02 Ceph管理介绍
[cephadm@ceph-admin ~]$ ceph -s
cluster:
id: 6af58884-134c-48e0-bd62-f37f302c8108
health: HEALTH_WARN
mons are allowing insecure global_id reclaim
services:
mon: 3 daemons, quorum stor01,stor02,stor03 (age 2h)
mgr: stor01(active, since 105m), standbys: stor02
mds: cephfs:1 {0=stor01=up:active}
osd: 8 osds: 8 up (since 86m), 8 in (since 86m)
rgw: 1 daemon active (stor03)
task status:
data:
pools: 8 pools, 352 pgs
objects: 214 objects, 3.6 KiB
usage: 8.0 GiB used, 792 GiB / 800 GiB avail
pgs: 352 active+clean
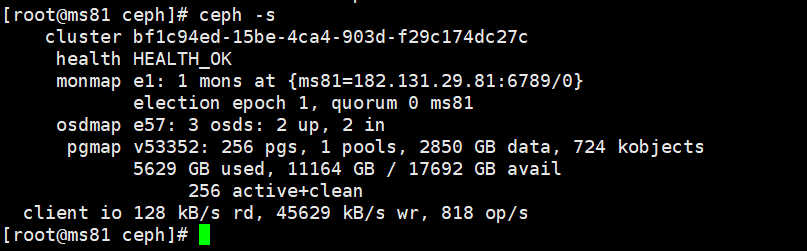
输出信息
- 集群 ID
- 集群运行状况
- 监视器地图版本号和监视器仲裁的状态(Paxos协议)
- OSD地图版本号和OSD的状态
- 归置组地图版本
- 归置组和存储池数量
- 所存储数据理论上的数量和所存储对象的数量
- 所存储数据的总量
- ceph pg stat
- ceph osd pool stats
- ceph df
- ceph df detail
ceph df [detail]
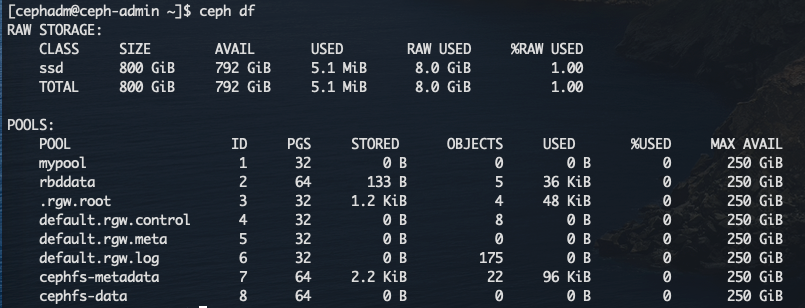
输出两段内容:GLOBAL和POOLS
- GLOBAL:存储量概览
- POOLS:存储池列表和每个存储池的理论用量,但出不反映副本、克隆数据或快照
GLOBAL段(RAW STORAGE)
- **SIZE:**集群的整体存储容量(所有OSD容量之和)
- **AVAIL:**整体存储容量中的可用容量
- USED:
- **RAW USED:**已用的原始存储量
- **%RAW USED:**已用的原始存储量百分比。将此数字与 full ratio 和 near full ratio 搭配使用,可确保您不会用完集群的容量。
输出的 POOLS 段展示了存储池列表及各存储池的大致使用率。本段没有反映出副本、克隆和快照的占用情况。例如,如果你把 1MB 的数据存储为对象,理论使用量将是 1MB ,但考虑到副本数、克隆数、和快照数,实际使用量可能是 2MB 或更多。
- **NAME:**存储池名字。
- **ID:**存储池唯一标识符。
- **PGS:**当前存储池的pg数
- **Objects:**各存储池内的大概对象数。
- **USED:**大概数据量,单位为 KB 、MB 或 GB ;
- **%USED:**各存储池的大概使用率。
- **MAX AVAIL:**当前存储池的最大使用容量,取决于当前集群的
osd总容量/副本数。
注意: POOLS 段内的数字是估计值,它们不包含副本、快照或克隆。因此,各 Pool 的 USED 和 %USED 数量之和不会达到 GLOBAL 段中的 RAW USED 和 %RAW USED 数量。
可通过执行以下命令来检查OSD,以确保它们已启动且正在运行
- ceph osd stat
- ceph osd dump
[root@stor01 ~]# ceph osd stat
8 osds: 8 up (since 36m), 8 in (since 30h); epoch: e116 # 总共有多少个 OSD 、几个是 up 的、几个是 in 的、osd map 的版本( eNNNN )
还可以根据OSD在CRUSH地图中的位置查看OSD
- ceph osd tree :Ceph将列显CRUSH树及主机、它的OSD、OSD是否已启动及其权重
#如果处于 in 状态的 OSD 多于 up 的,用下列命令看看哪些 ceph-osd 守护进程没在运行:
[root@stor01 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.78113 root default
-3 0.19528 host stor01
0 ssd 0.07809 osd.0 up 1.00000 1.00000
1 ssd 0.11719 osd.1 up 1.00000 1.00000
-5 0.19528 host stor02
2 ssd 0.07809 osd.2 up 1.00000 1.00000
3 ssd 0.11719 osd.3 up 1.00000 1.00000
-7 0.19528 host stor03
4 ssd 0.07809 osd.4 up 1.00000 1.00000
5 ssd 0.11719 osd.5 up 1.00000 1.00000
-9 0.19528 host stor04
6 ssd 0.07809 osd.6 up 1.00000 1.00000
7 ssd 0.11719 osd.7 up 1.00000 1.00000
集群中存在多个Mon主机时,应该在启动集群之后读取或写入数据之前检查Mon的仲裁状态。事实上,管理员也应该定期检查这种仲裁结果
显示监视器映射:
- ceph mon stat
- ceph mon dump
[root@stor01 ~]# ceph mon stat
e1: 3 mons at {stor01=[v2:10.37.129.10:3300/0,v1:10.37.129.10:6789/0],stor02=[v2:10.37.129.11:3300/0,v1:10.37.129.11:6789/0],stor03=[v2:10.37.129.12:3300/0,v1:10.37.129.12:6789/0]}, election epoch 66, leader 0 stor01, quorum 0,1,2 stor01,stor02,stor03
[root@stor01 ~]# ceph mon dump
epoch 1
fsid 6af58884-134c-48e0-bd62-f37f302c8108
last_changed 2021-10-07 09:30:13.913895
created 2021-10-07 09:30:13.913895
min_mon_release 14 (nautilus)
0: [v2:10.37.129.10:3300/0,v1:10.37.129.10:6789/0] mon.stor01
1: [v2:10.37.129.11:3300/0,v1:10.37.129.11:6789/0] mon.stor02
2: [v2:10.37.129.12:3300/0,v1:10.37.129.12:6789/0] mon.stor03
dumped monmap epoch 1
显示仲裁状态(检查监视器的法定人数状态):
- ceph quorum_status [-f json-pretty]
[root@stor01 ~]# ceph quorum_status
{"election_epoch":66,"quorum":[0,1,2],"quorum_names":["stor01","stor02","stor03"],"quorum_leader_name":"stor01","quorum_age":2447,"monmap":{"epoch":1,"fsid":"6af58884-134c-48e0-bd62-f37f302c8108","modified":"2021-10-07 09:30:13.913895","created":"2021-10-07 09:30:13.913895","min_mon_release":14,"min_mon_release_name":"nautilus","features":{"persistent":["kraken","luminous","mimic","osdmap-prune","nautilus"],"optional":[]},"mons":[{"rank":0,"name":"stor01","public_addrs":{"addrvec":[{"type":"v2","addr":"10.37.129.10:3300","nonce":0},{"type":"v1","addr":"10.37.129.10:6789","nonce":0}]},"addr":"10.37.129.10:6789/0","public_addr":"10.37.129.10:6789/0"},{"rank":1,"name":"stor02","public_addrs":{"addrvec":[{"type":"v2","addr":"10.37.129.11:3300","nonce":0},{"type":"v1","addr":"10.37.129.11:6789","nonce":0}]},"addr":"10.37.129.11:6789/0","public_addr":"10.37.129.11:6789/0"},{"rank":2,"name":"stor03","public_addrs":{"addrvec":[{"type":"v2","addr":"10.37.129.12:3300","nonce":0},{"type":"v1","addr":"10.37.129.12:6789","nonce":0}]},"addr":"10.37.129.12:6789/0","public_addr":"10.37.129.12:6789/0"}]}}
元数据服务器有两种状态: up | down 和 active | inactive
ceph mds stat
ceph mds dump
ceph pg stat
ceph pg dump [pgs_brief]
ceph pg map <pgid>#查看指定 PG 的 Acting Set 或 Up Set 中包含的 OSD你也可以让它输出到 JSON 格式,并保存到文件:
ceph pg dump -o {filename} --format=json
- 要查询某个 PG,用下列命令,Ceph 会输出成 JSON 格式:
ceph pg <pgid> query
- 找出有问题的归置组
ceph pg dump_stuck [unclean|inactive|stale|undersized|degraded]
示例:
[root@stor01 ~]# ceph pg stat
448 pgs: 448 active+clean; 1004 MiB data, 3.0 GiB used, 789 GiB / 800 GiB avail
#PG总数;有多少PG处于某种特定状态如 active+clean;数据大小(单副本);数据占据的空间;剩余可用空间/总空间
[root@stor01 ~]# ceph pg map 8.1e
osdmap e166 pg 8.1e (8.1e) -> up [1,3,4] acting [1,3,4]
# osdmap 版本( eNNN )、PG 号( {pg-num} )、Up Set 内的 OSD ( up[] )、和 Acting Set 内的 OSD ( acting[] )
要把对象数据存入 Ceph 对象存储, Ceph 客户端必须:
- 设置对象名
- 指定存储池
Ceph 客户端索取最新集群 map、并用 CRUSH 算法计算对象到 PG 的映射,然后计算如何动态地把 PG 分配到 OSD 。要定位对象位置,只需要知道对象名和存储池名字:
ceph osd map {poolname} {object-name}
我们先创建一个对象。给 rados put 命令指定一对象名、一个包含数据的测试文件路径、和一个存储池名字,例如:
rados put {object-name} {file-path} --pool=data
rados put test-object-1 testfile.txt --pool=data
用下列命令确认 Ceph 对象存储已经包含此对象:
rados -p data ls
现在可以定位对象了:
ceph osd map {pool-name} {object-name}
ceph osd map data test-object-1
Ceph 应该输出对象的位置,例如:
osdmap e537 pool 'data' (0) object 'test-object-1' -> pg 0.d1743484 (0.4) -> up [1,0] acting [1,0]
要删除测试对象,用 rados rm 即可,如:
rados rm test-object-1 --pool=data
Ceph的管理套接字接口常用于查询和配置守护进程,临时生效,不能持久生效。尤其是可以查询守护进程的默认配置项。
- 套接字默认保存 于/var/run/ceph目录
- 此接口的使用不能以远程方式进程,使用时需要先登录它所在的主机
- 管理套接字命令允许你在运行时查看和修改配置
命令的使用格式:
ceph daemon {type.id|/var/run/ceph/<socket-name>} <cmd>
或
ceph --admin-daemon /var/run/ceph/<socket-name> <cmd>
获取使用帮助:
ceph daemon {type.id|/var/run/ceph/<socket-name>} help
或
ceph --admin-daemon /var/run/ceph/<socket-name> help
示例:
[root@stor01 ~]# ceph daemon osd.0 help
[root@stor01 ~]# ceph daemon osd.0 config show
[root@stor01 ~]# ceph daemon /var/run/ceph/ceph-osd.0.asok config show
[root@stor01 ~]# ceph daemon mon.stor01 help
1、告知Ceph集群不要将OSD标记为out:ceph osd set noout
2、按如下顺序停止守护进程和节点:
- 存储客户端
- 网关,例如 NFS Ganesha 或对象网关
- 元数据服务器
- Ceph OSD
- Ceph Manager
- Ceph Monitor
1、以与停止过程相关的顺序启动节点:
- Ceph Monitor
- Ceph Manager
- Ceph OSD
- 元数据服务器
- 网关,例如 NFS Ganesha 或对象网关
- 存储客户端
2、删除noout标志:ceph osd unset noout
ceph配置文件会在ceph守护进程启动时覆盖默认配置,使用的是ini风格的语法,可以使用#或;进行注释。
配置文件可以实现对所有类型的所有守护进程、某一个类型的所有守护、某一个守护进程实例单独进行配置:
[global]:对所有类型的所有守护进程进行配置[osd]:对所有的ceph-osd进行进行配置,并会覆盖[global]中相同配置。[mon]:对所有的ceph-mon进行进行配置,并会覆盖[global]中相同配置。[client]:对所有的ceph客户端进行配置(for example, mounted Ceph block devices, Ceph object gateways, and so on)[TPYE.ID]:对进程的某个实例进行配置。例如[mon.a], [mon.b], [osd.0],对于OSD进程,ID一般为数字;对于MON进程,ID一般为alphanumeric。
可以使用如下方式查询TPYE.ID:
[root@stor01 ~]# ceph osd tree ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.78113 root default -3 0.19528 host stor01 0 ssd 0.07809 osd.0 up 1.00000 1.00000 #osd.0 1 ssd 0.11719 osd.1 up 1.00000 1.00000 -5 0.19528 host stor02 2 ssd 0.07809 osd.2 up 1.00000 1.00000 3 ssd 0.11719 osd.3 up 1.00000 1.00000 -7 0.19528 host stor03 4 ssd 0.07809 osd.4 up 1.00000 1.00000 5 ssd 0.11719 osd.5 up 1.00000 1.00000 -9 0.19528 host stor04 6 ssd 0.07809 osd.6 up 1.00000 1.00000 7 ssd 0.11719 osd.7 up 1.00000 1.00000 [root@stor01 ~]# ceph mon stat e1: 3 mons at {stor01=[v2:10.37.129.10:3300/0,v1:10.37.129.10:6789/0],stor02=[v2:10.37.129.11:3300/0,v1:10.37.129.11:6789/0],stor03=[v2:10.37.129.12:3300/0,v1:10.37.129.12:6789/0]}, election epoch 66, leader 0 stor01, quorum 0,1,2 stor01,stor02,stor03 #stor01为ID,TPYE.ID为“mon.stor01” [root@stor01 ~]# ceph mon dump epoch 1 fsid 6af58884-134c-48e0-bd62-f37f302c8108 last_changed 2021-10-07 09:30:13.913895 created 2021-10-07 09:30:13.913895 min_mon_release 14 (nautilus) 0: [v2:10.37.129.10:3300/0,v1:10.37.129.10:6789/0] mon.stor01 #mon.stor01 1: [v2:10.37.129.11:3300/0,v1:10.37.129.11:6789/0] mon.stor02 2: [v2:10.37.129.12:3300/0,v1:10.37.129.12:6789/0] mon.stor03 dumped monmap epoch 1
$CEPH_CONF(the path following the $CEPH_CONF environment variable)-c path/path(the -c command line argument)/etc/ceph/ceph.conf~/.ceph/config./ceph.conf(in the current working directory)
元变量极大地简化了Ceph存储集群配置。当在配置值中设置元变量时,Ceph会将元变量扩展为具体值。在Ceph配置文件的 [global]、[osd]、[mon] 或 [client] 部分中使用时,元变量非常强大。 但是,您也可以将它们与管理套接字一起使用。Ceph元变量类似于Bash shell扩展。
常用的元变量
$cluster:当前Ceph集群的名称$type:当前服务的类型名称,可能会展开为osd或mon;$id:进程的标识符,例如对osd.0来说,其标识符为0;$host:守护进程所在主机的主机名;$name:其值为$type.$id
ceph daemon {daemon-type}.{id} config show
ceph daemon {daemon-type}.{id} help
ceph daemon {daemon-type}.{id} config get {parameter}
例如:ceph daemon osd.0 config get public_addr
#方式1:通过ceph mon,可以远程执行,需要依赖monitor
ceph tell {daemon-type}.{daemon id or *} injectargs --{name} {value} [--{name} {value}]
例如:ceph tell osd.0 injectargs '--debug-osd 0/5'
#方式2:通过administration socket,只能本地执行,不依赖monitor
ceph daemon {daemon-type}.{id} set {name} {value}
例如:ceph daemon osd.0 config set debug_osd 0/5