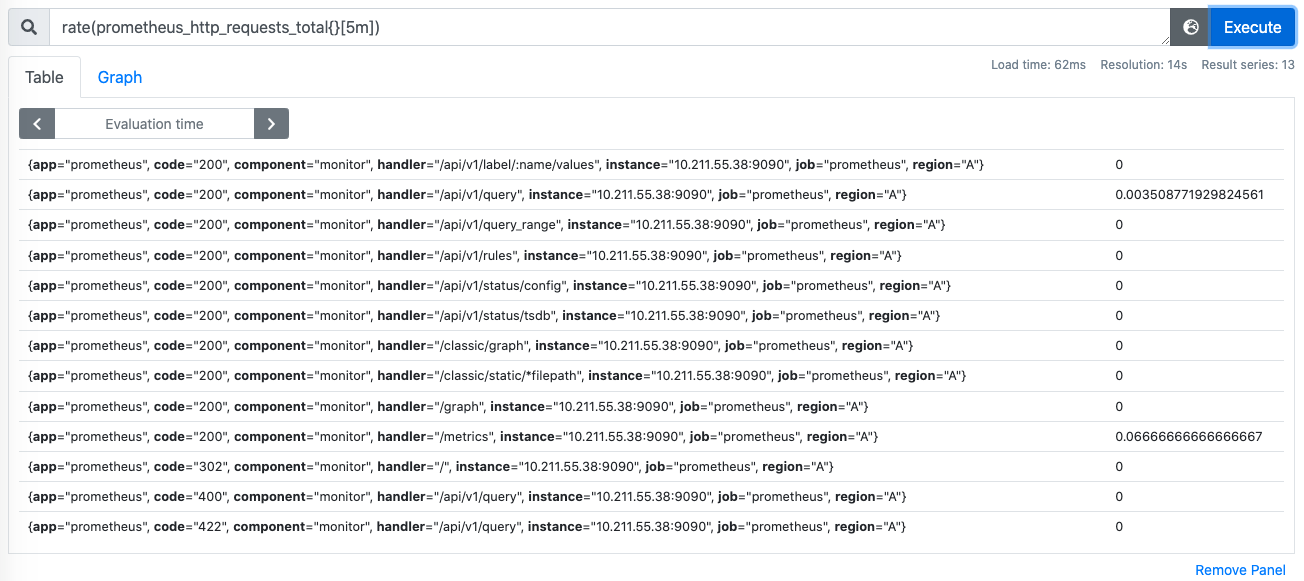
要求对于每个handler,求2xx的占比,所以需要先分组,按照handler分组后,进行sum()操作:
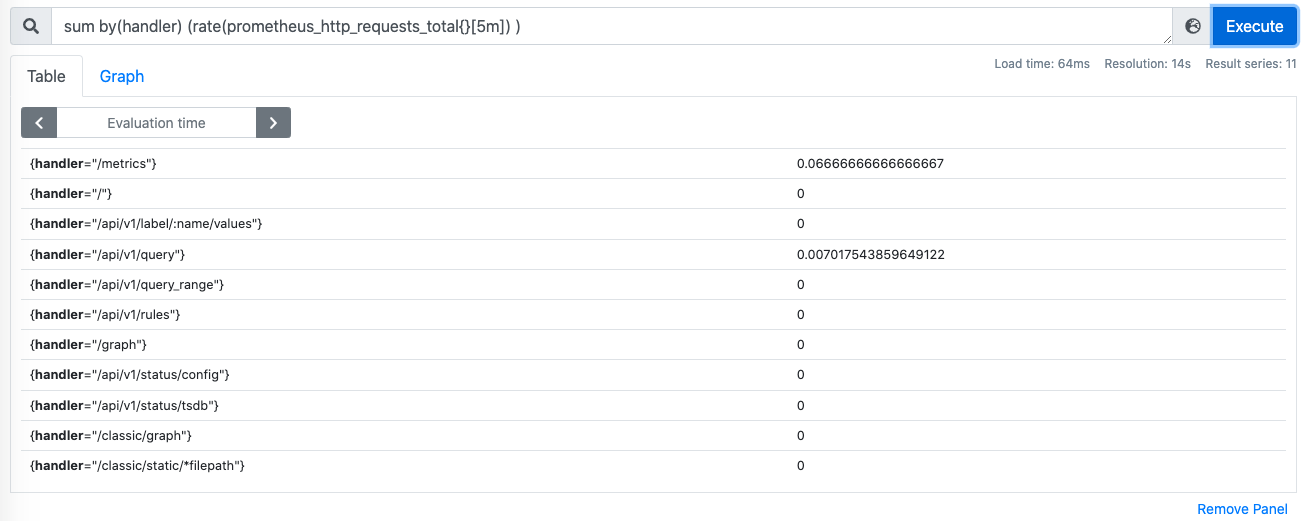
对sum结果乘以10%:
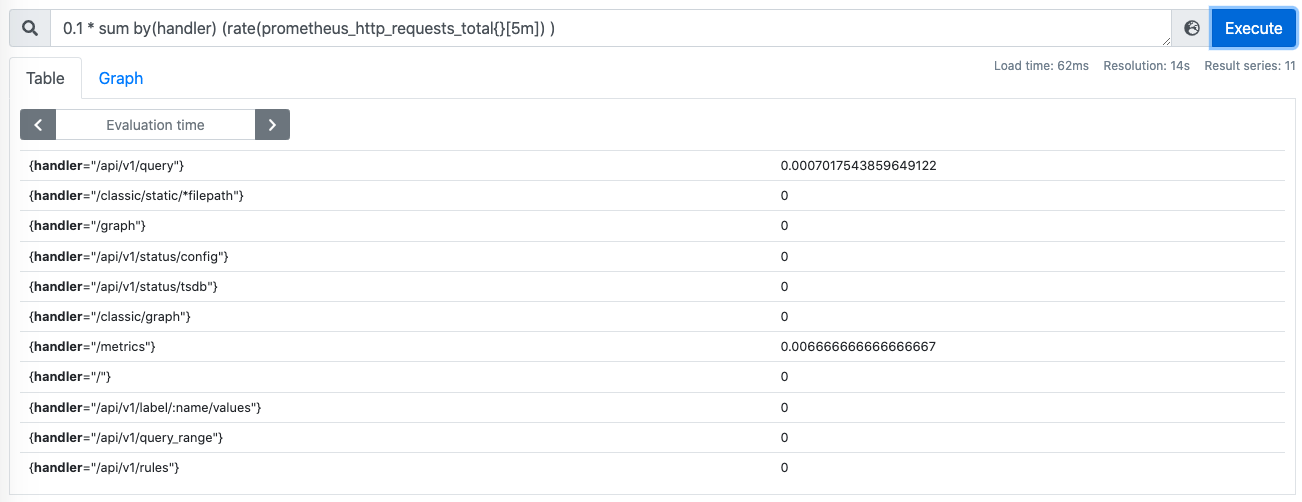
注意,此时,标签只剩余hander一个标签了。为了满足one-to-one匹配,使用on进行匹配,即

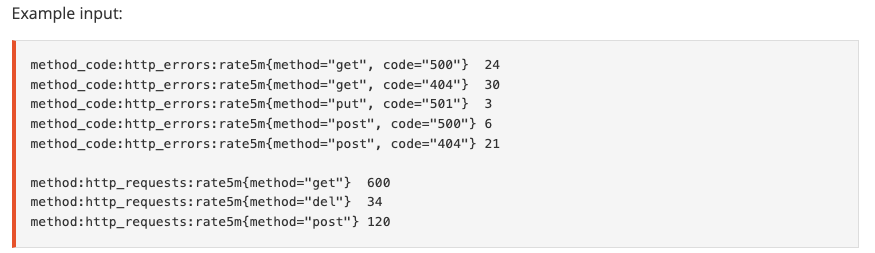
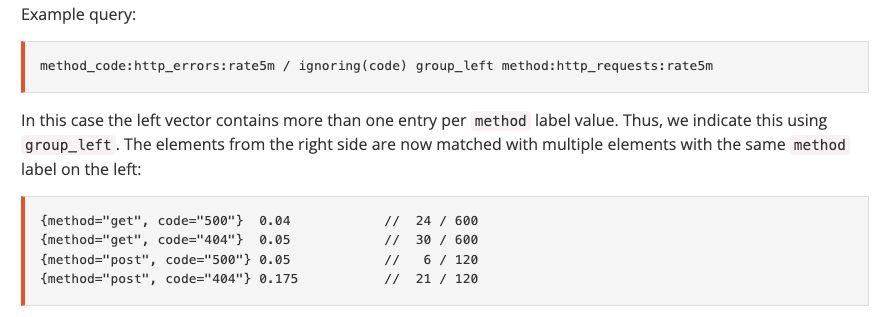
“一”侧的每个元素,可与“多”侧的多个元素进行匹配;只必须使用group_left或group_right明确指定哪侧为“多”侧;
匹配表达式语法
<vector expr> <bin-op> ignoring(<label list>) group_left(<label list>) <vector expr> #左侧为“多”侧
<vector expr> <bin-op> ignoring(<label list>) group_right(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) group_left(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) group_right(<label list>) <vector expr>
**示例:**不同响应码在该类请求方法中的占比
官方文档:https://prometheus.io/docs/prometheus/latest/querying/functions/