02 Telegraf安装与入门
https://blog.csdn.net/lulongji2035/article/details/109029677
https://www.cnblogs.com/boshen-hzb/p/9674087.html
“Telegraf is an agent for collecting, processing, aggregating, and writing metrics.
Design goals are to have a minimal memory footprint with a plugin system so that developers in the community can easily add support for collecting metrics.”
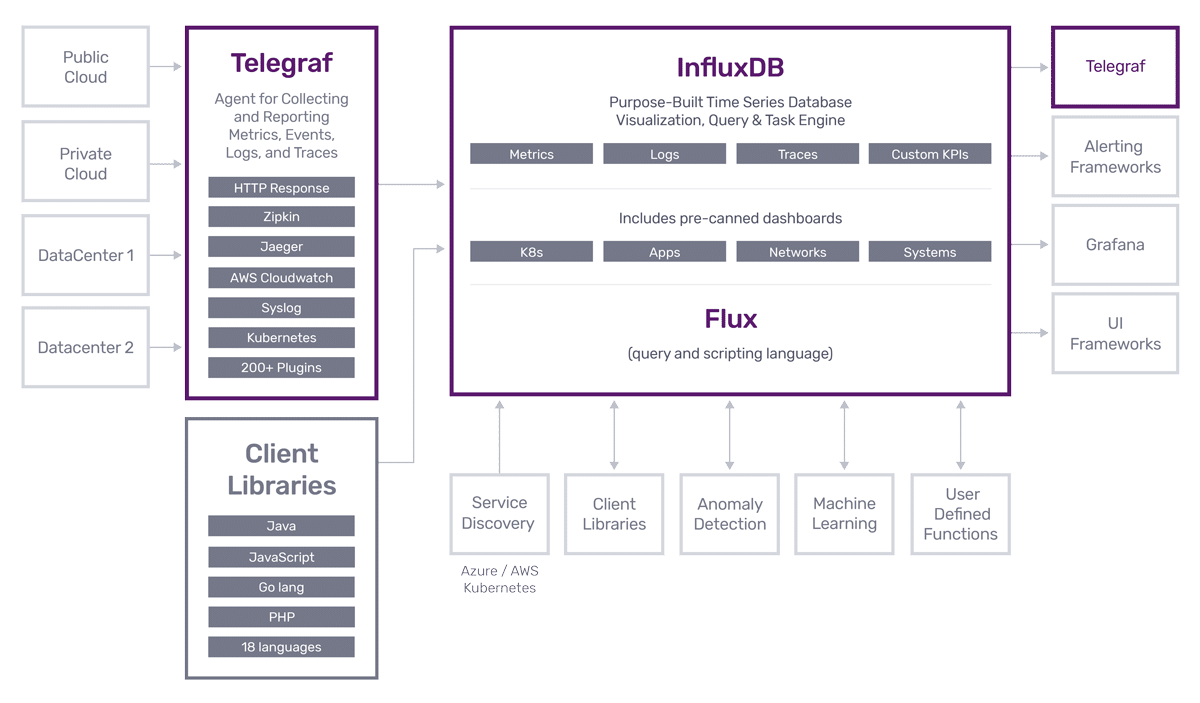
在Prometheus系统中,Telegraf充当了Metric exporter的功能,得益于Telegraf强大的插件架构,可以实现各式各样的数据采集模式(不管是作为client端,还是server端),然后输出到后端的数据存储(比如Prometheus)。
Telegraf官网:https://www.influxdata.com/time-series-platform/telegraf/
官方文档:https://docs.influxdata.com/telegraf/v1.21/
Telegraf GitHub代码仓库地址: https://github.com/influxdata/telegraf
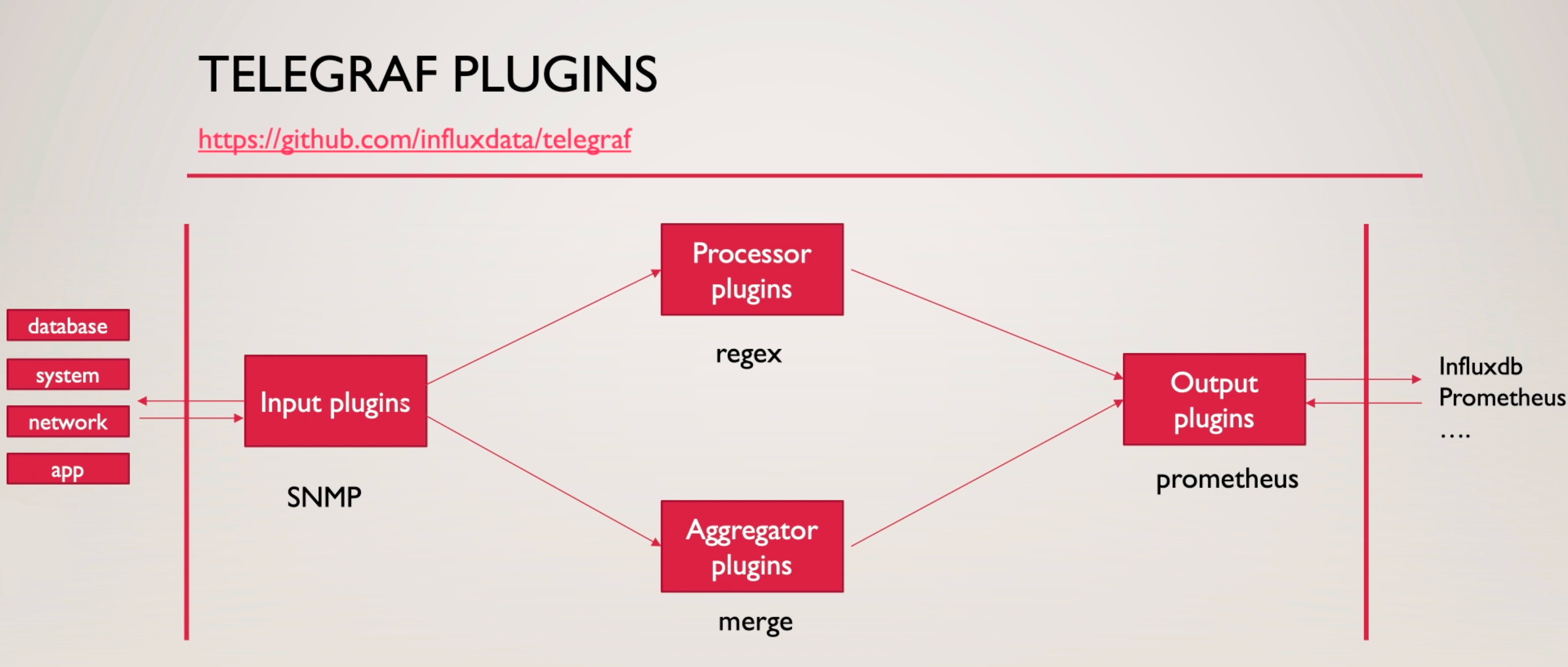
Telegraf 是 InfluxData 开源的一款采集器,可以采集操作系统、各种中间件的监控指标,采集目标列表:https://github.com/influxdata/telegraf/tree/master/plugins/inputs 看起来是非常丰富,Telegraf是一个大一统的设计,即一个二进制可以采集CPU、内存、mysql、mongodb、redis、snmp等,不像Prometheus的exporter,每个监控对象一个exporter,管理起来略麻烦。一个二进制分发起来确实比较方便。
但是,Telegraf主要是为InfluxDB设计的,采集的很多监控指标,标签部分可能不固定,比如net_response这个采集input插件,在成功的时候,会附一个标签:result=success,超时的时候,又会变成:result=timeout,对于InfluxDB的存储模型和使用方式来说,这样做是没问题的,但是大部分时序库都不喜欢这个玩法,时序库更喜欢标签是稳态的,因为标签是监控数据的唯一标识,如果标签发生变化,就相当于是新的监控数据了,这就有点恶心了。好在Telegraf提供了一些配置机制,可以把部分标签给干掉,只留那些稳定的标签,这样就舒服多了。上面这段话不理解也没关系,后面慢慢就有感触了。
调研Telegraf是希望把Telegraf作为夜莺的一种采集端程序使用,夜莺自身是有一个Agentd的,但是支持的采集内容有限,v5版本开始,拥抱Prometheus生态,故而可以和Prometheus生态的各类Exporter协同,但是Exporter是每类监控对象一个,不太方便管理,另外就是Exporter是pull模型,夜莺的设计中,会对监控对象做额外的产品支持,需要从监控数据中解析出监控对象,pull模型的exporter,直接由Prometheus进程来采集,数据压根就不会流经夜莺的服务端,所以夜莺无法感知到这些数据,更别提解析这些数据了。Telegraf有很多output插件,比如可以把采集到的监控数据输出给InfluxDB、OpenTSDB、Prometheus、Kafka等,夜莺只要实现比如OpenTSDB的接收数据的HTTP接口,就可以接收Telegraf推送的数据啦,这样数据就会先流经夜莺的服务端,在服务端做解析,提取监控对象,做一些Nodata判断等,与夜莺的生态良好的集成到了一起。
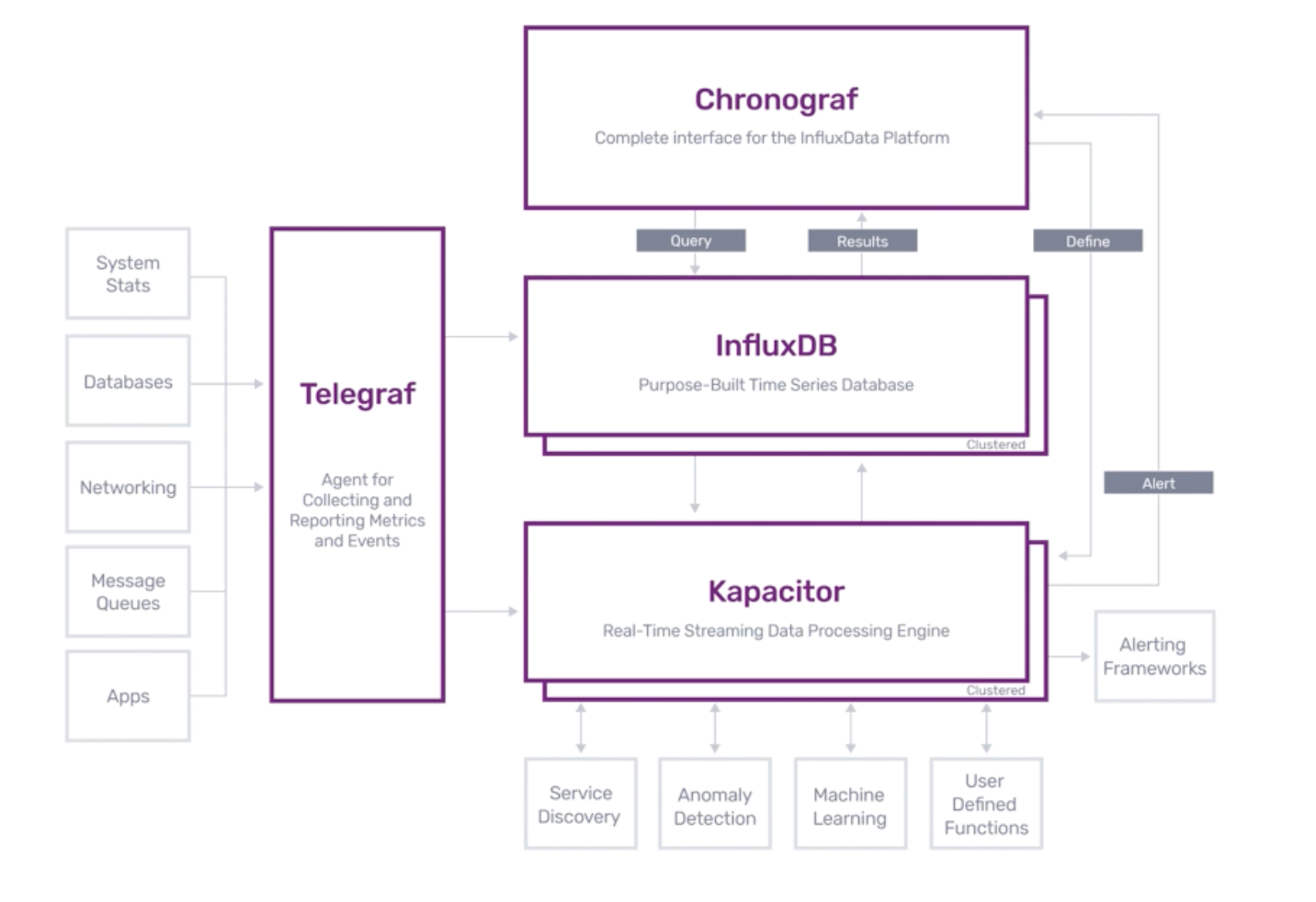
TICK:
Telegraf的安装,非常简单,直接从官网下载编译好的二进制即可,或者自己编译也OK,比如64位Linux环境下,可以从这里下载:https://dl.influxdata.com/telegraf/releases/telegraf-1.20.2linuxamd64.tar.gz
下载之后,解压缩,看到如下目录结构:usr/bin/telegraf是二进制,etc/telegraf/telegraf.conf是配置文件,usr/lib下还给准备好了service文件,便于用systemd托管,如何作为后台程序去运行,看你自己癖好了,这是Linux基础知识,这里不再赘述。
├── etc
│ ├── logrotate.d
│ │ └── telegraf
│ └── telegraf
│ ├── telegraf.conf
│ └── telegraf.d
├── usr
│ ├── bin
│ │ └── telegraf
│ └── lib
│ └── telegraf
│ └── scripts
│ ├── init.sh
│ └── telegraf.service
└── var
└── log
└── telegraf
telegraf执行命令(前台运行):
telegraf --config telegraf.conf
telegraf 可以根据需要采集的数据需求生成相应的配置文件,生成指定输入和输出插件的配置文件格式如下:
telegraf --input-filter <pluginname>[:<pluginname>] --output-filter <outputname>[:<outputname>] config > telegraf.conf
生成带cpu、memroy、http_listener和influxdb插件的配置文件:
telegraf --input-filter cpu:mem:http_listener --output-filter influxdb config > telegraf.conf
生成带 cpu、memroy、disk、diskio、net 和 influxdb 插件的配置文件 telegraf.conf,指定输出到 influxdb和 opentsdb:
telegraf --input-filter cpu:mem:disk:diskio:net --output-filter influxdb:opentsdb config > telegraf.conf
默认的配置文件生成:
telegraf --input-filter cpu:mem:http_listener --output-filter influxdb config
一些测试示例:
# 测试 /etc/telegraf/telegraf.conf 配置文件中输入 cpu 配置是否正确
telegraf -config /etc/telegraf/telegraf.conf -input-filter cpu -test
# 测试 /etc/telegraf/telegraf.conf 输出 influxdb 配置是否正确
telegraf -config /etc/telegraf/telegraf.conf -output-filter influxdb -test
# 测试 /etc/telegraf/telegraf.d/mysql.conf 输入 cpu 和 输出 influxdb 配置是否正确
telegraf -config /etc/telegraf/telegraf.d/mysql.conf -input-filter cpu -output-filter influxdb -test
Telegraf有一些可以在配置[agent]部分下配置的选项。
- interval:所有输入的默认数据收集间隔
- round_interval:将收集间隔舍入为“interval”例如,如果interval =“10s”则始终收集于:00,:10,:20等。
- metric_batch_size:Telegraf将指标发送到大多数
metric_batch_size指标的批量输出。 - metric_buffer_limit:Telegraf将缓存
metric_buffer_limit每个输出的指标,并在成功写入时刷新此缓冲区。这应该是倍数,metric_batch_size不能少于2倍metric_batch_size。 - collection_jitter:集合抖动用于随机抖动集合。每个插件在收集之前将在抖动内随机休眠一段时间。这可以用来避免许多插件同时查询sysfs之类的东西,这会对系统产生可测量的影响。
- flush_interval:所有输出的默认数据刷新间隔。您不应将此设置为以下间隔。最大值
flush_interval为flush_interval+flush_jitter - flush_jitter:将刷新间隔抖动一个随机量。这主要是为了避免运行大量Telegraf实例的用户出现大量写入峰值。例如,
flush_jitter5s和flush_interval10s之一意味着每10-15秒就会发生一次冲洗。 - precision:默认情况下,precision将设置为与收集时间间隔相同的时间戳顺序,最大值为1s。精度不会用于服务输入,例如
logparser和statsd。有效值为ns,us(或µs)ms,和s。 - logfile:指定日志文件名。空字符串表示要登录
stderr。 - debug:在调试模式下运行Telegraf。
- quiet:以安静模式运行Telegraf(仅限错误消息)。
- hostname:覆盖默认主机名,如果为空使用
os.Hostname()。 - omit_hostname:如果为true,则不
host在Telegraf代理中设置标记。
以下配置参数可用于所有输入:
- interval:收集此指标的频率。普通插件使用单个全局间隔,但是如果一个特定输入应该运行得更少或更频繁,则可以在此处进行配置。
- name_override:覆盖度量的基本名称。(默认为输入的名称)。
- name_prefix:指定附加到度量名称的前缀。
- name_suffix:指定附加到度量名称的后缀。
- tags:要应用于特定输入测量的标签映射。
以下配置参数可用于所有聚合器:
- period:刷新和清除每个聚合器的时间段。聚合器将忽略在此时间段之外使用时间戳发送的所有度量标准。
- delay:刷新每个聚合器之前的延迟。这是为了控制聚合器在从输入插件接收度量标准之前等待多长时间,如果聚合器正在刷新并且输入在相同的时间间隔内收集。
- drop_original:如果为true,聚合器将丢弃原始度量标准,并且不会将其发送到输出插件。
- name_override:覆盖度量的基本名称。(默认为输入的名称)。
- name_prefix:指定附加到度量名称的前缀。
- name_suffix:指定附加到度量名称的后缀。
- tags:要应用于特定输入测量的标签映射。
以下配置参数可用于所有处理器:
- order:这是执行处理器的顺序。如果未指定,则处理器执行顺序将是随机的。
可以根据输入,输出,处理器或聚合器配置过滤器,请参阅下面的示例。
- namepass:一个glob模式字符串数组。仅发出测量名称与此列表中的模式匹配的点。
- 命名工作:逆转
namepass。如果找到匹配,则丢弃该点。这是在通过namepass测试后的点上测试的。 - fieldpass:一个glob模式字符串数组。仅发出其字段键与此列表中的模式匹配的字段。不适用于输出。
- fielddrop:逆的
fieldpass。具有匹配其中一个模式的字段键的字段将从该点中丢弃。不适用于输出。 - tagpass:将标记键映射到glob模式字符串数组的表。仅发出表中包含标记键的点和与其模式之一匹配的标记值。
- tagdrop:逆的
tagpass。如果找到匹配,则丢弃该点。这是在通过tagpass测试后的点上测试的。 - taginclude:一个glob模式字符串数组。仅发出具有与其中一个模式匹配的标签键的标签。相反
tagpass,它将根据其标记传递整个点,taginclude从该点移除所有不匹配的标记。此滤波器可用于输入和输出,但 建议在输入上使用,因为在摄取点过滤掉标签更有效。 - tagexclude:倒数
taginclude。具有与其中一个模式匹配的标记键的标记将从该点被丢弃。
注意: 由于解析TOML的方式,tagpass并且tagdrop必须在插件定义的末尾定义参数,否则后续插件配置选项将被解释为tagpass / tagdrop表的一部分。
我们来测试采集CPU相关的指标,命令如下:
./usr/bin/telegraf --config etc/telegraf/telegraf.conf --test --input-filter cpu
通过–config指定配置文件,–test表示本次仅仅是个测试,测试跑完了,进程就立马退出,–input-filter是采集插件过滤,这里的意思是只运行cpu这个插件,即只采集CPU相关的指标
输出内容如下:
[root@172-20-24-219 telegraf-1.20.2]# ./usr/bin/telegraf --config etc/telegraf/telegraf.conf --test --input-filter cpu
2021-11-05T00:48:50Z I! Starting Telegraf 1.20.2
> cpu,cpu=cpu0,host=172-20-24-219 usage_guest=0,usage_guest_nice=0,usage_idle=98.03921568448419,usage_iowait=0,usage_irq=0,usage_nice=0,usage_softirq=0,usage_steal=0,usage_system=1.960784313690687,usage_user=0 1636073331000000000
> cpu,cpu=cpu1,host=172-20-24-219 usage_guest=0,usage_guest_nice=0,usage_idle=100,usage_iowait=0,usage_irq=0,usage_nice=0,usage_softirq=0,usage_steal=0,usage_system=0,usage_user=0 1636073331000000000
> cpu,cpu=cpu2,host=172-20-24-219 usage_guest=0,usage_guest_nice=0,usage_idle=100,usage_iowait=0,usage_irq=0,usage_nice=0,usage_softirq=0,usage_steal=0,usage_system=0,usage_user=0 1636073331000000000
> cpu,cpu=cpu3,host=172-20-24-219 usage_guest=0,usage_guest_nice=0,usage_idle=100,usage_iowait=0,usage_irq=0,usage_nice=0,usage_softirq=0,usage_steal=0,usage_system=0,usage_user=0 1636073331000000000
> cpu,cpu=cpu-total,host=172-20-24-219 usage_guest=0,usage_guest_nice=0,usage_idle=99.50248752715007,usage_iowait=0,usage_irq=0,usage_nice=0,usage_softirq=0,usage_steal=0.49751243763529784,usage_system=0,usage_user=0 1636073331000000000
如果要同时采集cpu和内存呢?这么这么来搞:
./usr/bin/telegraf --config etc/telegraf/telegraf.conf --test --input-filter cpu:mem
2021-11-05T00:51:47Z I! Starting Telegraf 1.20.2
> mem,host=172-20-24-219 active=744894464i,available=7693004800i,available_percent=93.8048142657935,buffered=2662400i,cached=1393319936i,commit_limit=4100538368i,committed_as=392212480i,dirty=0i,free=6590001152i,high_free=0i,high_total=0i,huge_page_size=2097152i,huge_pages_free=0i,huge_pages_total=0i,inactive=623808512i,low_free=0i,low_total=0i,mapped=54579200i,page_tables=3637248i,shared=17301504i,slab=146083840i,sreclaimable=97878016i,sunreclaim=48205824i,swap_cached=0i,swap_free=0i,swap_total=0i,total=8201076736i,used=215093248i,used_percent=2.6227439996483897,vmalloc_chunk=35184340365312i,vmalloc_total=35184372087808i,vmalloc_used=23142400i,write_back=0i,write_back_tmp=0i 1636073507000000000
> cpu,cpu=cpu0,host=172-20-24-219 usage_guest=0,usage_guest_nice=0,usage_idle=100,usage_iowait=0,usage_irq=0,usage_nice=0,usage_softirq=0,usage_steal=0,usage_system=0,usage_user=0 1636073508000000000
> cpu,cpu=cpu1,host=172-20-24-219 usage_guest=0,usage_guest_nice=0,usage_idle=100,usage_iowait=0,usage_irq=0,usage_nice=0,usage_softirq=0,usage_steal=0,usage_system=0,usage_user=0 1636073508000000000
> cpu,cpu=cpu2,host=172-20-24-219 usage_guest=0,usage_guest_nice=0,usage_idle=100,usage_iowait=0,usage_irq=0,usage_nice=0,usage_softirq=0,usage_steal=0,usage_system=0,usage_user=0 1636073508000000000
> cpu,cpu=cpu3,host=172-20-24-219 usage_guest=0,usage_guest_nice=0,usage_idle=100,usage_iowait=0,usage_irq=0,usage_nice=0,usage_softirq=0,usage_steal=0,usage_system=0,usage_user=0 1636073508000000000
> cpu,cpu=cpu-total,host=172-20-24-219 usage_guest=0,usage_guest_nice=0,usage_idle=100,usage_iowait=0,usage_irq=0,usage_nice=0,usage_softirq=0,usage_steal=0,usage_system=0,usage_user=0 1636073508000000000
–input-filter cpu:mem 指定要同时运行cpu和内存两个采集插件,输出的内容格式是InfluxDB生态的格式.
我们随便分析一条,比如最后这一条:
cpu,cpu=cpu-total,host=172-20-24-219 usage_guest=0,usage_guest_nice=0,usage_idle=100,usage_iowait=0,usage_irq=0,usage_nice=0,usage_softirq=0,usage_steal=0,usage_system=0,usage_user=0 1636073508000000000
这一条数据用空格分成了3部分。
第一部分是measurement和tags,上例中第一个逗号之前的部分即cpu,就是measurement,第一个逗号之后的部分cpu=cpu-total,host=172-20-24-219就是tags,host这个标签标识了这个监控数据是从哪里采集的,也就是夜莺里的监控对象,后面Telegraf这个数据进入夜莺服务端之后,夜莺就是从host标签中提取的监控对象标识(夜莺里把监控对象标识叫ident)。cpu=cpu-total这个标签表示这是cpu的整机情况,其他的那些监控数据大家可以看到,有cpu=cpu0,cpu=cpu1等标签,表示不同CPU核的监控数据。
第二部分是fields,filed_key=field_value这种格式,usage_guest=0就是一个field,因为Telegraf是InfluxDB生态的,InfluxDB是列式存储,这种格式非常合适。但是在夜莺、OpenTSDB、Prometheus这种生态里,一般不这么描述监控数据,所以后续是需要有个格式转换的,转换逻辑也很简单,就是${measurement}_${field_key}组成metric,上面这一条数据,会被拆成10个metric。不理解也没关系,后面真正要上报数据的时候,会给大家演示。
第三部分是时间戳:1636073508000000000,这个时间戳应该是纳秒为单位的,上报给不同的后端的时候,要做转换,比如上报给OpenTSDB的时候,OpenTSDB就把时间转换为秒了。
上面的采集的CPU和内存数据,标签部分只有:host=172-20-24-219和cpu=cpu-total这种数据,是稳定的,不需要对标签做额外处理。这个host标签默认是取的机器名,大家可以通过修改telegraf.conf的配置来手工设置别的内容,比如把host标签的值设置为本机ip之类的,配置项在agent那个section:
Tag: 数据稳定,一般用于索引字段
filed:数据不稳定,一般用于监控指标的值。
[agent]
interval = "10s"
round_interval = true
metric_batch_size = 1000
metric_buffer_limit = 10000
collection_jitter = "0s"
flush_interval = "10s"
flush_jitter = "0s"
precision = ""
hostname = ""
omit_hostname = false
上面倒数第二行,默认为空,自动获取本机hostname,可以设置一个不为空的值,就会以你设置 的值为准了。个人建议维持默认,就用hostname挺好的,公司里的每台机器,建议hostname都不要相同,这才是最佳实践。
好了,本篇到此结束,主要对Telegraf做了基本介绍、安装和测试,后面我们就要开始测试这些常用的input插件了,有了此等神器,监控采集这块,估计是不太用担心了,enjoy :-) ———————————————— 版权声明:本文为CSDN博主「wrr-cat」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/wr_java/article/details/124575088