05 Rbd
RBD,全称RADOS Block Devices,是一种建构在RADOS存储集群之上为客户端提供块设备接口的存储服务中间层,这类的客户端包括虚拟化程序KVM(结合qemu)和云计算操作系统OpenStack和CloudStack等。
RBD基于RADOS存储集群中的多个OSD进行条带化,支持存储空间的简配(thin- provisioning)和动态扩容等特性,并能够借助于RADOS集群实现快照、副本和一 致性。
RBD自身也是RADOS存储集群的客户端,它通过将存储池提供的存储服务抽象为一到多个image(表现为块设备)向客户端提供块级别的存储接口。
RBD支持两种格式的image,不过v1格式因特性较少等原因已经处于废弃状态,当前默认的为v2格式
客户端访问RBD设备的方式有两种:
- 内核模块rbd.ko通过rbd协议将image映射为节点本地的块设备,相关的设备文件一般为/dev/rdb#(#为设备编号,例如rdb0等)
[root@stor01 ~]# modinfo rbd
filename: /lib/modules/3.10.0-1127.19.1.el7.x86_64/kernel/drivers/block/rbd.ko.xz #内核模块
license: GPL
description: RADOS Block Device (RBD) driver
author: Jeff Garzik <jeff@garzik.org>
author: Yehuda Sadeh <yehuda@hq.newdream.net>
author: Sage Weil <sage@newdream.net>
author: Alex Elder <elder@inktank.com>
retpoline: Y
rhelversion: 7.8
srcversion: 5386BBBD00C262C66CB81F5
depends: libceph
intree: Y
vermagic: 3.10.0-1127.19.1.el7.x86_64 SMP mod_unload modversions
signer: CentOS Linux kernel signing key
sig_key: B1:6A:91:CA:C9:D6:51:46:4A:CB:7A:D9:B8:DE:D5:57:CF:1A:CA:27
sig_hashalgo: sha256
parm: single_major:Use a single major number for all rbd devices (default: true) (bool)
#如果没有加载,可以使用modprobe rbd进行加载
- 另一种则是通过librbd库提供的API接口,它支持C/C++和Python等编程语言,qemu就是此类接口的客户端(是一个调用librbd的Client来连接Ceph集群)。Libvirt是一套用于管理、操作虚拟机的常用的工具集。它支持多种虛拟化引擎,如主流的KVM、Xen、Hyper-V 都支持。
典型的 Openstack+Ceph的环境中,其中 Openstack 的三个组件: Nova/Cinder/Glance 均已经对接到了Ceph集群中,也就是说虚机系统盘,云硬盘,镜像都保存在Ceph中。而这三个客户端调用Ceph的方式不太一样:
- Glance :上传下载镜像等时,需要新建一个调用 librbd 的 Client 来连接 Ceph集群。
- Cinder :
- 创建删除云盘时,新建一个调用 librbd 的 Client 来连接 Ceph 集群。
- 挂载卸载云盘时,由Nova调用librbd来实现该操作。
- Nova : 虚机(qemu-kvm进程)相当于一个始终在调用librbd的Client,并且进程始终都在。
我们需要知道的是,当一个 Client 需要连接 Ceph 集群时,它首先通过自己的用户名和秘钥(client.cinder/client.nova…) 来连接到
/etc/ceph/ceph.conf配置文件指定IP的MON,认证成功后,可以获取集群的很多MAP( monmap,osdmap,crushmap…),通过这些 MAP,即可向 Ceph 集群读取数据。对于一个虚机进程(qemu-kvm)来说,虚机启动之初,它即获取到了集群的 monmap, 而当所连接 MON 的 IP 变化时,比如这个 MON 挂掉时,它便会尝试连接 monmap 里面的其他 IP 的 MON,如果每个MON都挂了,那么这个 Client 就不能连接上集群获取最新的 monmap,osdmap等。
下面我们以一个 pid为3171的 qemu-kvm 进程来演示这一过程:
[root@con ~(keystone_admin)]# ps -ef|grep kvm qemu 3171 1 17 14:32 ? 00:31:08 /usr/libexec/qemu-kvm -name guest=instance-0000000b......... [root@con ~(keystone_admin)]# netstat -tnp |grep 3171|grep 6789 tcp 0 0 192.168.100.110:59926 192.168.100.112:6789 ESTABLISHED 3171/qemu-kvm可以看到,这个进程连接着IP为
192.168.100.112的 MON,而我们手动将这个IP的 MON 停掉,则会发现这个进程又连接到了剩余两个IP的MON之一上:[root@con ~(keystone_admin)]# ssh 192.168.100.112 systemctl stop ceph-mon.target [root@con ~(keystone_admin)]# netstat -tnp |grep 3171|grep 6789 tcp 0 0 192.168.100.110:48792 192.168.100.111:6789 ESTABLISHED 3171/qemu-kvm
RBD相关的管理有如image的创建、删除、修改和列出等基础CRUD操作,也有分组、镜像、快照和回收站等相的管理需求,这些均能够通过rbd命令完成
rbd [-c ceph.conf] [-m monaddr] [--cluster cluster-name] [-p|--pool pool] [command...]
#rbd的指令如果省略-p / --pool参数,则会默认-p rbd,而这个rbd pool是默认生成的。
使用块设备客户端之前必须事先创建专用的存储池、启用rbd并完成其初始化:
ceph osd pool create {pool-name} {pg-num} {pgp-num} #创建存储池
ceph osd pool application enable {pool-name} rbd #启用rbd应用
rbd pool init -p {pool-name} #rbd初始化(该命令是启用rbd应用的第二种方式)
从Luminous开始,所有池都需要使用该池与应用程序关联。目的是指定pool的应用类型(即用途:‘cephfs’, ‘rbd’, ‘rgw’,自定义应用类型)。与cepfs一起使用的池或由RGW自动创建的池将自动关联。打算与RBD一起使用的池应使用
rbd工具进行初始化。对于其他情况,可以手动使用自定义应用程序名称与池关联。
示例:
[root@stor01 ~]# ceph osd pool create kube 64 64
pool 'kube' created
[root@stor01 ~]# ceph osd pool application enable kube rbd
enabled application 'rbd' on pool 'kube'
例如:指定该pool用于RBD:
#第一种方式:使用rbd pool init <poolname>命令对pool进行application配置
[cephadm@node-1 ceph-cluster]$ ceph osd pool application get pool-demo
{}
[cephadm@node-1 ceph-cluster]$ rbd pool init pool-demo #初始化为rbd池
[cephadm@node-1 ceph-cluster]$ ceph osd pool application get pool-demo
{
"rbd": {}
}
#第二种方式:使用osd pool application enable <pool> <app>命令指定
[cephadm@node-1 ceph-cluster]$ ceph osd pool create pool-demo2 128 128
pool 'pool-demo2' created
[cephadm@node-1 ceph-cluster]$ ceph osd pool application enable pool-demo2 rbd
enabled application 'rbd' on pool 'pool-demo2'
[cephadm@node-1 ceph-cluster]$ ceph osd pool application get pool-demo2
{
"rbd": {}
}
如果上述命令未执行,在该pool被使用后,则会出现警告信息:
[cephadm@node-1 ceph-cluster]$ ceph -s
cluster:
id: 9ebc9b51-1406-43cc-bdd2-d560e58d842f
health: HEALTH_WARN
application not enabled on 1 pool(s)
services:
mon: 3 daemons, quorum node-1,node-2,node-3 (age 4h)
mgr: node-1(active, since 5h), standbys: node-2
osd: 6 osds: 6 up (since 5h), 6 in (since 5h)
data:
pools: 2 pools, 160 pgs
objects: 2 objects, 288 B
usage: 6.4 GiB used, 1.2 TiB / 1.2 TiB avail
pgs: 160 active+clean
可以这样查看健康警告信息的详情:
[cephadm@node-1 ceph-cluster]$ ceph health detail
HEALTH_WARN application not enabled on 1 pool(s)
POOL_APP_NOT_ENABLED application not enabled on 1 pool(s)
application not enabled on pool 'pool-demo'
use 'ceph osd pool application enable <pool-name> <app-name>', where <app-name> is 'cephfs', 'rbd', 'rgw', or freeform for custom applications.
# 修复警告:指定pool的用途
[cephadm@node-1 ceph-cluster]$ ceph osd pool application enable pool-demo rbd
# 查看pool的应用类型
[cephadm@node-1 ~]$ ceph osd pool application get pool-demo
{
"rbd": {}
}
image即块设备。
rbd所有相关的操作都支持一些两种指定方式:
[--pool <pool>] [--namespace <namespace>] [--image <image>][<pool-name>/[<namespace>/]]<image-name>#pool下可以划分多个namespace例如:
rbd create pool-demo/rbd-demo.img --size 1G rbd create --pool pool-demo --image rbd-demo.img --size 1G rbd info pool-demo/rbd-demo.img rbd info --pool pool-demo --image rbd-demo.img rbd ls pool-demo rbd ls -p pool-demo
rbd create --size <megabytes> [--order <order>] [--object-size <object-size>] --pool <pool-name> <image-name>|<image-spec> #创建image可以指定object的大小,默认为4M
示例:
#下面的命令于存储池kube中创建了一个大小为2GB的映像myimg:
rbd create --pool kube --size 2G vol01
或rbd create --size 2G kube/vol01
#创建了image后,-size大小的对象。
[root@stor01 ~]# rados ls -p kube #查看Pool中的object列表,对象前缀可以使用rbd info kube/vol01
rbd_data.281973cfd095.0000000000000101
rbd_data.281973cfd095.0000000000000008
rbd_data.28266268ad5df.0000000000000120
rbd_data.281973cfd095.0000000000000020
...
存储池中的各image名称需要惟一,rbd ls命令能够列出指定存储池中的image:
rbd ls [-p <pool-name>] [--long|-l] [--format json|xml] [--pretty-format] <pool-name> #-l 参数会把image的快照也列出来
示例:
[root@stor01 ~]# rbd ls -p kube
vol01
[root@stor01 ~]# rbd ls kube #-p可以省略
vol01
要获取指定image的详细信息,则通常使用“rbd info”命令:
rbd info [--pool <pool>] [--image <image>] [--image-id <image-id>] [--format <format>] [--pretty-format] <image-spec>
示例:
[root@stor01 ~]# rbd info kube/vol01
rbd image 'vol01':
size 2 GiB in 512 objects
order 22 (4 MiB objects) #2^22=4M
snapshot_count: 0
id: 281973cfd095
block_name_prefix: rbd_data.281973cfd095
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
op_features:
flags:
create_timestamp: Thu Oct 7 19:27:24 2021
access_timestamp: Thu Oct 7 19:27:24 2021
modify_timestamp: Thu Oct 7 19:27:24 2021
size M GiB in N objects
- image空间大小为M,共分割至N个对象(分割的数量由条带大小决定);
order 22 (4 MiB objects)
- 块大小(条带)的标识序号,有效范围为12-25,分别对应着4K-32M之间的大小;默认为4M(22是个编号,4M是22, 8M是23,也就是2^22 bytes = 4MB, 2^23 bytes = 8MB。)
id
- 当前image的标识符;
block_name_prefix
- 当前image相关的object的名称前缀;这个是块的最重要的属性了,这是每个块在ceph中的唯一前缀编号,有了这个前缀,把服务器上的OSD都拔下来带回家,就能复活所有的VM了。
format
- image的格式,其中的“2”表示“v2”;
features
- 当前image启用的功能特性,其值是一个以逗号分隔的字符串列表,例如layering、exclusive-lock等;
op_features
- 可选的功能特性;
- layering: 是否支持分层克隆(链接克隆);
- striping: 是否支持数据对象间的数据条带化;
- exclusive-lock: 是否支持分布式排他锁机制以限制同时仅能有一个客户端访问当前image;
- object-map: 是否支持object位图,主要用于加速导入、导出及已用容量统计等操作,依赖于exclusive-lock特性;
- fast-diff: 是否支持快照间的快速比较操作,依赖于object-map特性;
- deep-flatten: 是否支持克隆分离时解除在克隆image时创建的快照与其父image之间的关联关系(快照展平);
- journaling: 是否支持日志IO,即是否支持记录image的修改操作至日志对象;依赖于exclusive-lock特性;
- data-pool: 是否支持将image的数据对象存储于纠删码存储池,主要用于将image 的元数据与数据放置于不同的存储池;
配置项为rbd_default_features = [3 or 61],这个值是由几个属性加起来的:
only applies to format 2 images
- +1 for layering,
- +2 for stripingv2,
- +4 for exclusive lock,
- +8 for object map
- +16 for fast-diff,
- +32 for deep-flatten,
- +64 for journaling
所以61=1+4+8+16+32就是layering | exclusive lock | object map |fast-diff |deep-flatten这些属性的大合集,需要哪个不需要哪个,做个简单的加法配置好rbd_default_features就可以了。
J版本起,image默认支持的特性有layering、exclusive-lock、object-map、fast-diff和 deep-flatten五个;
- rbd create命令的–feature选项支持创建时自定义支持的特性;
- 现有image的特性可以使用
rbd feature enable <image_spec> <feature...>或rbd feature disable <image_spec> <feature...>命令修改 - linux内核目前只支持layering、exclusive-lock这2个特性。(对某些特性,低版本的内核可能不支持,需要禁用某些特性)
示例:
[root@stor01 ~]# sudo rbd map pool-demo/rbd-demo.img
rbd: sysfs write failed
RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable pool-demo/rbd-demo.img object-map fast-diff deep-flatten".
In some cases useful info is found in syslog - try "dmesg | tail".
rbd: map failed: (6) No such device or address
#报错,是因为当前版本的内核不支持image的某些特性,可以根据提示,禁用不支持的特性后再进行映射操作;可以在ceph.conf中永久指定启用哪些feature,例如: rbd_default_features=1 只启用一个feature
[root@stor01 ~]# rbd feature disable kube/vol01 object-map fast-diff deep-flatten
[root@stor01 ~]# rbd info kube/vol01
rbd image 'vol01':
size 2 GiB in 512 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 281973cfd095
block_name_prefix: rbd_data.281973cfd095
format: 2
features: layering, exclusive-lock
op_features:
flags:
create_timestamp: Thu Oct 7 19:27:24 2021
access_timestamp: Thu Oct 7 19:27:24 2021
modify_timestamp: Thu Oct 7 19:27:24 2021
rbd resize [--pool <pool>] [--image <image>] --size <size> [--allow-shrink]
[--no-progress] <image-spec>
#增大:
rbd resize [--pool <pool>] [--image <image>] --size <size>
#减少:不建议进行缩减操作
rbd resize [--pool <pool>] [--image <image>] --size <size> [--allow-shrink]
示例:
[root@stor01 ~]# rbd ls -p kube
vol01
[root@stor01 ~]# rbd resize kube/vol01 --size 3G
Resizing image: 100% complete...done.
[root@stor01 ~]# rbd ls -p kube -l
NAME SIZE PARENT FMT PROT LOCK
vol01 3 GiB 2
# 文件系统扩容
[cephadm@node-1 ceph-cluster]$ df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 3.8G 0 3.8G 0% /dev
tmpfs 3.8G 0 3.8G 0% /dev/shm
tmpfs 3.8G 8.6M 3.8G 1% /run
tmpfs 3.8G 0 3.8G 0% /sys/fs/cgroup
/dev/sda1 40G 2.0G 36G 6% /
tmpfs 773M 0 773M 0% /run/user/0
/dev/rbd0 976M 2.6M 907M 1% /mnt
#发现,块设备已经扩容到10G了,但是文件系统还是之前的1G。需要对文件系统进行扩容。
# 我们之前没有对设备进行分区,所以无需扩展分区,只进行文件系统扩容即可。(也正是这个原因,云存储设备建议直接使用,不建议再做分区)
[cephadm@node-1 ceph-cluster]$ sudo resize2fs /dev/rbd0
resize2fs 1.42.9 (28-Dec-2013)
Filesystem at /dev/rbd0 is mounted on /mnt; on-line resizing required
old_desc_blocks = 1, new_desc_blocks = 2
The filesystem on /dev/rbd0 is now 2621440 blocks long.
[cephadm@node-1 ceph-cluster]$ df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 3.8G 0 3.8G 0% /dev
tmpfs 3.8G 0 3.8G 0% /dev/shm
tmpfs 3.8G 8.6M 3.8G 1% /run
tmpfs 3.8G 0 3.8G 0% /sys/fs/cgroup
/dev/sda1 40G 2.0G 36G 6% /
tmpfs 773M 0 773M 0% /run/user/0
/dev/rbd0 9.9G 4.5M 9.4G 1% /mnt
rbd -p volumes rename <old_name> <new_name>
rbd remove [--pool <pool>] [--image <image>] [--no-progress] <image-spec>
删除image会导致数据丢失,且不可恢复;建议使用trash命令先将其移入trash,确定不再 需要时再从trash中删除;
rbd trash {list|move|purge|remove|restore} [--pool <pool>] [--image <image>] <image-spec>
#rbd help trash restore
rbd trash move [--pool <pool>] [--image <image>] [--expires-at <expires-at>] <image-spec> #--expires-at可以指定暂存时间
rbd trash restore [--pool <pool>] [--image-id <image-id>] [--image <image>] <image-id> #[<pool-name>/]<image-id>
示例:
[root@stor01 ~]# rbd ls -p kube -l
NAME SIZE PARENT FMT PROT LOCK
vol01 3 GiB 2
[root@stor01 ~]# rbd trash move kube/vol01 #可以指定暂存时间[--expires-at <YYYYMMDD>]
[root@stor01 ~]# rbd ls -p kube
[root@stor01 ~]# rbd trash list
rbd: error opening default pool 'rbd'
Ensure that the default pool has been created or specify an alternate pool name.
[root@stor01 ~]# rbd trash list -p kube
281973cfd095 vol01
[root@stor01 ~]# rbd trash restore -p kube --image vol01 --image-id 281973cfd095
[root@stor01 ~]# rbd ls kube
vol01
在RBD客户端节点上以本地磁盘方式使用块设备之前,需要先将目标image映射至本地内核device,而且,若存储集群端启用了CephX认证,还需要指定用户名和keyring 文件。
# 该操作需要使用root权限
rbd [--pool <pool>] [--image <image>] [--id|--user <user-name>] [--keyring </path/to/keyring>] map
注意:节点重启后,使用rbd命令建立的image映射会丢失
查看已经映射的image:
rbd showmapped
对于某些老版本的ceph,可以使用
rbd device list命令查看
断开映射:
rbd unmap [--pool <pool>] [--image <image>] <image-or-device-spec>
示例:在另一台ubuntu机器上使用rbd磁盘
#1、安装ceph-common包
root@ubuntu5:~# apt install ceph-common -y
# 2、准备keyring文件到/etc/ceph/;3、准备ceph.conf文件到/etc/ceph/
[cephadm@ceph-admin ceph-cluster]$ ceph auth get client.kube
[client.kube]
key = AQAHsF5h4W4sMhAAxBIAUb8i0PxUSpfdOiug0g==
caps mon = "allow r"
caps osd = "allow * pool=kube"
exported keyring for client.kube
[cephadm@ceph-admin ceph-cluster]$ scp ceph.conf ceph.client.kube.keyring root@ubuntu5:/etc/ceph
root@ubuntu5:~# ceph -s
2021-10-07 05:03:34.052715 7f9cf986e700 -1 auth: unable to find a keyring on /etc/ceph/ceph.client.admin.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin,: (2) No such file or directory
2021-10-07 05:03:34.052730 7f9cf986e700 -1 monclient: ERROR: missing keyring, cannot use cephx for authentication
2021-10-07 05:03:34.052731 7f9cf986e700 0 librados: client.admin initialization error (2) No such file or directory
[errno 2] error connecting to the cluster
# ceph命令默认使用admin用户连接rados集群,如果要指定其他用户,则需要时用--user参数
root@ubuntu5:~# ceph --user kube -s
cluster:
id: 6af58884-134c-48e0-bd62-f37f302c8108
health: HEALTH_WARN
client is using insecure global_id reclaim
mons are allowing insecure global_id reclaim
services:
mon: 3 daemons, quorum stor01,stor02,stor03 (age 54m)
mgr: stor01(active, since 54m), standbys: stor02
mds: cephfs:1 {0=stor01=up:active}
osd: 8 osds: 8 up (since 54m), 8 in (since 9h)
rgw: 1 daemon active (stor03)
task status:
data:
pools: 8 pools, 352 pgs
objects: 213 objects, 6.4 KiB
usage: 8.0 GiB used, 792 GiB / 800 GiB avail
pgs: 352 active+clean
root@ubuntu5:~# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 64G 0 disk
└─sda1 8:1 0 64G 0 part
├─ubuntu--18--vg-root 253:0 0 63G 0 lvm /
└─ubuntu--18--vg-swap_1 253:1 0 980M 0 lvm [SWAP]
sr0 11:0 1 1024M 0 rom
#rbd进行map
root@ubuntu5:~# rbd map kube/vol01 --id kube
/dev/rbd0
root@ubuntu5:~# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 64G 0 disk
└─sda1 8:1 0 64G 0 part
├─ubuntu--18--vg-root 253:0 0 63G 0 lvm /
└─ubuntu--18--vg-swap_1 253:1 0 980M 0 lvm [SWAP]
sr0 11:0 1 1024M 0 rom
rbd0 252:0 0 2G 0 disk
#后续分区、格式化就可以使用了
root@ubuntu5:~# mke2fs -t ext4 /dev/rbd0
mke2fs 1.44.1 (24-Mar-2018)
Discarding device blocks: done
Creating filesystem with 524288 4k blocks and 131072 inodes
Filesystem UUID: b6e87f46-3cae-45de-b557-63ca9365fb05
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912
Allocating group tables: done
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
root@ubuntu5:~# mount /dev/rbd0 /mnt
root@ubuntu5:~# df -h /mnt
Filesystem Size Used Avail Use% Mounted on
/dev/rbd0 2.0G 6.0M 1.8G 1% /mnt
root@ubuntu5:~# mount |grep rbd0
/dev/rbd0 on /mnt type ext4 (rw,relatime,stripe=1024,data=ordered)
root@ubuntu5:~# rbd showmapped #在执行map的机器上执行
id pool image snap device
0 kube vol01 - /dev/rbd0
[root@stor01 ~]# rbd ls -p kube -l
NAME SIZE PARENT FMT PROT LOCK
vol01 2 GiB 2 excl
#执行unmap
root@ubuntu5:~# rbd unmap /dev/rbd0
rbd: sysfs write failed
rbd: unmap failed: (16) Device or resource busy
root@ubuntu5:~# umount /mnt
root@ubuntu5:~# rbd unmap /dev/rbd0
可以rbd status命令查看client的信息:
# watch即客户端的信息
root@provider-ceph01:~# rbd status k8s-data/kubernetes-dynamic-pvc-55239e59-d817-11eb-8370-acde48613bdd
Watchers:
watcher=10.110.68.40:0/3019961510 client.78077205 cookie=18446462598732841169
RBD支持image快照技术:
- 快照可以保留image的状态历史
- Ceph还支持快照“分层”机制,从而可实现快速克隆VM映像;
- rbd命令及许多高级接口(包括QEMU、libvirt、OpenStack等)都支持设备快照
snap create (snap add) Create a snapshot.
snap limit clear Remove snapshot limit.
snap limit set Limit the number of snapshots.
snap list (snap ls) Dump list of image snapshots.
snap protect Prevent a snapshot from being deleted.
snap purge Delete all unprotected snapshots.
snap remove (snap rm) Delete a snapshot.
snap rename Rename a snapshot.
snap rollback (snap revert) Rollback image to snapshot.
snap unprotect Allow a snapshot to be deleted.
rbd snap create [--pool <pool>] --image <image> --snap <snap>
或者 rbd snap create [<pool-name>/]<image-name>@<snapshot-name>
注意:在创建映像快照之前应停止image上的IO操作,且image上存在文件系统时,还要确保其处于一致状态;
示例:
[root@stor01 ~]# rbd snap create kube/vol01@snap1
rbd snap ls [--pool <pool>] --image <image> [--format <format>] [--pretty-format] [--all]
示例:
[root@stor01 ~]# rbd snap ls kube/vol01
SNAPID NAME SIZE PROTECTED TIMESTAMP
4 snap1 3 GiB Thu Oct 7 20:44:08 2021
说明:快照的parent是该快照对应image的parent。即image和其snap的parent是同一个。
root@stor-mgt01:~# rbd snap create cinder.volumes/volume-3e5ebaa6@snapshot-6028564c
root@stor-mgt01:~# rbd ls -l cinder.volumes |grep -i 3e5ebaa6-265e-4999-a9f0-3d8971574096
NAME SIZE PARENT FMT PROT LOCK
volume-3e5ebaa6 40GiB glance.images/24d05428@snap 2
volume-3e5ebaa6@snapshot-6028564c 40GiB glance.images/24d05428@snap 2 yes
rbd snap rollback [--pool <pool>] --image <image> --snap <snap> <snap-spec> [--no-progress] #该操作需要先取消挂载和map
注意:将映像回滚到快照意味着会使用快照中的数据重写当前版本的image,而且执行回滚所需的时间将随映像大小的增加而延长
示例:
[root@stor01 ~]# rbd snap rollback kube/vol01@snap1
Rolling back to snapshot: 100% complete...done.
快照数量过多,必然会导致image上的原有数据第一次修改时的IO压力恶化
rbd snap limit set [--pool <pool>] [--image <image>] [--limit <limit>]
解除限制:
rbd snap limit clear [--pool <pool>] [--image <image>]
示例:
[root@stor01 ~]# rbd snap limit kube/vol01 --limit 10
[root@stor01 ~]# rbd snap limit clear kube/vol01
rbd snap rm [--pool <pool>] [--image <image>] [--snap <snap>] [--no-progress]
[--force]
提示:Ceph OSD会以异步方式删除数据,因此删除快照并不能立即释放磁盘空间;
示例:
[root@stor01 ~]# rbd snap rm kube/vol01@snap1
删除一个image的所有快照,可以使用rbd snap purge命令
rbd snap purge [--pool <pool>] --image <image> [--no-progress]
示例:
[root@stor01 ~]# rbd snap purge kube/vol01
Ceph支持在一个块设备快照的基础上创建一到多个COW或COR(Copy-On-Read) 类型的克隆,这种中间快照层(snapshot layering)机制提了一种极速创建image 的方式。
用户可以创建一个基础image并为其创建一个只读快照层,而后可以在此快照层上创建任意个克隆进行读写操作,甚至能够进行多级克隆。例如,实践中可以为Qemu虚拟机创建一个image并安装好基础操作系统环境作为模板, 对其创建创建快照层后,便可按需创建任意多个克隆作为image提供给多个不同的VM( 虚拟机)使用,或者每创建一个克隆后进行按需修改,而后对其再次创建下游的克隆。
通过克隆生成的image在其功能上与直接创建的image几乎完全相同,它同样支持 读、写、克隆、空间扩缩容等功能,惟一的不同之处是克隆引用了一个只读的上游快照,而且此快照必须要置于“保护”模式之下。
快照分层支持COW和COR两种类型:
- COW是为默认的类型,仅在数据首次写入时才需要将它复制到克隆的image中
- COR则是在数据首次被读取时复制到当前克隆中,随后的读写操作都将直接基 于此克隆中的对象进行
在RBD上使用分层克隆的方法非常简单:创建一个image,对image创建一个快照并将其置入保护模式,而后克隆此快照即可。
创建克隆的image时,需要指定引用的存储池、镜像和镜像快照,以及克隆的目标 image的存储池和镜像名称,因此,克隆镜像支持跨存储池进行。
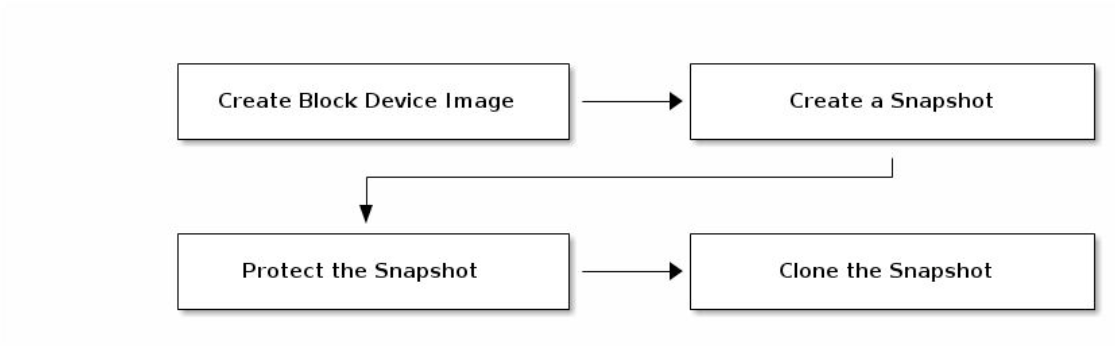
下游image需要引用上游快照中的数据,克隆出的镜像采用cow写时复制的技术,快照的意外删除必将导致数据服务的中止,因此在克隆操作之前,必须将上游的快照置于保护模式,设置了保护的快照是无法删除的:
rbd snap protect [--pool <pool>] --image <image> --snap <snap>
示例:
[root@stor01 ~]# rbd snap protect kube/vol01@snap1
[root@stor01 ~]# rbd snap ls kube/vol01
SNAPID NAME SIZE PROTECTED TIMESTAMP
4 snap1 3 GiB yes Thu Oct 7 20:44:08 2021
克隆:对保护快照进行克隆,生成一个新的image
rbd快照只能针对image的snap进行,无法直接对image进行克隆。
rbd clone [--pool <pool>] --image <image> --snap <snap> --dest-pool <dest-pool> [--dest <dest>
或者:rbd clone [<pool-name>/]<image-name>@<snapshot-name> [<pool-name>/]<image-name> #可以跨pool进行克隆
示例:
[root@stor01 ~]# rbd clone kube/vol01@snap1 kube/vol02
[root@stor01 ~]# rbd ls kube
vol01
vol02
rbd children [--pool <pool>] --image <image> --snap <snap>
示例:
[root@stor01 ~]# rbd children kube/vol01@snap1
kube/vol02
[root@stor01 ~]# rbd info kube/vol02
rbd image 'vol02':
size 3 GiB in 768 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 28266268ad5df
block_name_prefix: rbd_data.28266268ad5df
format: 2
features: layering, exclusive-lock
op_features:
flags:
create_timestamp: Thu Oct 7 21:34:55 2021
access_timestamp: Thu Oct 7 21:34:55 2021
modify_timestamp: Thu Oct 7 21:34:55 2021
parent: kube/vol01@snap1 #parent快照
overlap: 3 GiB
克隆的映像会保留对父快照的引用,删除子克隆对父快照的引用(解除这种依赖关系)时,可通过将信息从快照复制到克隆,进行image的“展平”操作,使镜像成为一个独立的镜像。
展平克隆所需的时间随着映像大小的增加而延长,要删除某拥有克隆子项的快照,必须先平展其子image:
rbd flatten [--pool <pool>] --image <image> --no-progress
示例:
[root@stor01 ~]# rbd flatten kube/vol02
Image flatten: 100% complete...done.
[root@stor01 ~]# rbd info kube/vol02
rbd image 'vol02':
size 3 GiB in 768 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 28266268ad5df
block_name_prefix: rbd_data.28266268ad5df
format: 2
features: layering, exclusive-lock
op_features:
flags:
create_timestamp: Thu Oct 7 21:34:55 2021
access_timestamp: Thu Oct 7 21:34:55 2021
modify_timestamp: Thu Oct 7 21:34:55 2021 #此时,不再具有parent属性了
必须先取消保护快照,然后才能删除它。有克隆引用快照,无法解除保护。
用户无法删除克隆所引用的快照,需要先平展其每个克隆,然后才能删除快照。
rbd snap unprotect [--pool <pool>] --image <image> --snap <snap>
示例:
[root@stor01 ~]# rbd snap unprotect kube/vol01@snap1
[root@stor01 ~]# rbd snap ls kube/vol01
SNAPID NAME SIZE PROTECTED TIMESTAMP
4 snap1 3 GiB Thu Oct 7 20:44:08 2021
rbd的导入导出功能,可以实现rbd的异地备份。也可以通过这个功能实现2个ceph集群的数据迁移。
rbd的导出操作可以对镜像或镜像的快照进行,一般是对快照进行备份。
从一个qemu image镜像文件导入成rbd image。
rbd export <source-image-or-snap-spec> <path-name> #Export image to file.
rbd import [--path <path>] [--dest-pool <dest-pool>] [--dest-namespace <dest-namespace>] [--dest <dest>] <path-name> <dest-image-spec> #Import image from file.
示例:
[root@node-1 ~]# rbd export pool-demo/vm-1.img vm-1.img
Exporting image: 61% complete...
[root@node-1 ~]# ls
vm-1.img
[root@stor01 ~]# rbd import cirros-0.4.0-x86_64-disk.img kube/cirrors
Importing image: 100% complete...done.
[root@stor01 ~]# rbd ls kube -l
NAME SIZE PARENT FMT PROT LOCK
cirrors 12 MiB 2
vol01 3 GiB 2
vol01@snap1 3 GiB 2
vol02 3 GiB 2
[root@stor01 ~]# rbd resize -s 512 kube/cirrors
Resizing image: 100% complete...done.
[root@stor01 ~]# rbd ls kube -l
NAME SIZE PARENT FMT PROT LOCK
cirrors 512 MiB 2
vol01 3 GiB 2
vol01@snap1 3 GiB 2
vol02 3 GiB 2
示例:通过rbd import实现glance镜像上传至ceph
#!/bin/bash
#登录openstack
source /root/openrc
#格式转换为raw:-p显示progress
qemu-img convert -f qcow2 -O raw $1.qcow2 $1.raw -p
ls -l -h $1.raw
#生成新的UUID
export IMAGE_UUID=$(uuidgen)
echo $IMAGE_UUID
#确认glance镜像池存在
ceph osd pool ls |grep glance.images
#将镜像数据导入ceph
export IMAGE_FILE=./$1.raw
rbd -p glance.images --image-format 2 import $IMAGE_FILE $IMAGE_UUID
rbd -p glance.images snap ls $IMAGE_UUID
rbd -p glance.images snap create --snap snap $IMAGE_UUID
rbd -p glance.images snap ls $IMAGE_UUID
rbd -p glance.images snap protect --image $IMAGE_UUID --snap snap
#glance创建镜像(空镜像)
glance image-create --disk-format raw --container-format bare --visibility public --name $1 --id $IMAGE_UUID --property hw_qemu_guest_agent=yes
#镜像和镜像数据绑定:Add a location (iamge的保护快照,名称为snap) to an image.
glance location-add --url rbd://$(sudo ceph fsid)/glance.images/$IMAGE_UUID/snap $IMAGE_UUID
#删除临时文件
rm -rf ./$1.raw
#rbd export-diff <source-image-or-snap-spec> <path-name> [--from-snap arg]
#rbd import-diff
前提:客户端主机是为KVM Hypervisor主机,它运行的虚拟机的磁盘通过rbd协议使用Ceph上的rbd存储池中的image。
- 安装libvirt与qemu-kvm,并启动libvirtd守护进程;
- 安装ceph-common,并配置好与ceph集群通信的配置⽂件等。
1、创建能够认证到相关存储池上的⽤⼾账号,并给予相应的访问权限,例如以rbdpool为例:
~]$ ceph auth get-or-create client.libvirt mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow
rwx pool=rbdpool'
2、将client.libvirt⽤⼾的认证信息导⼊为libvirtd上⼀个可⽤的secret。 ⾸先,创建⼀个xml⽂件,例如ceph-client-libvirt-secret.xml ,包含如下内容,其中的“client.libvirt”为ceph的⽤⼾名,⽽secret为
<secret ephemeral='no' private='no'>
<usage type='ceph'>
<name>client.libvirt secret</name>
</usage>
</secret
⽽后,使⽤virsh命令创建此secret,命令会返回创建的secret的UUID:
~]# virsh secret-define --file ceph-client-libvirt-secret.xml Secret 7384444b-3d69-44e8-9999-1f821cd9ca8c
created
接着,将ceph的client.libvirt的密钥导⼊到刚创建的secret中:
~]# virsh secret-set-value --secret 7384444b-3d69-44e8-9999-1f821cd9ca8c --base64 $(ceph auth get-key client.libvirt)
Secret value set
3、创建空的image,或者导⼊已经的磁盘镜像内容,以运⾏基于image的KVM虚拟机;
qemu-img convert -f qcow2 -O raw /PATH/FROM/IMAGE_FILE rbd:<rpd-pool-name>/<image-name>
示例:
~]# qemu-img convert -f qcow2 -O raw cirros-0.3.4-x86_64-disk.img rbd:rbdpool/cirros-0.3.4
查看导⼊⽣成的镜像:
~]# rbd info -p rbdpool cirros-0.3.4
rbd image 'cirros-0.3.4':
size 39 MiB in 10 objects
order 22 (4 MiB objects)
id: 13896b8b4567
block_name_prefix: rbd_data.13896b8b4567
format: 2
features: layering, exclusive-lock, object-map, fastdiff, deep-flatten
op_features:
flags:
create_timestamp: Tue Mar 5 10:11:38 2019
或者创建新的空⽩image
~]# rbd create --image centos-7.6-0001 --pool rbdpool
4、创建VM
创建VM配置⽂件,⼀个接近最⼩化的配置如下所⽰,其中的disk配置段指明了要使⽤的rbd image,⽽auth配置段指明了认证到Ceph集群时使⽤的secret的UUID。
<domain type='kvm'>
<name>testvm</name>
<memory>131072</memory>
<vcpu>1</vcpu>
<os>
<type arch='x86_64'>hvm</type>
</os>
<clock sync="localtime"/>
<devices>
<emulator>/usr/libexec/qemu-kvm</emulator>
<disk type='network' device='disk'>
<source protocol='rbd' name='rbdpool/cirros-0.3.4'>
<host name='mon01' port='6789'/>
</source>
<auth username='libvirt'>
<secret type='ceph' uuid='7384444b-3d69-44e8-9999-1f821cd9ca8c'/>
</auth>
<target dev='vda' bus='virtio'/>
</disk>
<interface type='network'>
<mac address='52:54:00:25:a1:80'/>
<source network='default'/>
<model type='virtio'/>
</interface>
<graphics type='vnc' port='-1' keymap='de'/>
</devices>
</domain>
附带console和监听于对外通信地址上的vnc图形界⾯的配置⽰例如下:
<domain type='kvm'>
<name>testvm</name>
<memory>131072</memory>
<currentMemory unit='KiB'>65536</currentMemory>
<vcpu>1</vcpu>
<os>
<type arch='x86_64'>hvm</type>
</os>
<clock sync="localtime"/>
<devices>
<emulator>/usr/libexec/qemu-kvm</emulator>
<disk type='network' device='disk'>
<source protocol='rbd' name='rbdpool/cirros-0.3.4'>
<host name='mon01' port='6789'/>
</source>
<auth username='libvirt'>
<secret type='ceph' uuid='7384444b-3d69-44e8-9999-1f821cd9ca8c'/>
</auth>
<target dev='vda' bus='virtio'/>
</disk>
<interface type='network'>
<mac address='52:54:00:25:a1:80'/>
<source network='default'/>
<model type='virtio'/>
</interface>
<serial type='pty'>
<target type='isa-serial' port='0'>
<model name='isa-serial'/>
</target>
</serial>
<console type='pty'>
<target type='virtio' port='0'/>
</console>
<graphics type='vnc' port='-1' autoport='yes'>
<listen type='address' address='0.0.0.0'/>
</graphics>
</devices>
</domain>
将上述⽰例内容任意⼀个保存为xml⽂件后即可以之创建VM。例如,将第⼆个保存为testvm.xml,并使⽤如下命令完成VM创建:
~]# virsh define testvm.xml ~]# virsh start testvm
查看虚拟机的磁盘设备状态:
~]# virsh domblklist testvm
Target Source
------------------------------------------------
vda rbdpool/cirros-0.3.4
转载:http://xuxiaopang.com/2016/10/13/easy-ceph-RBD/
众所周知,RBD有两种格式:
Format 1:Hammer以及Hammer之前默认都是这种格式,并且rbd_default_features = 3.Format 2:Jewel默认是这种格式,并且rbd_default_features = 61.
试验环境:首先安装一个Hammer版本的环境
创建一个1G的块foo,因为是Hammer默认是format 1的块,具体和format 2的区别会在下文讲到:
[root@ceph cluster]# ceph -s
cluster fc44cf62-53e3-4982-9b87-9d3b27119508
health HEALTH_OK
monmap e1: 1 mons at {ceph=233.233.233.233:6789/0}
election epoch 2, quorum 0 ceph
osdmap e5: 1 osds: 1 up, 1 in
pgmap v7: 64 pgs, 1 pools, 0 bytes data, 0 objects
7135 MB used, 30988 MB / 40188 MB avail
64 active+clean
[root@ceph cluster]# rbd create foo --size 1024
[root@ceph cluster]# rbd info foo
rbd image 'foo':
size 1024 MB in 256 objects
order 22 (4096 KB objects)
block_name_prefix: rb.0.1014.74b0dc51
format: 1
[root@ceph cluster]# ceph -s
...
pgmap v10: 64 pgs, 1 pools, 131 bytes data, 2 objects
7136 MB used, 30988 MB / 40188 MB avail
64 active+clean
Tips :
rbd的指令如果省略-p / --pool参数,则会默认-p rbd,而这个rbd pool是默认生成的。
对刚刚的rbd info的几行输出简单介绍下:
size 1024 MB in 256 objects
order 22 (4096 KB objects)
block_name_prefix: rb.0.1014.74b0dc51
format: 1
size: 就是这个块的大小,即1024MB=1G,1024MB/256 = 4M,共分成了256个对象(object),每个对象4M,这个会在下面详细介绍。order 22, 22是个编号,4M是22, 8M是23,也就是2^22 bytes = 4MB, 2^23 bytes = 8MB。block_name_prefix: 这个是块的最重要的属性了,这是每个块在ceph中的唯一前缀编号,有了这个前缀,把服务器上的OSD都拔下来带回家,就能复活所有的VM了。format: 格式有两种,1和2,下文会讲。
观察建foo前后的ceph -s输出,会发现多了两个文件,查看下:
pgmap v10: 64 pgs, 1 pools, 131 bytes data, 2 objects
[root@ceph cluster]# rados -p rbd ls
foo.rbd
rbd_directory
再查看这两个文件里面的内容:
[root@ceph ~]# rados -p rbd get foo.rbd foo.rbd
[root@ceph ~]# rados -p rbd get rbd_directory rbd_directory
[root@ceph ~]# hexdump -vC foo.rbd
00000000 3c 3c 3c 20 52 61 64 6f 73 20 42 6c 6f 63 6b 20 |<<< Rados Block |
00000010 44 65 76 69 63 65 20 49 6d 61 67 65 20 3e 3e 3e |Device Image >>>|
00000020 0a 00 00 00 00 00 00 00 72 62 2e 30 2e 31 30 31 |........rb.0.101|
00000030 34 2e 37 34 62 30 64 63 35 31 00 00 00 00 00 00 |4.74b0dc51......|
00000040 52 42 44 00 30 30 31 2e 30 30 35 00 16 00 00 00 |RBD.001.005.....|
root@ceph ~]# hexdump -vC rbd_directory
00000000 00 00 00 00 01 00 00 00 03 00 00 00 66 6f 6f 00 |............foo.|
这时候我们再创建一个RBD叫bar,再次对比查看:
[root@ceph ~]# rbd create bar --size 1024
[root@ceph ~]# rados -p rbd ls
bar.rbd
foo.rbd
rbd_directory
[root@ceph ~]# rados -p rbd get rbd_directory rbd_directory
[root@ceph ~]# hexdump -vC rbd_directory
00000000 00 00 00 00 02 00 00 00 03 00 00 00 62 61 72 00 |............bar.|
00000010 00 00 00 03 00 00 00 66 6f 6f 00 00 00 00 |.......foo....|
多出了个bar.rbd文件,很容易联想到这个文件的内容是和foo.rbd内容类似的,唯一不同的是保存了各自的block_name_prefix。然后,rbd_directory里面多出了bar这个块名字。可以得出以下的推论:
每个块(RBD)刚创建(format 1)时都会生成一个rbdName.rbd这样的文件(ceph里的对象),里面保存了这个块的prefix。
同时,rbd_directory会增加刚刚的创建的rbdName,顾名思义这个文件就是这个pool里面的所有RBD的索引。
为了简单试验,删掉刚刚的bar只留下foo:
[root@ceph ~]# rbd rm bar
Removing image: 100% complete...done.
建好了块,我们就开始使用这个块了:
[root@ceph ~]# rbd map foo
/dev/rbd0
[root@ceph ~]# mkfs.xfs /dev/rbd0
meta-data=/dev/rbd0 isize=256 agcount=9, agsize=31744 blks
= sectsz=512 attr=2, projid32bit=1
= crc=0 finobt=0
data = bsize=4096 blocks=262144, imaxpct=25
= sunit=1024 swidth=1024 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=0
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@ceph ~]# mkdir /foo
[root@ceph ~]# mount /dev/rbd0 /foo/
[root@ceph ~]# df -h
文件系统 容量 已用 可用 已用% 挂载点
/dev/vda1 40G 7.0G 31G 19% /
...
/dev/rbd0 1014M 33M 982M 4% /foo
我喜欢记点东西,比如上面的33M就是刚格式化完的xfs系统的大小,算是一个特点吧。
先别急着用,集群发生了点变化,观察下:
[root@ceph ~]# ceph -s
pgmap v44: 64 pgs, 1 pools, 14624 KB data, 15 objects
[root@ceph ~]# rados -p rbd ls |sort
foo.rbd
rb.0.1014.74b0dc51.000000000000
rb.0.1014.74b0dc51.000000000001
rb.0.1014.74b0dc51.00000000001f
rb.0.1014.74b0dc51.00000000003e
rb.0.1014.74b0dc51.00000000005d
rb.0.1014.74b0dc51.00000000007c
rb.0.1014.74b0dc51.00000000007d
rb.0.1014.74b0dc51.00000000007e
rb.0.1014.74b0dc51.00000000009b
rb.0.1014.74b0dc51.0000000000ba
rb.0.1014.74b0dc51.0000000000d9
rb.0.1014.74b0dc51.0000000000f8
rb.0.1014.74b0dc51.0000000000ff
rbd_directory
比刚刚多了13个文件,而且特别整齐还!观察这些文件的后缀,可以发现,后缀是以16进制进行编码的,那么从0x00 -> 0xff是多大呢,就是十进制的256,这个数字是不是很眼熟:
size 1024 MB in 256 objects
可是这里只有13个文件,并没有256个啊,这就是RBD的精简置备的一个验证,刚刚创建foo的时候,一个都没有呢,而这里多出的13个,是因为刚刚格式化成xfs时生成的。我们着重关注索引值为0x00 & 0x01这两个碎片文件(Ceph Object):
[root@ceph ~]# rados -p rbd get rb.0.1014.74b0dc51.000000000000 rb.0.1014.74b0dc51.000000000000
[root@ceph ~]# rados -p rbd get rb.0.1014.74b0dc51.000000000001 rb.0.1014.74b0dc51.000000000001
[root@ceph ~]# hexdump -vC rb.0.1014.74b0dc51.000000000000|more
00000000 58 46 53 42 00 00 10 00 00 00 00 00 00 04 00 00 |XFSB............|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 c5 79 ca f7 fc 5d 48 2d 81 5e 4c 75 29 3c 90 d3 |.y...]H-.^Lu)<..|
...
[root@ceph ~]# ll rb.* -h
-rw-r--r-- 1 root root 128K 10月 12 19:10 rb.0.1014.74b0dc51.000000000000
-rw-r--r-- 1 root root 16K 10月 12 19:10 rb.0.1014.74b0dc51.000000000001
[root@ceph ~]# file rb.0.1014.74b0dc51.000000000000
rb.0.1014.74b0dc51.000000000000: SGI XFS filesystem data (blksz 4096, inosz 256, v2 dirs)
[root@ceph ~]# rbd export foo hahahaha
Exporting image: 100% complete...done.
[root@ceph ~]# file hahahaha
hahahaha: SGI XFS filesystem data (blksz 4096, inosz 256, v2 dirs)
[root@ceph ~]# hexdump -vC rb.0.1014.74b0dc51.000000000001
00000000 49 4e 41 ed 02 01 00 00 00 00 00 00 00 00 00 00 |INA.............|
00000010 00 00 00 02 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 57 fe 15 be 0b cb a3 58 |........W......X|
00000030 57 fe 15 be 0b cb a3 58 00 00 00 00 00 00 00 06 |W......X........|
00000040 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
...............太长了自己看~
[root@ceph ~]# hexdump -vC rb.0.1014.74b0dc51.000000000001|grep IN |wc -l
64
这里的每一行输出都是很值得思考的,首先我们导出刚刚提到的两个对象,查看第一个对象,开头就是XFSB,可以验证这是刚刚mkfs.xfs留下来的,这时候查看文件大小,发现并没有4M那么大,别担心一会会变大的,值得关注的是file第0x00个对象,输出居然是XFS filesystem data,进一步验证了刚刚mkfs.xfs的足迹,这和整个块的file信息是一样的,我猜测xfs把文件系统核心信息就保存在块设备的最最前面的128KB。而后面的第0x01个对象里面的IN输出是64,我不负责任得猜想这个可能是传说中的inode。抛去猜想这里给到的结论是:
在使用块设备的容量后,会按需生成对应的对象,这些对象的共同点是:命名遵循 block_name_prefix+index, index range from [0x00, 0xff],而这个区间的大小正好是所有对象数的总和。
现在让我们把foo塞满:
[root@ceph ~]# dd if=/dev/zero of=/foo/full-me
dd: 正在写入"/foo/full-me": 设备上没有空间
记录了2010449+0 的读入
记录了2010448+0 的写出
1029349376字节(1.0 GB)已复制,37.9477 秒,27.1 MB/秒
[root@ceph ~]# ceph -s
pgmap v81: 64 pgs, 1 pools, 994 MB data, 258 objects
10500 MB used, 27623 MB / 40188 MB avail
这里写了将近1G的数据,重点在后面的258 objects,如果理解了前面说的内容,这258个对象自然是由rbd_directoy和foo.rbd还有256个prefix+index对象构成的,因为我们用完了这个块的所有容量,所以自然就生成了所有的256的小4M对象。
试验环境:首先安装一个Jewel版本的环境(或者改配置项),方法很简单:
[root@ceph install-ceph-in-one-minute]# cd /root/install-ceph-in-one-minute/
[root@ceph install-ceph-in-one-minute]# ./cleanup.sh
kill: 向 945 发送信号失败: 没有那个进程
root 955 943 0 13:18 pts/4 00:00:00 grep ceph
root 20960 2 0 10月11 ? 00:00:00 [ceph-msgr]
root 22052 2 0 10月12 ? 00:00:00 [ceph-watch-noti]
umount: /var/lib/ceph/osd/ceph-0:未挂载
[root@ceph install-ceph-in-one-minute]# sed -i 's/hammer/jewel/g' install.sh
[root@ceph install-ceph-in-one-minute]# ./install.sh
...
[root@ceph ~]# ceph -s
cluster 04949396-488c-4244-a141-b2ae6de3ed38
health HEALTH_OK
monmap e1: 1 mons at {ceph=233.233.233.233:6789/0}
election epoch 3, quorum 0 ceph
osdmap e5: 1 osds: 1 up, 1 in
flags sortbitwise
pgmap v15: 64 pgs, 1 pools, 0 bytes data, 0 objects
7234 MB used, 30889 MB / 40188 MB avail
64 active+clean
[root@ceph ~]# ceph -v
ceph version 10.2.3 (ecc23778eb545d8dd55e2e4735b53cc93f92e65b)
创建一个foo块,并观察集群多出了哪些文件:
[root@ceph ~]# rbd create foo --size 1024
[root@ceph ~]# rbd info foo
rbd image 'foo':
size 1024 MB in 256 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.101474b0dc51
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
flags:
[root@ceph ~]# rados -p rbd ls
rbd_object_map.101474b0dc51
rbd_header.101474b0dc51
rbd_id.foo
rbd_directory
[root@ceph ~]# rbd map foo
rbd: sysfs write failed
RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable".
In some cases useful info is found in syslog - try "dmesg | tail" or so.
rbd: map failed: (6) No such device or address
[root@ceph ~]# rbd feature disable foo deep-flatten
[root@ceph ~]# rbd feature disable foo fast-diff
[root@ceph ~]# rbd feature disable foo object-map
[root@ceph ~]# rbd feature disable foo exclusice-lock
[root@ceph ~]# rbd map foo
/dev/rbd1
[root@ceph ~]# rados -p rbd ls
rbd_header.101474b0dc51
rbd_id.foo
rbd_directory
多出了四个文件,在关闭object-map属性后,少了一个rbd_object_map.101474b0dc51文件,我们查看剩下的三个文件内容:
[root@ceph ~]# rados -p rbd get rbd_header.101474b0dc51 rbd_header.101474b0dc51
[root@ceph ~]# rados -p rbd get rbd_id.foo rbd_id.foo
[root@ceph ~]# rados -p rbd get rbd_directory rbd_directory
[root@ceph ~]# hexdump -Cv rbd_directory
[root@ceph ~]# hexdump -Cv rbd_header.101474b0dc51
[root@ceph ~]# hexdump -Cv rbd_id.foo
00000000 0c 00 00 00 31 30 31 34 37 34 62 30 64 63 35 31 |....101474b0dc51|
00000010
可以发现,rbd_directory不再保存所有RBD的名称,相比于format1的 foo.rbd,format2采用rbd_id.rbdName的形式保存了这个块的prefix,而另一个文件rbd_header,xxxxxxxxprefix显示的保存了这个prefix,我们再向这个块写入点文件:
[root@ceph ~]# mkfs.xfs /dev/rbd1
[root@ceph ~]# ceph -s
pgmap v187: 64 pgs, 1 pools, 14624 kB data, 16 objects
[root@ceph ~]# rados -p rbd ls|sort
rbd_data.101474b0dc51.0000000000000000
rbd_data.101474b0dc51.0000000000000001
rbd_data.101474b0dc51.000000000000001f
rbd_data.101474b0dc51.000000000000003e
rbd_data.101474b0dc51.000000000000005d
rbd_data.101474b0dc51.000000000000007c
rbd_data.101474b0dc51.000000000000007d
rbd_data.101474b0dc51.000000000000007e
rbd_data.101474b0dc51.000000000000009b
rbd_data.101474b0dc51.00000000000000ba
rbd_data.101474b0dc51.00000000000000d9
rbd_data.101474b0dc51.00000000000000f8
rbd_data.101474b0dc51.00000000000000ff
rbd_directory
rbd_header.101474b0dc51
rbd_id.foo
可以发现,生成的13个小4M文件的后缀和format 1的是一模一样的,只是命名规则变成了rbd_data.[prefix].+[index],之所以后缀是一样的是因为xfs对于1G的块总是会这样构建文件系统,所以对于F1 & F2,这些小4M除了命名规范不一样外,实际保存的内容都是一样的。
下面对这两种格式进行简要的对比总结:
| 格式 | rbd_diretory | ID | prefix | Data |
|---|---|---|---|---|
| Format 1 | 保存了所有RBD的名称 | foo.rbd | 在ID中 | 形如 rb.0.1014.74b0dc51.000000000001 |
| Format 2 | 空 | rbd_id.foo | 在ID中 并rbd_header.prefix显示输出 | 形如 rbd_data.101474b0dc51.0000000000000001 |