06 Ceph Fs
索引式文件系统将底层存储数据的磁盘空间切分为“块”,并为每个文件对象所占 用所有块建立一个索引表进行统一存放在一个称为“元数据区”的空间中
- 索引表就是块地址数组,每个数组元素就是块的地址,于是,一个文件对象的块可以分 散存储到离散块空间中
- 索引表的索引结构称为inode,用于索引、跟踪一个文件对象的权限、隶属关系、时间戳 和占据的所有的块等属性信息,不过却不包括文件名和文件内容本身
文件名及其隶属的目录层级关系通过Dentry进行描述
- 每个Dentry就像一个映射表,它保存了本级目录或者文件名以及紧邻的下一级目录或者文件的名称与各自inode的映射关系;而Dentry自身也需要由专用的inode对象承载,它也拥有自己的inode,于是这种映射便可 组织出多级别层次来,这个多级别的层次起始于一个惟一的称之为“根”的起始点,从 而形成一个树状组织结构
CephFS用于为RADOS存储集群提供一个POSIX兼容的文件系统接口:
- 基于RADOS存储集群将数据与元数据IO进行解耦
- 动态探测和迁移元数据负载到其它MDS,实现了对元数据IO的扩展
- 第一个稳定版随Jewel版本释出
- 自Luminous版本起支持多活MDS(Multiple Active MDS)
特性:
- 目录分片
- 动态子树分区和子树绑定(静态子树分区)
- 支持内核及FUSE客户端
- 其它尚未稳定特性还包括内联数据(INLINE DATA)、快照和多文件系统等
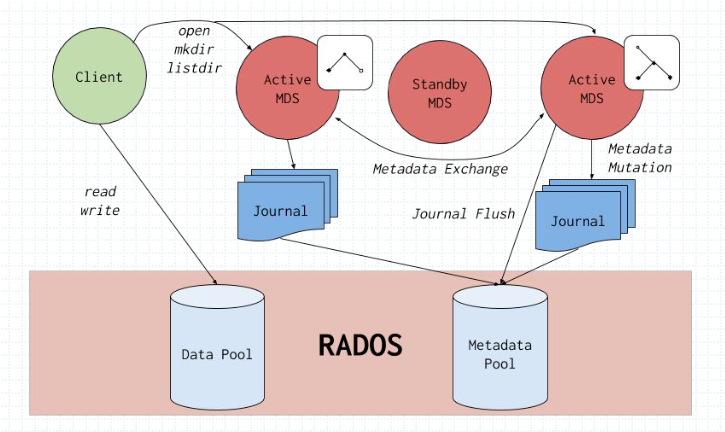
MDS自身并不会直接存储任何数据,所有的数据均由后端的RADOS集群负责存储,包括元数据,MDS本身更像是一个支持读写的索引服务。
CephFS依赖于专用的MDS(MetaData Server)组件管理元数据信息并向客户端输出一个倒置的树状层级结构。
- 将元数据缓存于MDS的内存中
- 把元数据的更新日志于流式化后存储在RADOS集群上
- 将层级结构中的的每个名称空间对应地实例化成一个目录且存储为一个专有的RADOS对象
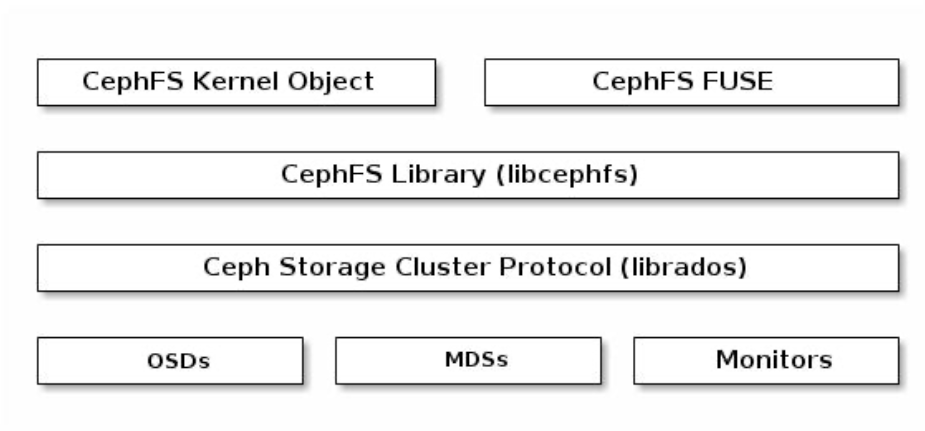
CephFS库(libcephfs )工作在 librados 之上,并代表Ceph文件系统。最上层代表两种可以访问 Ceph 文件系统的客户端。
默认情况下,该软件包已经在集群搭建时已经安装,如果未安装,可以使用如下命令进行安装。
[cephadm@node-1 ceph-cluster]$ ceph-deploy install --mds --no-adjust-repos node-2
[cephadm@node-1 ceph-cluster]$ ceph-deploy mds create node-1ll
主要完成keyring的生成和ceph-mds的启动操作。
[cephadm@node-1 ceph-cluster]$ ceph -s
cluster:
id: 9ebc9b51-1406-43cc-bdd2-d560e58d842f
health: HEALTH_WARN
application not enabled on 2 pool(s)
services:
mon: 3 daemons, quorum node-1,node-2,node-3 (age 41h)
mgr: node-1(active, since 43h), standbys: node-2
mds: 1 up:standby #启动一个mds,处于standby状态(因为目前没有文件系统)
osd: 6 osds: 6 up (since 43h), 6 in (since 43h)
rgw: 1 daemon active (node-1)
task status:
data:
pools: 7 pools, 416 pgs
objects: 292 objects, 184 MiB
usage: 6.8 GiB used, 1.2 TiB / 1.2 TiB avail
pgs: 416 active+clean
部署另外2个实例
[cephadm@node-1 ceph-cluster]$ ceph-deploy --overwrite-conf mds create node-2 node-3
[cephadm@node-1 ceph-cluster]$ ceph -s
cluster:
id: 9ebc9b51-1406-43cc-bdd2-d560e58d842f
health: HEALTH_WARN
application not enabled on 2 pool(s)
services:
mon: 3 daemons, quorum node-1,node-2,node-3 (age 42h)
mgr: node-1(active, since 43h), standbys: node-2
mds: 3 up:standby
osd: 6 osds: 6 up (since 43h), 6 in (since 43h)
rgw: 1 daemon active (node-1)
task status:
data:
pools: 7 pools, 416 pgs
objects: 292 objects, 184 MiB
usage: 6.8 GiB used, 1.2 TiB / 1.2 TiB avail
pgs: 416 active+clean
至少有1个节点运行ceph-mds守护进程。
CephFS分别将元数据和数据放置于不同的存储池中,而且通常应该配置它们各自使用专用的存储池,例如cephfs-metadata和cephfs-data
ceph osd pool create cephfs-metadata 32
ceph osd pool create cephfs-data 64
创建CephFS
ceph fs new <fs-name> <metadata-pool> <data-pool>
示例:
#以cephfs-metadata为元数据池,以cephfs-data为数据池:
ceph fs new cephfs cephfs-metadata cephfs-data
CephFS状态查看
ceph mds stat #查看文件系统信息
ceph fs status <fs-name>
ceph fs get <fs-name>
示例:
[root@stor01 ~]# ceph mds stat
cephfs:1 {0=stor01=up:active} #cephfs为文件系统名称,1位文件系统ID;0表示rank编号,即守护进程ID为stor01这个mds守护进程获取的rank为0,其处于up状态,而且是active角色。
[root@stor01 ~]# ceph fs status cephfs
cephfs - 0 clients
======
+------+--------+--------+---------------+-------+-------+
| Rank | State | MDS | Activity | dns | inos |
+------+--------+--------+---------------+-------+-------+
| 0 | active | stor01 | Reqs: 0 /s | 10 | 13 |
+------+--------+--------+---------------+-------+-------+
+-----------------+----------+-------+-------+
| Pool | type | used | avail |
+-----------------+----------+-------+-------+
| cephfs-metadata | metadata | 112k | 249G |
| cephfs-data | data | 0 | 249G |
+-----------------+----------+-------+-------+
+-------------+
| Standby MDS |
+-------------+
+-------------+
MDS version: ceph version 14.2.22 (ca74598065096e6fcbd8433c8779a2be0c889351) nautilus (stable)
启用CephX认证的集群上,CephFS的客户端完成认证后方可挂载访问文件系统。
1、创建专用客户端账号,以client.fsclient为例:
ceph auth get-or-create client.fsclient mon 'allow r' mds 'allow rw' \
osd 'allow rw pool=cephfs-data' -o /etc/ceph/ceph.client.fsclient.keyring
[root@stor01 ~]# cat /etc/ceph/ceph.client.fsclient.keyring
[client.fsclient]
key = AQCPVWJh2cKYAxAArbapH+4UHMfOTiVYauhxAQ==
[root@stor01 ~]# ceph auth get client.fsclient
[client.fsclient]
key = AQCPVWJh2cKYAxAArbapH+4UHMfOTiVYauhxAQ==
caps mds = "allow rw"
caps mon = "allow r"
caps osd = "allow rw pool=cephfs-data"
注意:元数据池仅可由MDS访问,无须授权给客户端账号;另外,数据池上的权限指定应根据实际需要进行;
2、保存用户账号的密钥信息于secret文件,用于客户端挂载操作认证之用
ceph-authtool -p -n client.fsclient /etc/ceph/ceph.client.fsclient.keyring > fsclient.key #从keyring文件中打印指定用户的key,等同于ceph auth print-key client.fsclient >fsclient.key
[root@stor01 ~]# cat fsclient.key
AQCPVWJh2cKYAxAArbapH+4UHMfOTiVYauhxAQ==
3、此密钥文件需要保存于挂载CephFS的客户端主机上,以server01为例
scp ceph.conf fsclient.key root@server01:/etc/ceph/ #使用内核客户端时,使用ceph.conf和key文件
scp ceph.conf ceph.client.fsclient.keyring root@server01:/etc/ceph/ #使用FUSE客户端时,使用ceph.conf和keyring文件
1、客户端主机环境准备:
- 内核模块ceph.ko(内核版本3.x以上):
modinfo ceph - 安装ceph-common程序包
- 提供ceph.conf配置文件
- 获取到用于认证的密钥文件,例如fsclient.key
内核客户端在Cephfs认证时,用户名和key信息是分离的,用户名在参数中指定,key文件中只存储key字符串,不存储用户名信息。
2、挂载CephFS:
mount -t ceph <MON1:Port>[,<MON2:Port>,<MON3:Port>]:/ mount_point -o name=USERNAME,secretfile=/PATH/TO/USER-SECRET-KEY
说明:
-o name=client.user,secretfile=/PATH/TO/USER-SECRET-KEY,也可以这样使用:-o name=client.user,secret=`ceph auth print-key client.user`
64.115.3.101:6789:/ 可以指定多个monitor地址,例如64.115.3.101:6789,64.115.3.102:6789,64.115.3.103:6789:/ 但是,指定一个也是可以自动获取其他的monitor地址。这是因为client启动之初,它即获取到了集群的 monmap, 而当所连接 MON 的 IP 变化时,比如这个 MON 挂掉时,它便会尝试连接 monmap 里面的其他 IP 的 MON,如果每个MON都挂了,那么这个 Client 就不能连接上集群获取最新的 monmap,osdmap等。
3、查看挂载状态:
stat -f mount_point
4、存入/etc/fstab文件,实现自动挂载:
<MON1:Port>[,<MON2:Port>,<MON3:Port>]:/ /data ceph name=fsclient,secretfile=/etc/ceph/fsclient.key,_netdev,noatime 0 0
FUSE,全称Filesystem in Userspace,用于非特权用户能够无需操作内核而创建文件系统。但性能会比内核客户端差。
1、客户端主机环境准备:
- 安装ceph-fuse程序包
- 获取到客户端账号的keyring文件和ceph.conf配置文件
2、挂载CephFS:
ceph-fuse [-n client.username] [-m mon-ip-addr:mon-port] <mount-point> [OPTIONS] [--client_mountpoint/ -r <sub_directory>]
ceph-fuse默认会把整个文件系统的根目录挂载到挂载点,可以使用
--client_mountpoint/-r <sub_directory>参数把文件系统的子目录挂载到挂载点。
示例:
ceph-fuse -n client.fsclient -m mon01:6789,mon02:6789,mon03:6789 /mnt/cephfs/ #会根据用户名自动查找keyring文件
3、写入/etc/fstab,实现自动挂载
#DEVICE PATH TYPE OPTIONS
none <mount-point> fuse.ceph ceph.id=<user-id>[,ceph.conf=<path>], _netdev,defaults 0 0
示例:
none /data fuse.ceph ceph.id=fsclient,ceph.conf=/etc/ceph.conf,_netdev,defaults 0 0
卸载:
fusemount -u <mount_point>
或 umount <mount_point>
文件元数据的工作负载通常是一类小而密集的IO请求,因此很难实现类似数据读写IO那样的扩展方式。
分布式文件系统业界提供了将名称空间分割治理的解决方案,通过将文件系统根树及其热点子树分别部署于不同的元数据服务器进行负载均衡,从而赋予了元数据存 储线性扩展的可能。
- 静态子树分区:静态指定,例如某个子目录作为挂载点,挂载其他的磁盘或网络文件系统
- 静态hash分区
- 惰性混编分区
- 动态子树分区:ceph使用的方式
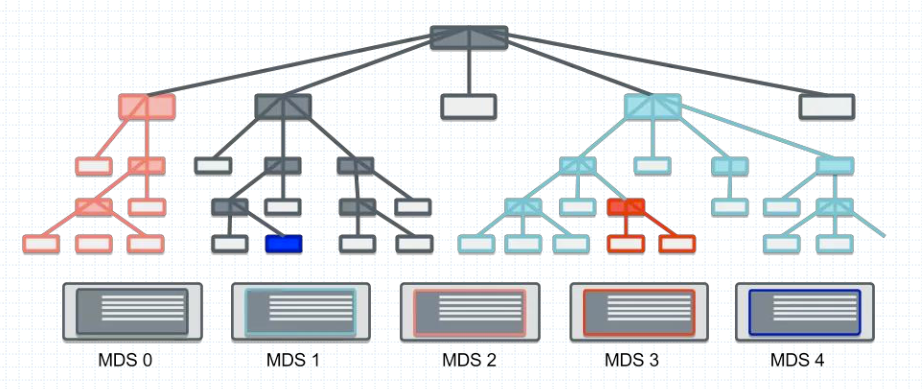
为了减轻一个ACTIVE MDS的工作负载,可以将目录树的每个子节点由一个单独的MDS来负载响应,这种方式就是多活MDS。此外还需要使用Active+Standby模式实现MDS的HA。
多主MDS(多活MDS)模式是指CephFS将整个文件系统的名称空间切分为多个子树并配置到多个MDS之上,不过,读写操作的负载均衡策略是不同的,分别是子树切分和目录副本。
- 子树切分:将写操作负载较重的目录切分成多个子目录以分散负载
- 目录副本:为读操作负载较重的目录创建多个副本以均衡负载
子树分区和迁移的决策是一个同步过程,各MDS每10秒钟做一次独立的迁移决策 ,每个MDS并不存在一个一致的名称空间视图,且MDS集群也不存在一个全局调 度器负责统一的调度决策。各MDS彼此间通过交换心跳信息(HeartBeat,简称HB)及负载状态来确定是否要进行迁移、如何分区名称空间,以及是否需要目录切分为子树等。管理员也可以配置CephFS负载的计算方式从而影响MDS的负载决策,目前,CephFS支持基于CPU负载、文件系统负载及混合此两种的决策机制。
动态子树分区依赖于共享存储完成热点负载在MDS间的迁移,于是Ceph把MDS的元数据存储于后面的RADOS集群上的专用存储池中,此存储池可由多个MDS共享。MDS对元数据的访问并不直接基于RADOS进行,而是为其提供了一个基于内存的缓存区以缓存热点元数据,并且在元数据相关日志条目过期之前将一直存储 于内存中。
CephFS使用元数据日志来解决容错问题;元数据日志信息流式存储于CephFS元数据存储池中的元数据日志文件上,类似于LFS(Log-Structured File System)和WAFL( Write Anywhere File Layout)的工作机制,CephFS元数据日志文件的体积可以无限增长以确保日志信息能顺序写入RADOS,并额外赋予守护进程修剪冗余或不相关日志条目的能力。
多活MDS中,每个CephFS都会有一个易读的文件系统名称和一个称为FSCID标识符ID,并且每个CephFS默认情况下都只配置一个Active MDS守护进程。
一个MDS集群中可处于Active状态的MDS数量的上限由max_mds参数配置,它控制着可用的rank数量,默认值为1。如果守护进程数>max_mds,则多出来的守护进程则处于Standby状态:
rank是指CephFS上可同时处于Active状态的MDS守护进程的可用编号,其范围从0到max_mds-1
一个rank编号意味着一个可承载CephFS层级文件系统目录子树元数据管理功能的Active状态的ceph-mds守护进程的编号,max_mds的值为1时意味着仅有一个0号rank可用;
刚启动的ceph-mds守护进程没有接管任何rank,它随后由MON按需进行分配;
一个ceph-mds一次仅可占据一个rank,并且在守护进程终止时将其释放;
一个rank可以处于下列三种状态中的某一种:
- Up:rank已经由某个ceph-mds守护进程接管
- Failed:rank未被任何ceph-mds守护进程接管
- Damaged:rank处于损坏状态,其元数据处于崩溃或丢失状态;在管理员修复问题并对其运行 “ceph mds repaired”命令之前,处于Damaged状态的rank不能分配给其它任何MDS守护进程
ceph fs set <fsname> max_mds <number>
仅当存在某个备用守护进程可供新的rank使用时,文件系统中的实际rank数才会增加;
多活MDS的场景依然要求存在备用的冗余主机以实现服务HA,因此max_mds的值总是应该比实际可用的MDS数量至少小1;如果守护进程数>max_mds,则多出来的守护进程则处于Standby状态
减小max_mds的值仅会限制新的rank的创建,对于已经存在的Active MDS及持有的rank 不造成真正的影响,因此降低max_mds的值后,管理员需要手动关闭不再不再被需要的rank;
ceph mds deactivate {System:rank|FSID:rank|rank}
ceph status <fsname>
多Active MDS的CephFS集群上会运行一个均衡器用于调度元数据负载。这种模式通常足以满足大多数用户的需求。个别场景中,用户需要使用元数据到特定级别的显式映射来覆盖动态平衡器,以在整个集群上自定义分配应用负载。针对此目的提供的机制称为“导出关联”,它是目录的扩展属性ceph.dir.pin。
目录属性设置命令:setfattr -n ceph.dir.pin -v RANK /PATH/TO/DIR
扩展属性的值 ( -v ) 是要将目录子树指定到的rank
默认为-1,表示不关联该目录
目录“导出关联”继承自设置了导出关联的最近的父级,因此,对某个目录设置导出关联会影响该目录的所有子级目录
出于冗余的目的,每个CephFS上都应该配置一定数量Standby状态的ceph-mds守 护进程等着接替失效的rank,CephFS提供了四个选项用于控制Standby状态的MDS守护进程如何工作:
- mds_standby_replay:布尔型值,true表示当前MDS守护进程将持续读取某个特定的Up状态的rank的元数据日志,从而持有相关rank的元数据缓存,并在此rank失效时加速故障切换(可以理解为是在线stangby);
- 一个Up状态的rank仅能拥有一个replay守护进程,多出的会被自动降级为正常的非replay型MDS
- mds_standby_for_name:设置当前MDS进程仅备用于指定mds守护进程名称的rank;
- mds_standby_for_rank:设置当前MDS进程仅备用于指定的rank,它不会接替任何其它失效的rank;不过,在有着多个CephFS的场景中,可联合使用下面的参数mds_standby_for_fscid来指定为哪个文件系统的rank进行冗余(跨文件系统冗余);
- mds_standby_for_fscid:联合mds_standby_for_rank参数的值协同生效;
- 同时设置了mds_standby_for_rank:备用于指定fscid的指定rank;
- 未设置mds_standby_for_rank时:备用于指定fscid的任意rank;
MDS的配置段:
[mds.stor01]
mds_standby_for_fscid = cephfs
[mds.stor02]
mds_standby_for_name = stor03
mds_standby_replay = true