01 ceph-deploy部署
企业中使用存储按照其功能,使用场景,一直在持续发展和迭代,大体上可以分为四个阶段:
DAS:Direct Attached Storage,即直连附加存储,第一代存储系统,通过SCSI总线扩展至一个外部的存储,磁带整列,作为服务器扩展的一部分;
NAS:Network Attached Storage,即网络附加存储,通过网络协议如NFS远程获取后端文件服务器共享的存储空间,将文件存储单独分离出来;
SAN:Storage Area Network,即存储区域网络,分为IP-SAN和FC-SAN,即通过TCP/IP协议和FC(Fiber Channel)光纤协议连接到存储服务器;
Object Storage:即对象存储,随着大数据的发展,越来越多的图片,视频,音频静态文件存储需求,动仄PB以上的存储空间,需无限扩展。
存储的发展,根据不同的阶段诞生了不同的存储解决方案,每一种存储都有它当时的历史诞生的环境以及应用场景,解决的问题和优缺点。
DAS 直连存储服务器使用 SCSI 或 FC 协议连接到存储阵列、通过 SCSI 总线和 FC 光纤协议类型进行数据传输;例如一块有空间大小的裸磁盘:/dev/sdb。DAS存储虽然组网简单、成本低廉但是可扩展性有限、无法多主机实现共享、目前已经很少使用了。
NAS网络存储服务器使用TCP网络协议连接至文件共享存储、常见的有NFS、CIFS协议等;通过网络的方式映射存储中的一个目录到目标主机,如/data。NAS网络存储使用简单,通过IP协议实现互相访问,多台主机可以同时共享同一个存储。但是NAS网络存储的性能有限,可靠性不是很高。
SAN存储区域网络服务器使用一个存储区域网络IP或FC连接到存储阵列、常见的SAN协议类型有IP-SAN和FC-SAN。SAN存储区域网络的性能非常好、可扩展性强;但是成本特别高、尤其是FC存储网络:因为需要用到HBA卡、FC交换机和支持FC接口的存储。
Object Storage对象存储通过网络使用API访问一个无限扩展的分布式存储系统、兼容于S3风格、原生PUT/GET等协议类型。表现形式就是可以无限使用存储空间,通过PUT/GET无限上传和下载。可扩展性极强、使用简单,但是只使用于静态不可编辑文件,无法为服务器提供块级别存储。
综上、企业中不同场景使用的存储,使用表现形式无非是这三种:磁盘(块存储设备),挂载至目录像本地文件一样使用(文件共享存储),通过API向存储系统中上传PUT和下载GET文件(对象存储) 专业的传统设备:EMC,NetAPP,IBM
1、Ceph是一个对象式存储系统,它把每一个待管理的数量流(例如一个文件)切分为一到多个固定大小的对象数据,并以其为原子单元完成数据存取
2、对象数据的底层存储服务是由多个主机(host)组成的存储集群,该集群也被称之为RADOS存储集群,即可靠、自动化分布式对象存储系统
3、librados是RADOS存储集群的API,它支持C、C++、Java、Python,Ruby和PHP等编程语言
RadosGW、RBD和CephFS都是RADOS存储服务的客户端,它们把RADOS的存储服务接口(librados)分别从不同的角度做了进一步抽象,因而各自适用于不同的应用场景
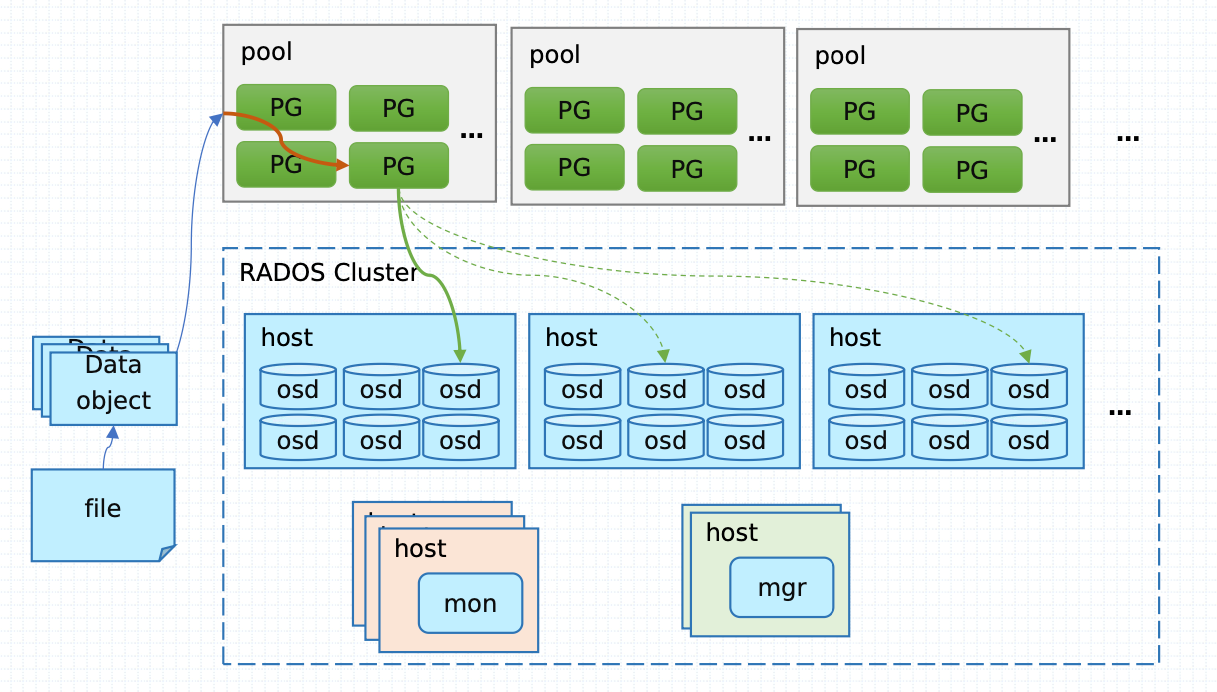
1、mon:监视器,维护整个集群的元数据
2、OSD:也就是负责响应客户端请求返回具体数据的进程,一个Ceph集群一般都有很多个OSD,每个osd代表一个磁盘
3、mds:是CephFS服务依赖的元数据服务
4、Object:Ceph 最底层的存储单元是 Object 对象,每个 Object 包含元数据和原始数据。
5、PG:是一个逻辑的概念,一个 PG 包含多个 OSD。引入 PG 这一层其实是为了更好的分配数据和定位数据。
6、CephFS :是 Ceph 对外提供的文件系统服务。
7、RGW:是 Ceph 对外提供的对象存储服务,接口与 S3 和 Swift 兼容
8、RBD :是 Ceph 对外提供的块设备服务。
9、CRUSH 是 Ceph 使用的数据分布算法,类似一致性哈希,让数据分配到预期的地方
10、RADOS :是 Ceph 集群的精华,用户实现数据分配、Failover 等集群操作
11、Ceph Manager(ceph-mgr),提供集群状态监控和性能监控。
高性能
摒弃了传统的集中式存储元数据寻址的方案,采用 CRUSH 算法,数据分布均衡,并行度高。
考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等。
能够支持上千个存储节点的规模,支持 TB 到 PB 级的数据。
高可用性
- 副本数可以灵活控制。
- 支持故障域分隔,数据强一致性。
- 多种故障场景自动进行修复自愈。
- 没有单点故障,自动管理。
高可扩展性
- 去中心化。
- 扩展灵活。
- 随着节点增加而线性增长
特性丰富
- 支持三种存储接口:块存储、文件存储、对象存储。
- 支持自定义接口,支持多种语言驱动
| Cluster网络 | Public网络 | 主机名称 | 主机角色 | osd磁盘 |
|---|---|---|---|---|
| 10.211.55.68 | 10.37.129.9 | ceph-admin | admin | |
| 10.211.55.69 | 10.37.129.10 | stor01 | mon, osd, mgr, mds | sdb(80G),sdc(120G) |
| 10.211.55.70 | 10.37.129.11 | stor02 | mon, osd, mgr | sdb(80G),sdc(120G) |
| 10.211.55.71 | 10.37.129.12 | stor03 | mon, osd, rgw | sdb(80G),sdc(120G) |
| 10.211.55.72 | 10.37.129.13 | stor04 | osd | sdb(80G),sdc(120G) |
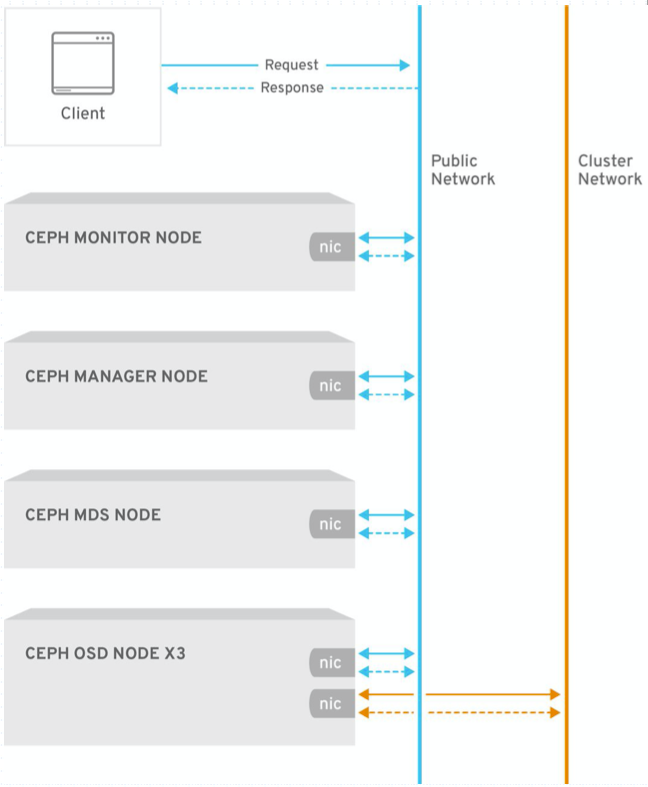
各主机需要预设的系统环境如下: 1、借助于NTP服务设定各节点时间精确同步 2、通过DNS完成各节点的主机名称解析,测试环境主机数量较少时也可以使用hosts文件进行 3、关闭各节点的iptables或firewalld服务,并确保它们被禁止随系统引导过程启动; 4、各节点禁用SElinux
每个主机上操作(ntpd/chrony)
#设置硬件时钟调整为与本地时钟一致
timedatectl set-local-rtc 1
# 设置时区为上海
timedatectl set-timezone Asia/Shanghai
# 安装ntpdate
yum -y install ntpdate
#同步时间
ntpdate -u pool.ntp.org
#查看时间
date
chrony
~]# systemctl start chronyd.service
~]# systemctl enable chronyd.service
不过,建议用户配置使用本地的的时间服务器,在节点数量众多时尤其如此。存在可用的本地时间服务器时,修改节 点的/etc/crhony.conf配置文件,并将时间服务器指向相应的主机即可,配置格式如下:
server CHRONY-SERVER-NAME-OR-IP iburst
# 每台主机上都要配置
[root@ceph-admin ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.211.55.68 ceph-admin
10.211.55.69 stor01
10.211.55.70 stor02
10.211.55.71 stor03
10.211.55.72 stor04
每台主机上都要操作
# 每台主机上都要操作
systemctl disable firewalld
systemctl stop firewalld
部署工具ceph-deploy 必须以普通用户登录到Ceph集群的各目标节点,且此用户需要拥有无密码使用sudo命令的权限,以便在安装软件及生成配置文件的过程中无需中断配置过程。不过,较新版的ceph-deploy也支持用 ”– username“ 选项提供可无密码使用sudo命令的用户名(包括 root ,但不建议这样做)。
另外,使用”ceph-deploy –username {username} “命令时,指定的用户需要能够通过SSH协议自动认证并连接到各 Ceph节点,以免ceph-deploy命令在配置中途需要用户输入密码。
首先需要在各节点以管理员的身份创建一个专用于ceph-deploy的特定用户账号,例如cephadm(建议不要使用
ceph),并为其设置认证密码:
[root@ceph-admin ~]# useradd cephadm && echo ljzsdut | passwd --stdin cephadm
# 在每台机器上都要做
[cephadm@ceph-admin ~]# echo "cephadm ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/cephadm
[cephadm@ceph-admin ~]# chmod 0440 /etc/sudoers.d/cephadm
[root@ceph-admin ~]# su - cephadm
[cephadm@ceph-admin ~]$ ssh-keygen -t rsa -P ''
[cephadm@ceph-admin ~]$ ssh-copy-id -i .ssh/id_rsa.pub cephadm@localhost
# 拷贝密钥到其他机器上
[cephadm@ceph-admin ~]$ scp -rp .ssh/ cephadm@stor01:/home/cephadm/
[cephadm@ceph-admin ~]$ scp -rp .ssh/ cephadm@stor02:/home/cephadm/
[cephadm@ceph-admin ~]$ scp -rp .ssh/ cephadm@stor03:/home/cephadm/
[cephadm@ceph-admin ~]$ scp -rp .ssh/ cephadm@stor04:/home/cephadm/
验证免密钥是否成功
# 所有机器上每台都要操作
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
cat >/etc/yum.repos.d/ceph.repo<<EOF
[noarch]
name=Ceph noarch
baseurl=https://mirrors.aliyun.com/ceph/rpm-nautilus/el7/noarch/
enabled=1
gpgcheck=0
[x86_64]
name=Ceph x86_64
baseurl=https://mirrors.aliyun.com/ceph/rpm-nautilus/el7/x86_64/
enabled=1
gpgcheck=0
EOF
# /proc/sys/kernel/pid_max 参数配置方法如下:
echo 'kernel.pid_max = 4194303' >> /etc/sysctl.conf
# /proc/sys/fs/file-max 参数配置方法如下:
echo 'fs.file-max = 26234859' >> /etc/sysctl.conf
echo '* soft nofile 65536' >> /etc/security/limits.conf
echo '* hard nofile 65536' >> /etc/security/limits.conf
[root@ceph-admin cephadm]# yum -y install python-setuptools ceph-deploy ceph-common
1、首先在管理节点上以cephadm用户创建集群相关的配置文件目录:
[root@ceph-admin cephadm]# su cephadm
[cephadm@ceph-admin ~]$ mkdir ceph-cluster
[cephadm@ceph-admin ~]$ cd ceph-cluster/
2、初始化MON节点,命令格式为”ceph-deploy new {initial-monitor-node(s)}“,本示例中,stor01即为第一个MON节点名称,其名称必须与节点当前实际使用的主机名称保存一致。运行如下命令即可生成初始配置:
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy new --public-network 10.37.129.0/24 --cluster-network 10.211.55.0/24 stor01 stor02 stor03 #monitor至少指定一个,后期可以再对其添加
以上初始化命令并未真正部署任何应用,只是生成了一个ceph.conf配置文件和ceph.mon.keyring文件。如果ceph的配置有满足要求的地方,可以手动修改此文件。
[cephadm@stor01 ceph-cluster]$ ls
ceph.conf ceph-deploy-ceph.log ceph.mon.keyring
[cephadm@stor01 ceph-cluster]$ cat ceph.conf
[global]
fsid = 6af58884-134c-48e0-bd62-f37f302c8108
public_network = 10.37.129.0/24
cluster_network = 10.211.55.0/24
mon_initial_members = stor01, stor02, stor03
mon_host = 10.37.129.10,10.37.129.11,10.37.129.12 #public network,因为mon节点只需要public网络。而osd节点需要public和cluster这2个网络
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
3、安装ceph相关软件包
ceph-deploy命令能够以远程的方式连入Ceph集群各节点完成程序包安装等操作,默认(–all)会安装mon、osd、mds、rgw这些组件的相关包,当然也可以指定只安装某个组件的相关包,例如--mon、--mgr、--mds、--rgw、--osd、--common|--cli。
命令格式如下:
ceph-deploy install {ceph-node} [{ceph-node} ...]
因此,若要将所有节点配置为Ceph集群节点,则执行如下命令即可:
# ceph-deploy命令默认会调整服务器上的yum源,使用默认的官方源进行相关软件的安装,速度比较慢,添加--no-adjust-repos参数可以ceph-deploy不去调整yum源,而使用我们实现配置好的yum源
ceph-deploy install --no-adjust-repos stor01 stor02 stor03 stor04
#我么也可以在所有节点进行手动安装
#yum -y install ceph ceph-radosgw #最终通过依赖会安装ceph ceph-mon ceph-mgr ceph-radosgw ceph-mds
1、 安装MON节点,并收集所有密钥keyring(此步骤才是真正地初始化monitor节点)
子命令create和create-initial的区别
create:需要手动指定mon节点列表
create-initial:无需指定mon节点列表,会去读取ceph.conf文件中的mon_initial_members配置。
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy mon create-initial
以上命令主要完成如下操作:
- 部署并启动ceph-mon进程(根据配置文件指定的节点上)
- 在ceph-mon节点上生成集群配置文件:/etc/ceph/{cluster}.conf ({cluster}为集群名称,默认为ceph)
[root@stor01 ~]# ll /etc/ceph/
total 8
-rw-r--r--. 1 root root 303 Oct 7 09:30 ceph.conf
-rw-r--r--. 1 root root 92 Jun 30 06:36 rbdmap #该文件是在ceph-deploy install安装软件时生成
-rw-------. 1 root root 0 Oct 7 09:30 tmpqoMVti
- 收集并在部署目录下生成一系列的keyring文件
[cephadm@ceph-admin ceph-cluster]$ ll
total 320
-rw-rw-r--. 1 cephadm cephadm 296700 Oct 7 09:30 ceph-deploy-ceph.log
-rw-------. 1 cephadm cephadm 113 Oct 7 09:30 ceph.bootstrap-mds.keyring #引导启动秘钥
-rw-------. 1 cephadm cephadm 113 Oct 7 09:30 ceph.bootstrap-mgr.keyring
-rw-------. 1 cephadm cephadm 113 Oct 7 09:30 ceph.bootstrap-osd.keyring
-rw-------. 1 cephadm cephadm 113 Oct 7 09:30 ceph.bootstrap-rgw.keyring
-rw-------. 1 cephadm cephadm 151 Oct 7 09:30 ceph.client.admin.keyring #客户端管理员秘钥,具有管理整个集群是所有权限
-rw-rw-r--. 1 cephadm cephadm 303 Oct 7 09:16 ceph.conf #ceph配置文件
-rw-------. 1 cephadm cephadm 73 Oct 7 09:16 ceph.mon.keyring
2、 【可选】把配置文件(ceph.conf)和admin密钥(ceph.client.admin.keyring)拷贝Ceph集群各节点,以免得每次执行”ceph“命令行时不得不明确指定MON节点地址和密钥文件:
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy admin ceph-admin stor01 stor02 stor03 stor04
以上命令会将ceph.conf和ceph.client.admin.keyring文件拷贝成/etc/ceph/目录下。
如果想只拷贝主配置文件ceph.conf,可以使用ceph-deploy config HOST... 命令。如果各个节点上已经存在ceph.conf文件了,可以使用--overwrite-conf参数进行文件覆盖。
3、而后在Ceph集群中需要运行ceph命令的的节点上(或所有节点上)以root用户的身份设定用户cephadm能够读取/etc/ceph/ceph.client.admin.keyring文件(该文件默认属主为root,权限为600)
#每个节点上都要操作
setfacl -m u:cephadm:r /etc/ceph/ceph.client.admin.keyring
在L版本及以后版本,要求至少部署一个mgr进程。否则集群状态会提示mgr: no daemons active
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy mgr create stor01 stor02 #会自动启动ceph-mgr进程
[root@stor01 ~]# ps -ef |grep ceph-mgr
ceph 14626 1 6 09:48 ? 00:00:01 /usr/bin/ceph-mgr -f --cluster ceph --id stor01 --setuser ceph --setgroup ceph
root 14750 8515 0 09:49 pts/0 00:00:00 grep --color=auto ceph-mgr
查看测试集群的健康状态
[cephadm@ceph-admin ceph-cluster]$ ceph -s
cluster:
id: 6af58884-134c-48e0-bd62-f37f302c8108
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
mons are allowing insecure global_id reclaim
services:
mon: 3 daemons, quorum stor01,stor02,stor03 (age 19m)
mgr: stor01(active, since 73s), standbys: stor02
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
ceph命令默认使用client.admin这个用户去连接rados集群。可以使用ceph –user USER 指定其他用户。
ceph命令默认参数:
- –user client.admin
- -c /etc/ceph/ceph.conf
- -k /etc/ceph/${cluster}.${user}.keyring


1、“ceph-deploy disk”命令可以检查并列出OSD节点上所有可用的磁盘的相关信息
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy disk list stor01 stor02 stor03 stor04
2、擦除计划专用于OSD磁盘上的所有分区表和数据以便用于OSD
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy disk zap stor01 /dev/sdb /dev/sdc
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy disk zap stor02 /dev/sdb /dev/sdc
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy disk zap stor03 /dev/sdb /dev/sdc
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy disk zap stor04 /dev/sdb /dev/sdc
上述命令主要执行了如下步骤:
sudo /usr/sbin/ceph-volume lvm zap /dev/sdb
/bin/dd if=/dev/zero of=/dev/sdb bs=1M count=10 conv=fsync
提示:若设备上此前有数据,则可能需要在相应节点上以root用户使用“ceph-volume lvm zap –destroy {DEVICE}”命令进行
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy osd create stor01 --data /dev/sdb
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy osd create stor01 --data /dev/sdc
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy osd create stor02 --data /dev/sdb
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy osd create stor02 --data /dev/sdc
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy osd create stor03 --data /dev/sdb
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy osd create stor03 --data /dev/sdc
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy osd create stor04 --data /dev/sdb
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy osd create stor04 --data /dev/sdc
以上命令中,默认采用的是bluestore格式的对象存储。
–data 指定数据盘
–block-db 指定bluestore使用的db盘(高速盘,一般为普通的ssd盘)。默认为data盘
–block-wal 指定bluestore使用的日志盘(超高速,一般为NVMe SSD盘)。默认为db盘
每个osd会启动一个ceph-osd进程。
以上命令的输出示例:
[2021-10-07 10:01:38,794][ceph_deploy.conf][DEBUG ] found configuration file at: /home/cephadm/.cephdeploy.conf
[2021-10-07 10:01:38,794][ceph_deploy.cli][INFO ] Invoked (2.0.1): /usr/bin/ceph-deploy disk zap stor01 /dev/sdb /dev/sdc
[2021-10-07 10:01:38,794][ceph_deploy.cli][INFO ] ceph-deploy options:
[2021-10-07 10:01:38,794][ceph_deploy.cli][INFO ] username : None
[2021-10-07 10:01:38,795][ceph_deploy.cli][INFO ] verbose : False
[2021-10-07 10:01:38,795][ceph_deploy.cli][INFO ] debug : False
[2021-10-07 10:01:38,795][ceph_deploy.cli][INFO ] overwrite_conf : False
[2021-10-07 10:01:38,795][ceph_deploy.cli][INFO ] subcommand : zap
[2021-10-07 10:01:38,795][ceph_deploy.cli][INFO ] quiet : False
[2021-10-07 10:01:38,795][ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x7f0d9e790170>
[2021-10-07 10:01:38,795][ceph_deploy.cli][INFO ] cluster : ceph
[2021-10-07 10:01:38,795][ceph_deploy.cli][INFO ] host : stor01
[2021-10-07 10:01:38,795][ceph_deploy.cli][INFO ] func : <function disk at 0x7f0d9e7d38c0>
[2021-10-07 10:01:38,795][ceph_deploy.cli][INFO ] ceph_conf : None
[2021-10-07 10:01:38,795][ceph_deploy.cli][INFO ] default_release : False
[2021-10-07 10:01:38,795][ceph_deploy.cli][INFO ] disk : ['/dev/sdb', '/dev/sdc']
[2021-10-07 10:01:38,795][ceph_deploy.osd][DEBUG ] zapping /dev/sdb on stor01
[2021-10-07 10:01:39,114][stor01][DEBUG ] connection detected need for sudo
[2021-10-07 10:01:39,424][stor01][DEBUG ] connected to host: stor01
[2021-10-07 10:01:39,424][stor01][DEBUG ] detect platform information from remote host
[2021-10-07 10:01:39,441][stor01][DEBUG ] detect machine type
[2021-10-07 10:01:39,447][stor01][DEBUG ] find the location of an executable
[2021-10-07 10:01:39,449][ceph_deploy.osd][INFO ] Distro info: CentOS Linux 7.8.2003 Core
[2021-10-07 10:01:39,449][stor01][DEBUG ] zeroing last few blocks of device
[2021-10-07 10:01:39,450][stor01][DEBUG ] find the location of an executable
[2021-10-07 10:01:39,453][stor01][INFO ] Running command: sudo /usr/sbin/ceph-volume lvm zap /dev/sdb
[2021-10-07 10:01:39,729][stor01][WARNING] --> Zapping: /dev/sdb
[2021-10-07 10:01:39,729][stor01][WARNING] --> --destroy was not specified, but zapping a whole device will remove the partition table
[2021-10-07 10:01:39,729][stor01][WARNING] Running command: /bin/dd if=/dev/zero of=/dev/sdb bs=1M count=10 conv=fsync
[2021-10-07 10:01:39,729][stor01][WARNING] stderr: 10+0 records in
[2021-10-07 10:01:39,729][stor01][WARNING] 10+0 records out
[2021-10-07 10:01:39,729][stor01][WARNING] 10485760 bytes (10 MB) copied
[2021-10-07 10:01:39,729][stor01][WARNING] stderr: , 0.0100531 s, 1.0 GB/s
[2021-10-07 10:01:39,729][stor01][WARNING] --> Zapping successful for: <Raw Device: /dev/sdb>
[2021-10-07 10:06:13,085][ceph_deploy.conf][DEBUG ] found configuration file at: /home/cephadm/.cephdeploy.conf
[2021-10-07 10:06:13,086][ceph_deploy.cli][INFO ] Invoked (2.0.1): /usr/bin/ceph-deploy osd create stor01 --data /dev/sdb
[2021-10-07 10:06:13,086][ceph_deploy.cli][INFO ] ceph-deploy options:
[2021-10-07 10:06:13,086][ceph_deploy.cli][INFO ] verbose : False
[2021-10-07 10:06:13,086][ceph_deploy.cli][INFO ] bluestore : None
[2021-10-07 10:06:13,086][ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x7fbfd9efb2d8>
[2021-10-07 10:06:13,086][ceph_deploy.cli][INFO ] cluster : ceph
[2021-10-07 10:06:13,086][ceph_deploy.cli][INFO ] fs_type : xfs
[2021-10-07 10:06:13,086][ceph_deploy.cli][INFO ] block_wal : None
[2021-10-07 10:06:13,086][ceph_deploy.cli][INFO ] default_release : False
[2021-10-07 10:06:13,086][ceph_deploy.cli][INFO ] username : None
[2021-10-07 10:06:13,086][ceph_deploy.cli][INFO ] journal : None
[2021-10-07 10:06:13,086][ceph_deploy.cli][INFO ] subcommand : create
[2021-10-07 10:06:13,086][ceph_deploy.cli][INFO ] host : stor01
[2021-10-07 10:06:13,086][ceph_deploy.cli][INFO ] filestore : None
[2021-10-07 10:06:13,086][ceph_deploy.cli][INFO ] func : <function osd at 0x7fbfd9f39848>
[2021-10-07 10:06:13,086][ceph_deploy.cli][INFO ] ceph_conf : None
[2021-10-07 10:06:13,086][ceph_deploy.cli][INFO ] zap_disk : False
[2021-10-07 10:06:13,086][ceph_deploy.cli][INFO ] data : /dev/sdb
[2021-10-07 10:06:13,087][ceph_deploy.cli][INFO ] block_db : None
[2021-10-07 10:06:13,087][ceph_deploy.cli][INFO ] dmcrypt : False
[2021-10-07 10:06:13,087][ceph_deploy.cli][INFO ] overwrite_conf : False
[2021-10-07 10:06:13,087][ceph_deploy.cli][INFO ] dmcrypt_key_dir : /etc/ceph/dmcrypt-keys
[2021-10-07 10:06:13,087][ceph_deploy.cli][INFO ] quiet : False
[2021-10-07 10:06:13,087][ceph_deploy.cli][INFO ] debug : False
[2021-10-07 10:06:13,087][ceph_deploy.osd][DEBUG ] Creating OSD on cluster ceph with data device /dev/sdb
[2021-10-07 10:06:13,389][stor01][DEBUG ] connection detected need for sudo
[2021-10-07 10:06:13,695][stor01][DEBUG ] connected to host: stor01
[2021-10-07 10:06:13,696][stor01][DEBUG ] detect platform information from remote host
[2021-10-07 10:06:13,716][stor01][DEBUG ] detect machine type
[2021-10-07 10:06:13,723][stor01][DEBUG ] find the location of an executable
[2021-10-07 10:06:13,724][ceph_deploy.osd][INFO ] Distro info: CentOS Linux 7.8.2003 Core
[2021-10-07 10:06:13,724][ceph_deploy.osd][DEBUG ] Deploying osd to stor01
[2021-10-07 10:06:13,725][stor01][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
[2021-10-07 10:06:13,729][stor01][WARNING] osd keyring does not exist yet, creating one
[2021-10-07 10:06:13,729][stor01][DEBUG ] create a keyring file
[2021-10-07 10:06:13,733][stor01][DEBUG ] find the location of an executable
[2021-10-07 10:06:13,737][stor01][INFO ] Running command: sudo /usr/sbin/ceph-volume --cluster ceph lvm create --bluestore --data /dev/sdb
[2021-10-07 10:06:13,963][stor01][WARNING] Running command: /bin/ceph-authtool --gen-print-key
[2021-10-07 10:06:13,997][stor01][WARNING] Running command: /bin/ceph --cluster ceph --name client.bootstrap-osd --keyring /var/lib/ceph/bootstrap-osd/ceph.keyring -i - osd new 8c480a79-195f-4924-8b9f-08416d335b4b
[2021-10-07 10:06:14,419][stor01][WARNING] Running command: /sbin/vgcreate --force --yes ceph-f4363e21-2f39-481d-88f4-2ea6ad6bae61 /dev/sdb
[2021-10-07 10:06:14,419][stor01][WARNING] stdout: Physical volume "/dev/sdb" successfully created.
[2021-10-07 10:06:14,419][stor01][WARNING] stdout: Volume group "ceph-f4363e21-2f39-481d-88f4-2ea6ad6bae61" successfully created
[2021-10-07 10:06:14,419][stor01][WARNING] Running command: /sbin/lvcreate --yes -l 20479 -n osd-block-8c480a79-195f-4924-8b9f-08416d335b4b ceph-f4363e21-2f39-481d-88f4-2ea6ad6bae61
[2021-10-07 10:06:14,485][stor01][WARNING] stdout: Logical volume "osd-block-8c480a79-195f-4924-8b9f-08416d335b4b" created.
[2021-10-07 10:06:14,601][stor01][WARNING] Running command: /bin/ceph-authtool --gen-print-key
[2021-10-07 10:06:14,601][stor01][WARNING] Running command: /bin/mount -t tmpfs tmpfs /var/lib/ceph/osd/ceph-0
[2021-10-07 10:06:14,601][stor01][WARNING] Running command: /sbin/restorecon /var/lib/ceph/osd/ceph-0
[2021-10-07 10:06:14,610][stor01][WARNING] Running command: /bin/chown -h ceph:ceph /dev/ceph-f4363e21-2f39-481d-88f4-2ea6ad6bae61/osd-block-8c480a79-195f-4924-8b9f-08416d335b4b
[2021-10-07 10:06:14,610][stor01][WARNING] Running command: /bin/chown -R ceph:ceph /dev/dm-0
[2021-10-07 10:06:14,619][stor01][WARNING] Running command: /bin/ln -s /dev/ceph-f4363e21-2f39-481d-88f4-2ea6ad6bae61/osd-block-8c480a79-195f-4924-8b9f-08416d335b4b /var/lib/ceph/osd/ceph-0/block
[2021-10-07 10:06:14,619][stor01][WARNING] Running command: /bin/ceph --cluster ceph --name client.bootstrap-osd --keyring /var/lib/ceph/bootstrap-osd/ceph.keyring mon getmap -o /var/lib/ceph/osd/ceph-0/activate.monmap
[2021-10-07 10:06:14,735][stor01][WARNING] stderr: 2021-10-07 10:06:14.689 7f36d730c700 -1 auth: unable to find a keyring on /etc/ceph/ceph.client.bootstrap-osd.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin,: (2) No such file or directory
[2021-10-07 10:06:14,735][stor01][WARNING] 2021-10-07 10:06:14.689 7f36d730c700 -1 AuthRegistry(0x7f36d00662f8) no keyring found at /etc/ceph/ceph.client.bootstrap-osd.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin,, disabling cephx
[2021-10-07 10:06:14,954][stor01][WARNING] stderr: got monmap epoch 1
[2021-10-07 10:06:14,957][stor01][WARNING] Running command: /bin/ceph-authtool /var/lib/ceph/osd/ceph-0/keyring --create-keyring --name osd.0 --add-key AQAVVl5h/JShOhAATWjlUZw1ikhB+CleLH64Lw==
[2021-10-07 10:06:15,025][stor01][WARNING] stdout: creating /var/lib/ceph/osd/ceph-0/keyring
[2021-10-07 10:06:15,025][stor01][WARNING] stdout: added entity osd.0 auth(key=AQAVVl5h/JShOhAATWjlUZw1ikhB+CleLH64Lw==)
[2021-10-07 10:06:15,025][stor01][WARNING] Running command: /bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-0/keyring
[2021-10-07 10:06:15,025][stor01][WARNING] Running command: /bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-0/
[2021-10-07 10:06:15,025][stor01][WARNING] Running command: /bin/ceph-osd --cluster ceph --osd-objectstore bluestore --mkfs -i 0 --monmap /var/lib/ceph/osd/ceph-0/activate.monmap --keyfile - --osd-data /var/lib/ceph/osd/ceph-0/ --osd-uuid 8c480a79-195f-4924-8b9f-08416d335b4b --setuser ceph --setgroup ceph
[2021-10-07 10:06:17,177][stor01][WARNING] stderr: 2021-10-07 10:06:15.079 7f41a413fa80 -1 bluestore(/var/lib/ceph/osd/ceph-0/) _read_fsid unparsable uuid
[2021-10-07 10:06:17,177][stor01][WARNING] --> ceph-volume lvm prepare successful for: /dev/sdb
[2021-10-07 10:06:17,177][stor01][WARNING] Running command: /bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-0
[2021-10-07 10:06:17,177][stor01][WARNING] Running command: /bin/ceph-bluestore-tool --cluster=ceph prime-osd-dir --dev /dev/ceph-f4363e21-2f39-481d-88f4-2ea6ad6bae61/osd-block-8c480a79-195f-4924-8b9f-08416d335b4b --path /var/lib/ceph/osd/ceph-0 --no-mon-config
[2021-10-07 10:06:17,209][stor01][WARNING] Running command: /bin/ln -snf /dev/ceph-f4363e21-2f39-481d-88f4-2ea6ad6bae61/osd-block-8c480a79-195f-4924-8b9f-08416d335b4b /var/lib/ceph/osd/ceph-0/block
[2021-10-07 10:06:17,210][stor01][WARNING] Running command: /bin/chown -h ceph:ceph /var/lib/ceph/osd/ceph-0/block
[2021-10-07 10:06:17,213][stor01][WARNING] Running command: /bin/chown -R ceph:ceph /dev/dm-0
[2021-10-07 10:06:17,217][stor01][WARNING] Running command: /bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-0
[2021-10-07 10:06:17,221][stor01][WARNING] Running command: /bin/systemctl enable ceph-volume@lvm-0-8c480a79-195f-4924-8b9f-08416d335b4b
[2021-10-07 10:06:17,229][stor01][WARNING] stderr: Created symlink from /etc/systemd/system/multi-user.target.wants/ceph-volume@lvm-0-8c480a79-195f-4924-8b9f-08416d335b4b.service to /usr/lib/systemd/system/ceph-volume@.service.
[2021-10-07 10:06:17,348][stor01][WARNING] Running command: /bin/systemctl enable --runtime ceph-osd@0
[2021-10-07 10:06:17,349][stor01][WARNING] stderr: Created symlink from /run/systemd/system/ceph-osd.target.wants/ceph-osd@0.service to /usr/lib/systemd/system/ceph-osd@.service.
[2021-10-07 10:06:17,387][stor01][WARNING] Running command: /bin/systemctl start ceph-osd@0
[2021-10-07 10:06:17,421][stor01][WARNING] --> ceph-volume lvm activate successful for osd ID: 0
[2021-10-07 10:06:17,421][stor01][WARNING] --> ceph-volume lvm create successful for: /dev/sdb
[2021-10-07 10:06:22,436][stor01][INFO ] checking OSD status...
[2021-10-07 10:06:22,436][stor01][DEBUG ] find the location of an executable
[2021-10-07 10:06:22,441][stor01][INFO ] Running command: sudo /bin/ceph --cluster=ceph osd stat --format=json
[2021-10-07 10:06:22,812][ceph_deploy.osd][DEBUG ] Host stor01 is now ready for osd use.
[cephadm@ceph-admin ceph-cluster]$ ceph -s
cluster:
id: 6af58884-134c-48e0-bd62-f37f302c8108
health: HEALTH_WARN
mons are allowing insecure global_id reclaim
services:
mon: 3 daemons, quorum stor01,stor02,stor03 (age 38m)
mgr: stor01(active, since 20m), standbys: stor02
osd: 8 osds: 8 up (since 43s), 8 in (since 43s)
task status:
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 8.0 GiB used, 792 GiB / 800 GiB avail
pgs:
[cephadm@ceph-admin ceph-cluster]$ ceph osd stat
8 osds: 8 up (since 56s), 8 in (since 56s); epoch: e33
[cephadm@ceph-admin ceph-cluster]$ ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.78113 root default
-3 0.19528 host stor01
0 ssd 0.07809 osd.0 up 1.00000 1.00000
1 ssd 0.11719 osd.1 up 1.00000 1.00000
-5 0.19528 host stor02
2 ssd 0.07809 osd.2 up 1.00000 1.00000
3 ssd 0.11719 osd.3 up 1.00000 1.00000
-7 0.19528 host stor03
4 ssd 0.07809 osd.4 up 1.00000 1.00000
5 ssd 0.11719 osd.5 up 1.00000 1.00000
-9 0.19528 host stor04
6 ssd 0.07809 osd.6 up 1.00000 1.00000
7 ssd 0.11719 osd.7 up 1.00000 1.00000
#例子:osd要设置开机自启动,以防服务器down机后osd挂掉,其他osd同上(ceph-osd@$ID)
[cephadm@ceph-admin ~]$ sudo systemctl enable ceph-osd@0.service
# 查看日志
[cephadm@ceph-admin ceph-cluster]$ ceph osd dump
Ceph集群中的一个OSD通常对应于一个设备,且运行于专用的守护进程。在某OSD设备出现故障,或管理员出于管理之需确实要移除特定的OSD设备时,需要先停止相关的守护进程,而后再进行移除操作。
对于Luminous及其之后 的版本来说,停止和移除命令的格式分别如下所示:
- 停用设备:
ceph osd out {osd-num} - 停止进程:
sudo systemctl stop ceph-osd@{osd-num} - 移除设备:
ceph osd purge {id} --yes-i-really-mean-it
若类似如下的OSD的配置信息存在于ceph.conf配置文件中,管理员在删除OSD之后手动将其删除。
[osd.1]
host = {hostname}
不过,对于Luminous之前的版本来说,管理员需要依次手动执行如下步骤删除OSD设备:
- 于CRUSH运行图中移除设备:
ceph osd crush remove {name} - 移除OSD的认证key:
ceph auth del osd.{osd-num} - 最后移除OSD设备:
ceph osd rm {osd-num}
存取数据时,客户端必须首先连接至RADOS集群上某存储池,而后根据对象名称由相关的CRUSH规则完成数据对象寻址。于是,为了测试集群的数据存取功能,这里首先创建一个用于测试的存储池mypool,并设定其PG数量为32个。
#创建名为mypool的存储池
[cephadm@stor01 ceph-cluster]$ ceph osd pool create mypool 32 32
pool 'mypool' created
[cephadm@stor01 ceph-cluster]$ ceph osd pool ls #ceph osd lspools
mypool
而后即可将测试文件上传至存储池中,例如下面的“rados put”命令将/etc/issue文件上传至mypool存储池,对象名 称依然保留为文件名issue,而“rados ls”命令则可以列出指定存储池中的数据对象。
# rados put <obj-name> <infile>
[cephadm@stor01 ceph-cluster]$ rados put ceph.conf /home/cephadm/ceph-cluster/ceph.conf -p mypool
[cephadm@stor01 ceph-cluster]$ rados ls -p mypool
ceph.conf
而“ceph osd map”命令可以获取到存储池中数据对象的具体位置信息:
# ceph osd map <poolname> <objectname> {<nspace>}
[cephadm@ceph-admin ceph-cluster]$ ceph osd map mypool ceph.conf
osdmap e40 pool 'mypool' (1) object 'ceph.conf' -> pg 1.d52b66c4 (1.4) -> up ([3,2,6], p3) acting ([3,2,6], p3)
# rados get <obj-name> <outfile>
[cephadm@stor01 ceph-cluster]$ rados get ceph.conf /tmp/ljz.conf -p mypool
# rados rm <obj-name> ...[--force-full]
rados rm ceph.conf -p mypool
删除存储池命令存在数据丢失的风险,Ceph于是默认禁止此类操作。管理员需要在ceph.conf配置文件中启用支持删除存储池的操作后,方可使用类似如下命令删除存储池。
ceph osd pool rm mypool mypool --yes-i-really-really-mean-it
Ceph存储集群需要至少运行一个Ceph Monitor和一个Ceph Manager,生产环境中,为了实现高可用性,Ceph存储集群通常运行多个监视器,以免单监视器整个存储集群崩溃。Ceph使用Paxos算法,该算法需要半数以上的监视器(大于n/2,其中n为总监视器数量)才能形成法定人数。尽管此非必需,但奇数个监视器往往更好
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy mon add stor02
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy mon add stor03
[cephadm@ceph-admin ceph-cluster]$ ceph quorum_status --format json-pretty
{
"election_epoch": 4,
"quorum": [
0,
1,
2
],
"quorum_names": [
"stor01",
"stor02",
"stor03"
],
"quorum_leader_name": "stor01",
"quorum_age": 3386,
"monmap": {
"epoch": 1,
"fsid": "6af58884-134c-48e0-bd62-f37f302c8108",
"modified": "2021-10-07 09:30:13.913895",
"created": "2021-10-07 09:30:13.913895",
"min_mon_release": 14,
"min_mon_release_name": "nautilus",
"features": {
"persistent": [
"kraken",
"luminous",
"mimic",
"osdmap-prune",
"nautilus"
],
"optional": []
},
"mons": [
{
"rank": 0,
"name": "stor01",
"public_addrs": {
"addrvec": [
{
"type": "v2",
"addr": "10.37.129.10:3300",
"nonce": 0
},
{
"type": "v1",
"addr": "10.37.129.10:6789",
"nonce": 0
}
]
},
"addr": "10.37.129.10:6789/0",
"public_addr": "10.37.129.10:6789/0"
},
{
"rank": 1,
"name": "stor02",
"public_addrs": {
"addrvec": [
{
"type": "v2",
"addr": "10.37.129.11:3300",
"nonce": 0
},
{
"type": "v1",
"addr": "10.37.129.11:6789",
"nonce": 0
}
]
},
"addr": "10.37.129.11:6789/0",
"public_addr": "10.37.129.11:6789/0"
},
{
"rank": 2,
"name": "stor03",
"public_addrs": {
"addrvec": [
{
"type": "v2",
"addr": "10.37.129.12:3300",
"nonce": 0
},
{
"type": "v1",
"addr": "10.37.129.12:6789",
"nonce": 0
}
]
},
"addr": "10.37.129.12:6789/0",
"public_addr": "10.37.129.12:6789/0"
}
]
}
}
Ceph Manager守护进程以“Active/Standby”模式运行,部署其它ceph-mgr守护程序可确保在Active节点上的 ceph-mgr守护进程故障时,其中的一个Standby实例可以在不中断服务的情况下接管其任务。
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy mgr create stor02
三种接口按需启用。
Ceph块设备,也称为RADOS块设备(简称RBD),是一种基于RADOS存储系统支持超配(thin-provisioned)、可 伸缩的条带化数据存储系统,它通过librbd库与OSD进行交互。RBD为KVM等虚拟化技术和云OS(如OpenStack和 CloudStack)提供高性能和无限可扩展性的存储后端,这些系统依赖于libvirt和QEMU实用程序与RBD进行集成。
客户端基于librbd库即可将RADOS存储集群用作块设备,不过,用于rbd的存储池需要事先启用rbd功能并进行初始化。
例如,下面的命令创建一个名为rbddata的存储池,在启用rbd功能后对其进行初始化:
[cephadm@ceph-admin ~]$ ceph osd pool create rbddata 64
pool 'rbddata' created
#存储池默认情况下是一个裸池,没有任何特定格式。对于rbd、rgw、cephfs三种应用程序,需要分别启用其相关存储池的应用功能。比如要将rbddata这个pool作为一个rbd的存储池使用,则需要做如下操作:
[cephadm@ceph-admin ~]$ ceph osd pool application enable rbddata rbd #启用rbd功能
enabled application 'rbd' on pool 'rbddata'
[cephadm@ceph-admin ~]$ rbd pool init -p rbddata # 第2种方式:只针对rbd池进行rbd池初始化
不过,rbd存储池并不能直接用于块设备,而是需要事先在其中按需创建映像(image),并把映像文件作为块设备 使用。rbd命令可用于创建、查看及删除块设备相在的映像(image),以及克隆映像、创建快照、将映像回滚到快 照和查看快照等管理操作。例如,下面的命令能够创建一个名为img1的映像:
[cephadm@ceph-admin ~]$ rbd create img1 --size 1024 --pool rbddata
[cephadm@ceph-admin ~]$ rbd ls -p rbddata
img1
映像的相关的信息则可以使用“rbd info”命令获取:
[cephadm@ceph-admin ~]$ rbd --image img1 --pool rbddata info
rbd image 'img1':
size 1 GiB in 256 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 11ac316f3178
block_name_prefix: rbd_data.11ac316f3178
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
op_features:
flags:
create_timestamp: Thu Oct 7 10:36:22 2021
access_timestamp: Thu Oct 7 10:36:22 2021
modify_timestamp: Thu Oct 7 10:36:22 2021
在客户端主机上,用户通过内核级的rbd驱动识别相关的设备,即可对其进行分区、创建文件系统并挂载使用。
RGW并非必须的接口,仅在需要用到与S3和Swift兼容的RESTful接口时才需要部署RGW实例,相关的命令为“ceph- deploy rgw create {gateway-node}”。例如,下面的命令用于把stor03部署为rgw主机:
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy rgw create stor03 #监听7480端口
[root@stor03 ~]# ps -ef |grep radosgw
ceph 15629 1 0 10:49 ? 00:00:00 /usr/bin/radosgw -f --cluster ceph --name client.rgw.stor03 --setuser ceph --setgroup ceph
[root@stor03 ~]# ss -tnlp |grep 7480
LISTEN 0 128 *:7480 *:* users:(("radosgw",pid=15629,fd=52))
LISTEN 0 128 [::]:7480 [::]:* users:(("radosgw",pid=15629,fd=53))
默认情况下,RGW实例监听于TCP协议的7480端口,需要更换时,可以通过在运行RGW的节点上编辑其主配置文件ceph.conf进行修改,相关参数如下所示:
[client]
rgw_frontends = "civetweb port=8080"
而后需要重启相关的服务,命令格式为“systemctl restart ceph-radosgw@rgw.{node-name}”,例如重启stor03上 的RGW,可以以root用户运行如下命令:
~]# systemctl status ceph-radosgw@rgw.stor03
RGW会在rados集群上生成包括如下存储池的一系列存储池:
[cephadm@ceph-admin ~]$ ceph osd pool ls
.rgw.root
default.rgw.control
default.rgw.meta
default.rgw.log
RGW提供的是REST接口,客户端通过http与其进行交互,完成数据的增删改查等管理操作。
CephFS需要至少运行一个元数据服务器(MDS)守护进程(ceph-mds),此进程管理与CephFS上存储的文件相关的元数据,并协调对Ceph存储集群的访问。需要注意的是元数据服务器(MDS)自己本身并不存储元数据,它只提供元数据服务和缓存服务,真正的元数据存储在cephfs的metadata池中,而数据会保存在data池中。因此,若要使用CephFS接口,需要在存储集群中至少部署一个MDS实 例。“ceph-deploy mds create {ceph-node}”命令可以完成此功能,例如,在stor01上启用MDS:
[cephadm@ceph-admin ceph-cluster]$ ceph-deploy mds create stor01
[root@stor01 ~]# ps -ef |grep ceph-mds
ceph 16295 1 0 11:02 ? 00:00:00 /usr/bin/ceph-mds -f --cluster ceph --id stor01 --setuser ceph --setgroup ceph
查看MDS的相关状态可以发现,刚添加的MDS处于Standby模式:
[cephadm@ceph-admin ceph-cluster]$ ceph mds stat
1 up:standby #此时还没有存储池,所以未active
使用CephFS之前需要事先于集群中创建一个文件系统,并为其分别指定元数据和数据相关的存储池。下面创建一个名为cephfs的文件系统用于测试,它使用cephfs-metadata为元数据存储池,使用cephfs-data为数据存储池:
[cephadm@ceph-admin ~]$ ceph osd pool create cephfs-metadata 64 #metadata池
pool 'cephfs-metadata' created
[cephadm@ceph-admin ~]$ ceph osd pool create cephfs-data 64 #data池
pool 'cephfs-data' created
#ceph fs new <fs_name> <metadata> <data>
[cephadm@ceph-admin ~]$ ceph fs new cephfs cephfs-metadata cephfs-data #创建文件系统
new fs with metadata pool 7 and data pool 8
而后即可使用如下命令“ceph fs status ”查看文件系统的相关状态,例如:
[cephadm@ceph-admin ~]$ ceph fs status cephfs
cephfs - 0 clients
======
+------+--------+--------+---------------+-------+-------+
| Rank | State | MDS | Activity | dns | inos |
+------+--------+--------+---------------+-------+-------+
| 0 | active | stor01 | Reqs: 0 /s | 10 | 13 |
+------+--------+--------+---------------+-------+-------+
+-----------------+----------+-------+-------+
| Pool | type | used | avail |
+-----------------+----------+-------+-------+
| cephfs-metadata | metadata | 96.0k | 250G |
| cephfs-data | data | 0 | 250G |
+-----------------+----------+-------+-------+
+-------------+
| Standby MDS |
+-------------+
+-------------+
MDS version: ceph version 14.2.22 (ca74598065096e6fcbd8433c8779a2be0c889351) nautilus (stable)
此时,MDS的状态已经发生了改变:
[cephadm@ceph-admin ~]$ ceph mds stat
cephfs:1 {0=stor01=up:active}
随后,客户端通过内核中的cephfs文件系统接口即可挂载使用cephfs文件系统,或者通过FUSE接口与文件系统进行 交互。
如果之前部署失败了,不必删除ceph客户端,或者重新搭建虚拟机,只需要在每个节点上执行如下指令即可将环境清理至刚安装完ceph客户端时的状态!强烈建议在旧集群上搭建之前清理干净环境,否则会发生各种异常情况。
ps aux|grep ceph |awk '{print $2}'|xargs kill -9
ps -ef|grep ceph
#确保此时所有ceph进程都已经关闭!!!如果没有关闭,多执行几次。
umount /var/lib/ceph/osd/*
rm -rf /var/lib/ceph/osd/*
rm -rf /var/lib/ceph/mon/*
rm -rf /var/lib/ceph/mds/*
rm -rf /var/lib/ceph/bootstrap-mds/*
rm -rf /var/lib/ceph/bootstrap-osd/*
rm -rf /var/lib/ceph/bootstrap-rgw/*
rm -rf /var/lib/ceph/tmp/*
rm -rf /etc/ceph/*
rm -rf /var/run/ceph/*
https://blog.csdn.net/qinjiamao1/article/details/107042610?spm=1001.2014.3001.5501
https://blog.csdn.net/qinjiamao1/article/details/107115014?spm=1001.2014.3001.5501
https://blog.csdn.net/qinjiamao1/article/details/107239287?spm=1001.2014.3001.5501