Mariadb Galera集群drbd主备容灾测试
主、备中心各部署一套MariaDB Galera集群。
root@master01:~# kubectl get pvc -A |grep mysql-data-mariadb-server
common mysql-data-mariadb-server-0 Bound pvc-b20feb26-b413-426f-b5cb-710e76e40b84 150Gi RWO hostpath-provisioner 8d
common mysql-data-mariadb-server-1 Bound pvc-48e35e45-c9fe-4e10-9cad-1db6d7adae15 150Gi RWO hostpath-provisioner 8d
common mysql-data-mariadb-server-2 Bound pvc-4219647e-19e1-4683-949c-b7f166391a6c 150Gi RWO hostpath-provisioner 8d
root@master01:~# kubectl get pod -owide -A |grep mariadb-server
common mariadb-server-0 1/1 Running 0 8d 100.101.102.13 <none> worker13 <none> <none>
common mariadb-server-1 1/1 Running 0 8d 100.101.80.13 <none> worker14 <none> <none>
common mariadb-server-2 1/1 Running 0 8d 100.101.209.12 <none> worker12 <none> <none>
依据下表形成drbd的配置文件:
| Pod | 主中心节点 | Pvc |
|---|---|---|
| mariadb-server-0 | worker13(172.16.1.13) | pvc-b20feb26-b413-426f-b5cb-710e76e40b84 |
| mariadb-server-1 | worker14(172.16.1.14) | pvc-48e35e45-c9fe-4e10-9cad-1db6d7adae15 |
| mariadb-server-2 | worker12(172.16.1.12) | pvc-4219647e-19e1-4683-949c-b7f166391a6c |
1、helm删除
root@master01:~/ysxt-cnp/mariadb# helm uninstall common-mariadb -n common
root@master01:~/ysxt-cnp/mariadb# kubectl get pod -A |grep mariadb
common mariadb-server-1 0/1 Terminating 0 8d
common mariadb-server-2 0/1 Terminating 0 8d
root@master01:~/ysxt-cnp/mariadb# kubectl get pod -A |grep mariadb
2、删除pvc
root@master01:~/ysxt-cnp/mariadb# kubectl get pvc -n common |grep mariadb-server
mysql-data-mariadb-server-0 Bound pvc-cca07566-4041-4d24-b4a7-1de675b6663b 150Gi RWO hostpath-provisioner 8d
mysql-data-mariadb-server-1 Bound pvc-dfce9589-8ff0-427b-a0cd-60ecf62dd9e1 150Gi RWO hostpath-provisioner 8d
mysql-data-mariadb-server-2 Bound pvc-82518c1b-18f7-4832-ab0b-37cd3e21b6c6 150Gi RWO hostpath-provisioner 8d
root@master01:~/ysxt-cnp/mariadb# kubectl delete pvc -n common mysql-data-mariadb-server-0 mysql-data-mariadb-server-1 mysql-data-mariadb-server-2
3、删除mariadb的configmap
root@master01:~/ysxt-cnp# kubectl -n common delete cm common-mariadb-common-mariadb-mariadb-ingress common-mariadb-mariadb-state
主中心:
root@master01:~# kubectl -n common get pvc mysql-data-mariadb-server-0 mysql-data-mariadb-server-1 mysql-data-mariadb-server-2
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mysql-data-mariadb-server-0 Bound pvc-b20feb26-b413-426f-b5cb-710e76e40b84 150Gi RWO hostpath-provisioner 8d
mysql-data-mariadb-server-1 Bound pvc-48e35e45-c9fe-4e10-9cad-1db6d7adae15 150Gi RWO hostpath-provisioner 8d
mysql-data-mariadb-server-2 Bound pvc-4219647e-19e1-4683-949c-b7f166391a6c 150Gi RWO hostpath-provisioner 8d
root@master01:~# kubectl -n common get pvc mysql-data-mariadb-server-0 mysql-data-mariadb-server-1 mysql-data-mariadb-server-2 -oyaml > mariadb-server-pvc.yaml
root@master01:~# kubectl get pv pvc-b20feb26-b413-426f-b5cb-710e76e40b84 pvc-48e35e45-c9fe-4e10-9cad-1db6d7adae15 pvc-4219647e-19e1-4683-949c-b7f166391a6c -oyaml > mariadb-server-pv.yaml
root@master01:~# scp -P 6233 -i /etc/kubernetes/common/private_key mariadb-server-pvc.yaml mariadb-server-pv.yaml 172.16.2.201:/root
mariadb-server-pvc.yaml 100% 3248 5.9MB/s 00:00
mariadb-server-pv.yaml 100% 3959 7.5MB/s 00:00
备中心:
删除yaml中不必要的字段:anotation、status等
root@master01:~# kubectl apply -f mariadb-server-pvc.yaml -f mariadb-server-pv.yaml
mariadb-server-pvc.yaml:
apiVersion: v1
items:
- apiVersion: v1
kind: PersistentVolumeClaim
metadata:
labels:
application: mariadb
component: server
release_group: common-mariadb
name: mysql-data-mariadb-server-0
namespace: common
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 150Gi
storageClassName: hostpath-provisioner
volumeMode: Filesystem
volumeName: pvc-b20feb26-b413-426f-b5cb-710e76e40b84
- apiVersion: v1
kind: PersistentVolumeClaim
metadata:
labels:
application: mariadb
component: server
release_group: common-mariadb
name: mysql-data-mariadb-server-1
namespace: common
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 150Gi
storageClassName: hostpath-provisioner
volumeMode: Filesystem
volumeName: pvc-48e35e45-c9fe-4e10-9cad-1db6d7adae15
- apiVersion: v1
kind: PersistentVolumeClaim
metadata:
labels:
application: mariadb
component: server
release_group: common-mariadb
name: mysql-data-mariadb-server-2
namespace: common
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 150Gi
storageClassName: hostpath-provisioner
volumeMode: Filesystem
volumeName: pvc-4219647e-19e1-4683-949c-b7f166391a6c
kind: List
metadata:
resourceVersion: ""
selfLink: ""
mariadb-server-pv.yaml:
apiVersion: v1
items:
- apiVersion: v1
kind: PersistentVolume
metadata:
name: pvc-b20feb26-b413-426f-b5cb-710e76e40b84
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 150Gi
claimRef:
apiVersion: v1
kind: PersistentVolumeClaim
name: mysql-data-mariadb-server-0
namespace: common
resourceVersion: "200470"
hostPath:
path: /data/vmdata/hpvolumes/pvc-b20feb26-b413-426f-b5cb-710e76e40b84
type: ""
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- worker13 #根据情况修改
persistentVolumeReclaimPolicy: Delete
storageClassName: hostpath-provisioner
volumeMode: Filesystem
- apiVersion: v1
kind: PersistentVolume
metadata:
name: pvc-48e35e45-c9fe-4e10-9cad-1db6d7adae15
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 150Gi
claimRef:
apiVersion: v1
kind: PersistentVolumeClaim
name: mysql-data-mariadb-server-1
namespace: common
resourceVersion: "200481"
hostPath:
path: /data/vmdata/hpvolumes/pvc-48e35e45-c9fe-4e10-9cad-1db6d7adae15
type: ""
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- worker14
persistentVolumeReclaimPolicy: Delete
storageClassName: hostpath-provisioner
volumeMode: Filesystem
- apiVersion: v1
kind: PersistentVolume
metadata:
name: pvc-4219647e-19e1-4683-949c-b7f166391a6c
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 150Gi
claimRef:
apiVersion: v1
kind: PersistentVolumeClaim
name: mysql-data-mariadb-server-2
namespace: common
resourceVersion: "200489"
hostPath:
path: /data/vmdata/hpvolumes/pvc-4219647e-19e1-4683-949c-b7f166391a6c
type: ""
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- worker12
persistentVolumeReclaimPolicy: Delete
storageClassName: hostpath-provisioner
volumeMode: Filesystem
kind: List
metadata:
resourceVersion: ""
selfLink: ""
root@master01:~# cd ysxt-cnp/
root@master01:~/ysxt-cnp# helm install common-mariadb mariadb/ -n common
NAME: common-mariadb
LAST DEPLOYED: Sat Jul 16 18:45:31 2022
NAMESPACE: common
STATUS: deployed
REVISION: 1
TEST SUITE: None
检查当前节点所有pvc:
root@worker12:~# ll /data/vmdata/hpvolumes/
total 32
drwxr-xr-x 5 root root 4096 Jul 7 18:45 ./
drwxr-xr-x 3 root root 4096 Jul 7 13:06 ../
drwx------ 2 root root 16384 Jul 7 13:05 lost+found/
drwxrwxrwx 4 etcd etcd 4096 Jul 7 18:47 pvc-4219647e-19e1-4683-949c-b7f166391a6c/
drwxr-xr-x 4 etcd etcd 4096 Jul 7 17:33 pvc-f2ca677a-7142-4147-99dc-488ee950c951/
root@master01:~# kubectl get pvc -A |grep pvc-4219647e-19e1-4683-949c-b7f166391a6c
common mysql-data-mariadb-server-2 Bound pvc-4219647e-19e1-4683-949c-b7f166391a6c 150Gi RWO hostpath-provisioner 8d
root@master01:~# kubectl get pvc -A |grep pvc-f2ca677a-7142-4147-99dc-488ee950c951/
root@master01:~#
# 第2个pvc不存在,所以删掉这个目录即可。
root@worker12:/data/vmdata/hpvolumes# mv pvc-f2ca677a-7142-4147-99dc-488ee950c951 /tmp
root@worker12:/data/vmdata/hpvolumes# ll
total 28
drwxr-xr-x 4 root root 4096 Jul 16 16:59 ./
drwxr-xr-x 3 root root 4096 Jul 7 13:06 ../
drwx------ 2 root root 16384 Jul 7 13:05 lost+found/
drwxrwxrwx 4 etcd etcd 4096 Jul 7 18:47 pvc-4219647e-19e1-4683-949c-b7f166391a6c/
Worker13、worker14节点做同样的操作。
所有节点注释掉如下项,以免重启后导致虚机无法启动:
#/dev/sdb1 /data/vmdata/hpvolumes ext4 defaults 0 0
主备中心都需要操作
root@master01:~# kubectl scale sts -n common mariadb-server --replicas=0
确认worker12上的pod已经删除
root@worker12:~# docker ps |grep mariadb-serve
root@worker12:~# cp -ra /data/vmdata/hpvolumes/ /mnt # 1、cp -a 或 scp -p 2、注意目标目录的磁盘空间是否充足 3、目录下所有pvc相关的负载调整副本为0
root@worker12:~# ls /mnt/hpvolumes/
lost+found pvc-4219647e-19e1-4683-949c-b7f166391a6c
裸盘方案
umount /data/vmdata/hpvolumes
fdisk /dev/sdb #删除分区,成为裸盘
d
w
# 因hostpath-provisioner容器也挂载了/data/vmdata/hpvolumes目录,所以需要重启一下该容器
docker stop $(docker ps |grep -v pause|grep hostpath-provisioner |awk '{print $NF}');partprobe
lsblk
lvm方案:可以基于lvm快照实现安全的resync。相关配置见下文
注意:mariadb-server0对端IP要修改
cat >/etc/drbd.d/cke_mariadb.res <<"EOF"
resource mariadb {
net {
# 同步复制协议
protocol C;
# 不允许双主
allow-two-primaries no;
}
options {
# 不允许自动提升为主角色
auto-promote no;
}
# 节点名称,与 hostname 一致
on worker12 {
# drbd 生成的设备盘符
device /dev/drbd0;
# 底层物理盘符
disk /dev/sdb;
# 本地 ip + 端口号
address 172.16.1.12:7790;
# 节点 id, 自己分配控制,每个节点唯一,取值范围 1~32,一旦分配生效,不可随意更改
node-id 2;
}
# 对端节点名称,可自定义,无需与实际节点 hostname 一致
on remote_172.16.2.12 {
# 对端地址+端口号,必须直通,若走代理则配置代理地址和端口号
address 172.16.2.12:7790;
# 对端 drbd 设备盘符
device /dev/drbd0;
# 对端底层物理盘符
disk /dev/sdb;
# 对端节点 id
node-id 1;
}
}
EOF
备节点的配置文件与主节点的配置文件一致,只需要修改on后面的名字即可。
cat >/etc/drbd.d/cke_mariadb.res <<"EOF"
resource mariadb {
net {
# 同步复制协议
protocol C;
# 不允许双主
allow-two-primaries no;
}
options {
# 不允许自动提升为主角色
auto-promote no;
}
# 节点名称,与 hostname 一致
on remote_172.16.1.12 {
# drbd 生成的设备盘符
device /dev/drbd0;
# 底层物理盘符
disk /dev/sdb;
# 本地 ip + 端口号
address 172.16.1.12:7790;
# 节点 id, 自己分配控制,每个节点唯一,取值范围 1~32,一旦分配生效,不可随意更改
node-id 2;
}
# 对端节点名称,可自定义,无需与实际节点 hostname 一致
on worker12 {
# 对端地址+端口号,必须直通,若走代理则配置代理地址和端口号
address 172.16.2.12:7790;
# 对端 drbd 设备盘符
device /dev/drbd0;
# 对端底层物理盘符
disk /dev/sdb;
# 对端节点 id
node-id 1;
}
}
EOF
主+备:
drbdadm create-md mariadb
# drbdadm attach mariadb # 如果status显示disk:Diskless时,执行
drbdadm up mariadb
主:
# (可选)drbdadm new-current-uuid --clear-bitmap <resource>/<volume> # 跳过初始全量同步。volume为drbdN中的N,即mariadb/0 。该步骤会无视Primary和Secondary间的磁盘数据块是否一致,而直接表示为UpToDate。所以需要人为处理数据块的一致性,比如使用基于卡车的复制(向远程节点预先设定数据,然后保持同步,并跳过初始的全量设备同步)
# drbdadm new-current-uuid --clear-bitmap mariadb/0
drbdadm primary mariadb --force
等待初始化完成后,再操作。(可以不等待,因为初始全量同步过程中,不影响磁盘写入)
root@worker12:~# drbdadm status
mariadb role:Primary
disk:UpToDate
remote_172.16.2.12 role:Secondary
replication:SyncSource peer-disk:Inconsistent done:16.67 # 完成16.67%
如果显示如下,则表示完成:
root@worker12:~# drbdadm status
mariadb role:Primary
disk:UpToDate
remote_172.16.2.12 role:Secondary
peer-disk:UpToDate
格式化drbd设备并挂载
root@worker12:~# mke2fs -t ext4 /dev/drbd0
root@worker12:~# mkdir -p /data/vmdata/hpvolumes/pvc-4219647e-19e1-4683-949c-b7f166391a6c/
root@worker12:~# mount /dev/drbd0 /data/vmdata/hpvolumes/pvc-4219647e-19e1-4683-949c-b7f166391a6c/
拷贝数据:要使用-a参加,保证文件的属性不发生变化
scp -rp
root@worker12:~# cp -ra /mnt/hpvolumes/pvc-4219647e-19e1-4683-949c-b7f166391a6c/* /data/vmdata/hpvolumes/pvc-4219647e-19e1-4683-949c-b7f166391a6c/
cat >/etc/drbd.d/cke_mariadb.res <<"EOF"
resource mariadb {
net {
# 同步复制协议
protocol C;
# 不允许双主
allow-two-primaries no;
}
options {
# 不允许自动提升为主角色
auto-promote no;
}
# 节点名称,与 hostname 一致
on worker13 {
# drbd 生成的设备盘符
device /dev/drbd0;
# 底层物理盘符
disk /dev/sdb;
# 本地 ip + 端口号
address 172.16.1.13:7790;
# 节点 id, 自己分配控制,每个节点唯一,取值范围 1~32,一旦分配生效,不可随意更改
node-id 2;
}
# 对端节点名称,可自定义,无需与实际节点 hostname 一致
on remote_172.16.2.13 {
# 对端地址+端口号,必须直通,若走代理则配置代理地址和端口号
address 172.16.2.13:7790;
# 对端 drbd 设备盘符
device /dev/drbd0;
# 对端底层物理盘符
disk /dev/sdb;
# 对端节点 id
node-id 1;
}
}
EOF
cat >/etc/drbd.d/cke_mariadb.res <<"EOF"
resource mariadb {
net {
# 同步复制协议
protocol C;
# 不允许双主
allow-two-primaries no;
}
options {
# 不允许自动提升为主角色
auto-promote no;
}
# 节点名称,与 hostname 一致
on remote_172.16.1.13 {
# drbd 生成的设备盘符
device /dev/drbd0;
# 底层物理盘符
disk /dev/sdb;
# 本地 ip + 端口号
address 172.16.1.13:7790;
# 节点 id, 自己分配控制,每个节点唯一,取值范围 1~32,一旦分配生效,不可随意更改
node-id 2;
}
# 对端节点名称,可自定义,无需与实际节点 hostname 一致
on worker13 {
# 对端地址+端口号,必须直通,若走代理则配置代理地址和端口号
address 172.16.2.13:7790;
# 对端 drbd 设备盘符
device /dev/drbd0;
# 对端底层物理盘符
disk /dev/sdb;
# 对端节点 id
node-id 1;
}
}
EOF
cat >/etc/drbd.d/cke_mariadb.res <<"EOF"
resource mariadb {
net {
# 同步复制协议
protocol C;
# 不允许双主
allow-two-primaries no;
}
options {
# 不允许自动提升为主角色
auto-promote no;
}
# 节点名称,与 hostname 一致
on worker14 {
# drbd 生成的设备盘符
device /dev/drbd0;
# 底层物理盘符
disk /dev/sdb;
# 本地 ip + 端口号
address 172.16.1.14:7790;
# 节点 id, 自己分配控制,每个节点唯一,取值范围 1~32,一旦分配生效,不可随意更改
node-id 2;
}
# 对端节点名称,可自定义,无需与实际节点 hostname 一致
on remote_172.16.2.14 {
# 对端地址+端口号,必须直通,若走代理则配置代理地址和端口号
address 172.16.2.14:7790;
# 对端 drbd 设备盘符
device /dev/drbd0;
# 对端底层物理盘符
disk /dev/sdb;
# 对端节点 id
node-id 1;
}
}
EOF
cat >/etc/drbd.d/cke_mariadb.res <<"EOF"
resource mariadb {
net {
# 同步复制协议
protocol C;
# 不允许双主
allow-two-primaries no;
}
options {
# 不允许自动提升为主角色
auto-promote no;
}
# 节点名称,与 hostname 一致
on remote_172.16.1.14 {
# drbd 生成的设备盘符
device /dev/drbd0;
# 底层物理盘符
disk /dev/sdb;
# 本地 ip + 端口号
address 172.16.1.14:7790;
# 节点 id, 自己分配控制,每个节点唯一,取值范围 1~32,一旦分配生效,不可随意更改
node-id 2;
}
# 对端节点名称,可自定义,无需与实际节点 hostname 一致
on worker14 {
# 对端地址+端口号,必须直通,若走代理则配置代理地址和端口号
address 172.16.2.14:7790;
# 对端 drbd 设备盘符
device /dev/drbd0;
# 对端底层物理盘符
disk /dev/sdb;
# 对端节点 id
node-id 1;
}
}
EOF
调整副本,启动mariadb。
主:
方式1:
# 调整mariadb副本为0
umount /dev/drbd0
drbdadm secondary mairadb
方式2:直接模拟异常断电
echo "c" > /proc/sysrq-trigger
备:
drbdadm primary mairadb
mount /dev/drbd0 ...
启动mariadb
先删除
configmap/common-mariadb-mariadb-state,表示删除Galera集群。在调整副本为1:表示使用server-0节点的数据新建一个单节点的Galera集群。
启动成功后,再调整为3:表示server-1节点、server-2节点加入集群。如果原先存在数据,也会先删除,然后通过SST从server-0节点同步一份新的数据。
写入 CKE drbd 资源主角色标记:
touch /etc/drbd.d/cke_mariadb.res.primary配置 etcd pv 目录开机自动挂载
vim /etc/rc.local /usr/local/bin/all_init_onboot.sh && mount /dev/drbd0 /xxx...
# mysql -uroot -hmariadb.common.svc.cluster.local -p3=PUgdLL
create database test;
create or replace table test.t1(
id int auto_increment NOT NULL primary key,
intime char(20)
);
create or replace table test.t2(
id int auto_increment NOT NULL primary key,
intime char(20)
);
mysql_insert.sh:
说明:
该脚本测试耗时包含建立会话的时间。
#!/bin/bash
finish(){
[ "${sucess_count}" -ne 0 ] && ((avg=sucess_sum/sucess_count))
echo "总共插入${i}次数据,成功请求最大耗时:${max}ms 成功请求最小耗时:${min}ms 成功请求平均耗时:${avg}ms 成功请求次数:${sucess_count} 失败请求次数:${error_count}"
}
trap "finish;exit 0" INT TERM
i=0
sucess_sum=0
max=0
min=9999999
error_count=0
sucess_count=0
while true;do
# 毫秒
startTime=$(echo $(date +%s.%N)*1000|bc | cut -b 1-13)
#echo "开始插入时间:${startTime}"
mysql -uroot -hmariadb.common.svc.cluster.local -p3=PUgdLL -N 2>/dev/null <<EOF
begin;
insert into test.t1(intime) values ("${startTime}");
insert into test.t2(intime) values ("${startTime}");
commit;
EOF
return_code="$?"
endTime=$(echo $(date +%s.%N)*1000|bc | cut -b 1-13)
((times=$endTime-$startTime))
if [ "${return_code}" -ne "0" ];then
((error_count=error_count+1))
status=failure
else
((sucess_count=sucess_count+1))
((sucess_sum=sucess_sum+times))
status=sucess
fi
[ "${times}" -gt "${max}" ] && max=${times}
[ "${times}" -lt "${min}" ] && min=${times}
[ "${times}" -gt "1000" ] && times="${status} \033[1;31m${times}\033[0m" || times="${status} ${times}" # 耗时>1000ms,红色字体显示
((i=i+1))
echo -e "第${i}次开始插入时间:${startTime},耗时:${times}ms"
#sleep 0.01
done
网络短时中断:
持续写入数据(事务):网络断开2min。观察主状态,何时状态变化,是否影响主的写入;
网络恢复后,数据同步状态,是否影响主的写入
1) 未同步完成前:主异常断电。切换从。
继续写入数据
2) 启动主: 建立同步
结论:full reSync过程中,不影响Primary数据写入
前提:Primary和Second处于同步状态:UpToDate
整个过程中不断写入数据!
时间分布图:
| 集群1(初始:备中心) | 集群2(初始:主中心) |
|---|---|
| echo “c” > /proc/sysrq-trigger | |
| 提升为Primary(现象:数据正常) | |
| 启动虚机,状态为Secondary(现象:自动触发reSync) | |
| (回切)降级为Secondary | |
| 提升为Primary(现象数据正常) |
具体操作步骤
主所有节点执行:
root@worker12:~# echo "c" > /proc/sysrq-trigger
此时,查看Secondary的状态:
root@worker12:~# drbdadm status
mariadb role:Secondary
disk:UpToDate
remote_172.16.2.12 connection:Connecting
将Secondary提升为Primary:
root@worker12:~# drbdadm primary mariadb
root@worker12:~# mount /dev/drbd0 /data/vmdata/hpvolumes/pvc-4219647e-19e1-4683-949c-b7f166391a6c/
启动应用,测试服务是否正常。
运行一段时间后,启动原先的Primary:触发reSync操作,最终状态为UpToDate
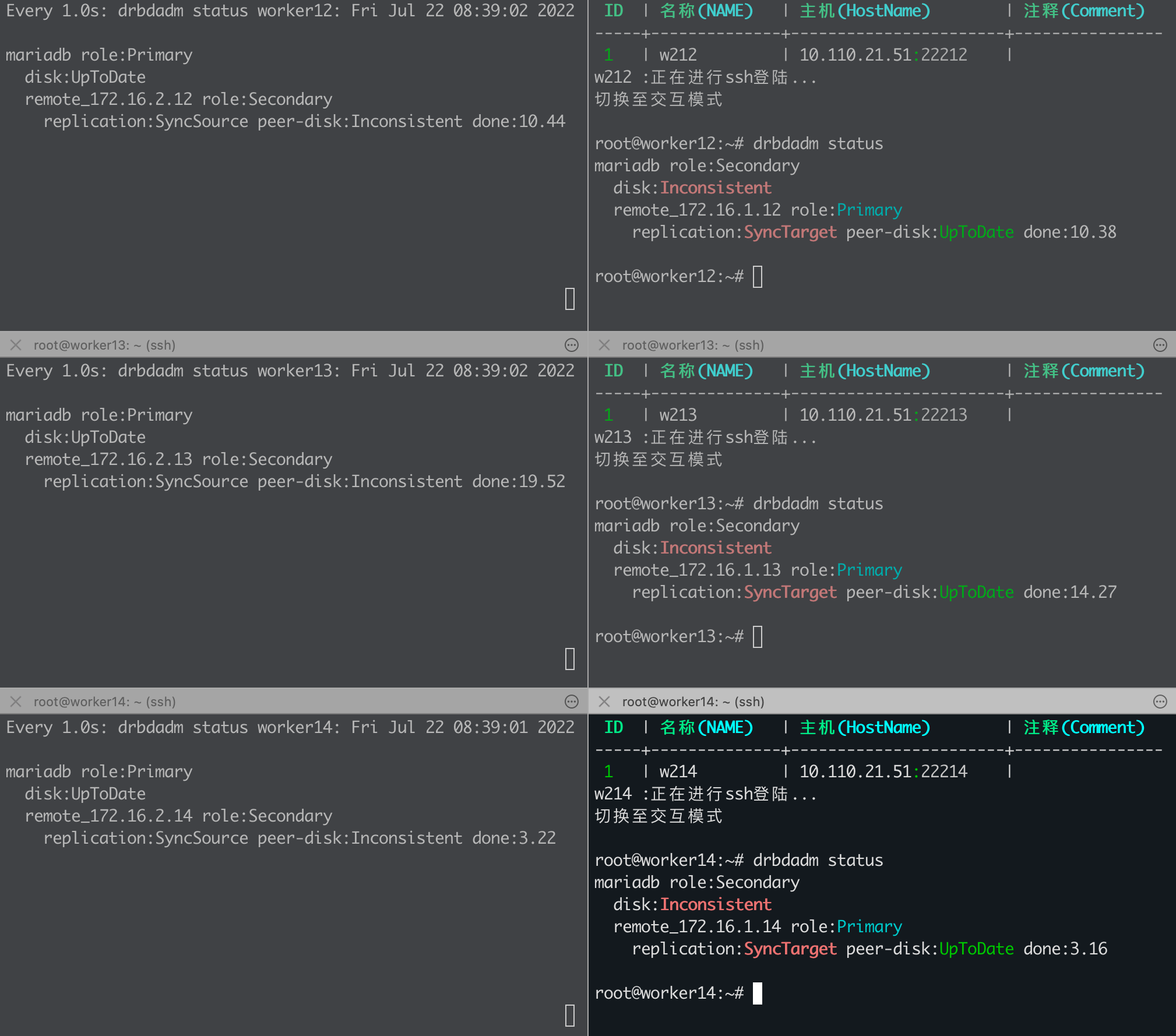
将新的Primary的应用关闭,并降级为Secondary:
root@worker12:~# umount /dev/drbd0
root@worker12:~# drbdadm secondary mariadb
提升原先的Primary为新的Primary:
root@worker12:~# drbdadm primary mariadb
root@worker12:~# mount /dev/drbd0 /data/vmdata/hpvolumes/pvc-4219647e-19e1-4683-949c-b7f166391a6c/
启动应用,测试服务是否正常。
运行写入数据脚本
bash mysql_insert.shSecondary断开连接:让Primary无法连接Secondary
iptables -I INPUT -p tcp -m tcp --dport 7790 -j DROP;iptables -I INPUT -p tcp -m tcp --sport 7790 -j DROP观察状态
主节点磁盘写入:会有10s左右的不可写。

drdb状态:
Primary

Secondary

Secondary恢复连接
iptables -D INPUT -p tcp -m tcp --dport 7790 -j DROP;iptables -D INPUT -p tcp -m tcp --sport 7790 -j DROP观察状态
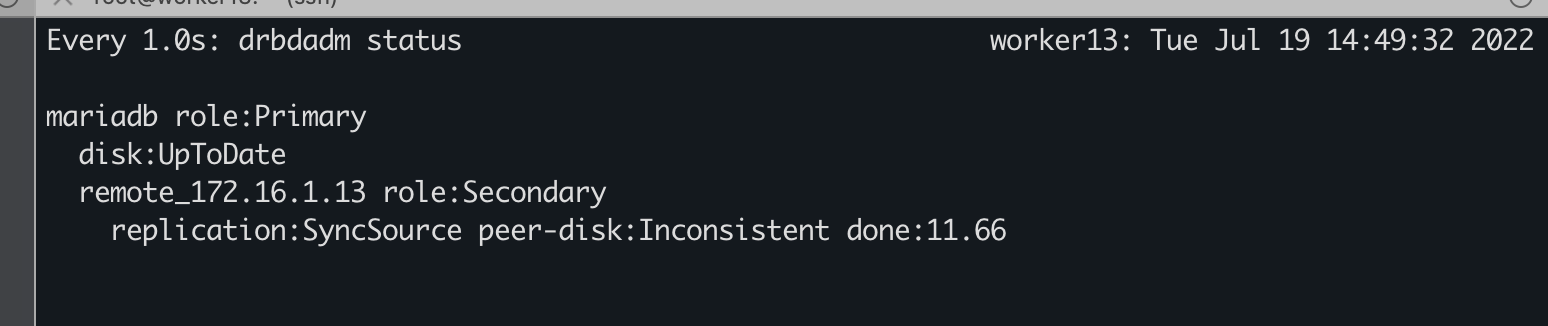
此时,进行”reSync“操作。Secondary处于”Inconsistent“状态。
Primary节点的写入操作不受影响。
模拟无法连接Secondary,一段时间后,网络恢复,Secondary处于”Inconsistent“状态。此时,关闭primary节点的网卡,一段时间后,再次恢复primary节点的网卡

关闭Primary网卡


恢复Primary网卡


会再次进行”同步“,直到UpToDate。
前提:Secondary处于”Inconsistent“状态,模拟可参考“用例2”
3个Primary执行如下命令,模拟异常断电:
echo "c" > /proc/sysrq-trigger
Secondary提升为Primary,并挂载:
drbdadm primary mariadb
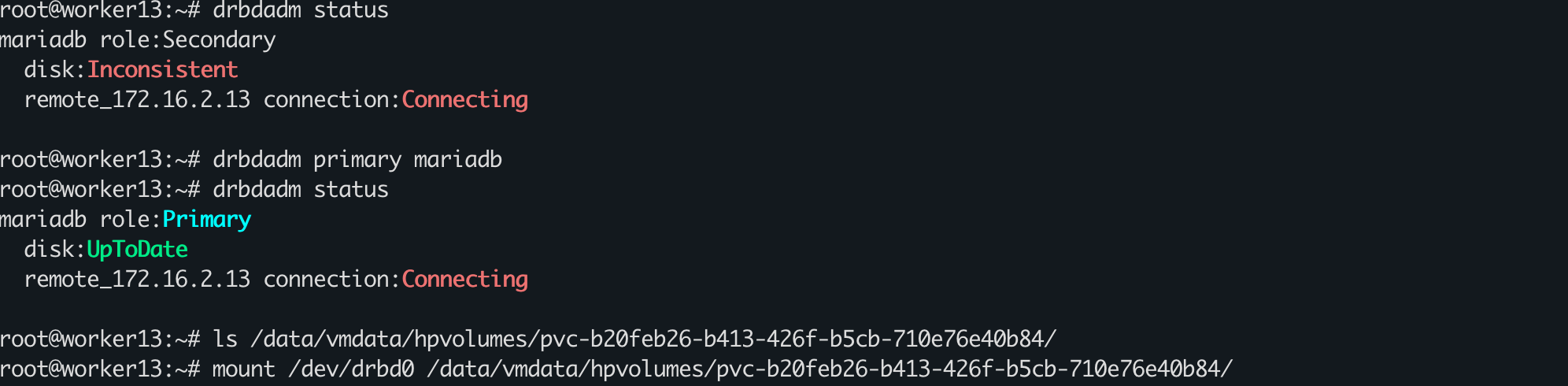
调整mariadb副本,启动mariadb。
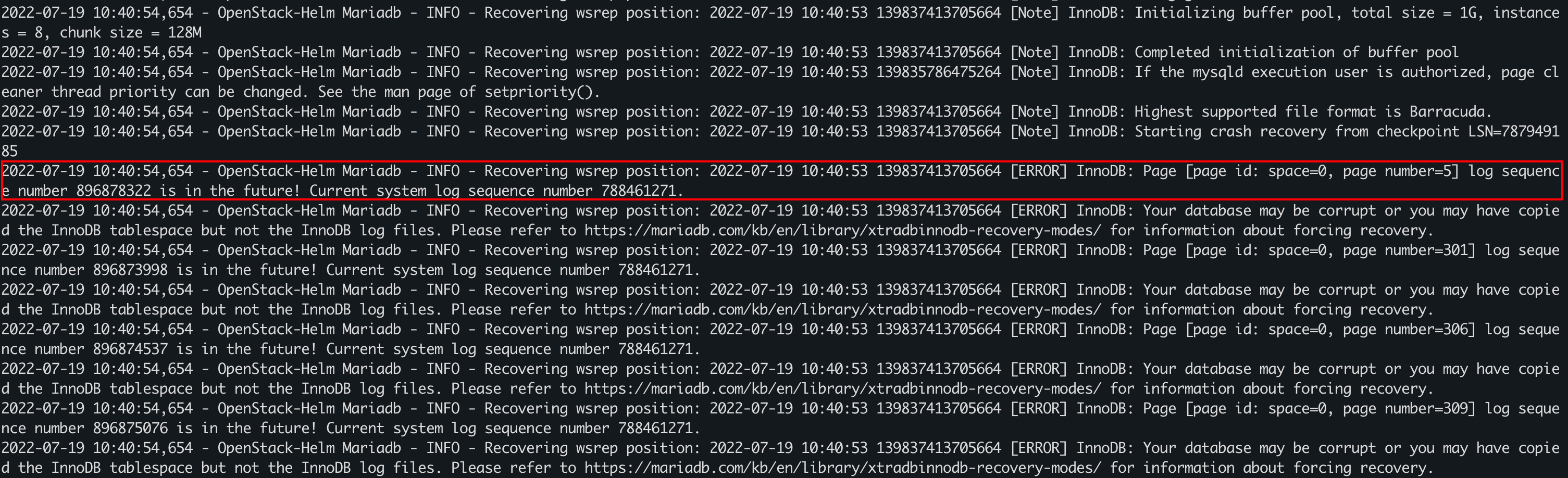
报错:
root@master1:~# kubectl logs -n common mariadb-server-0
2022-07-19 10:40:53,145 - OpenStack-Helm Mariadb - INFO - This instance hostname: mariadb-server-0
2022-07-19 10:40:53,145 - OpenStack-Helm Mariadb - INFO - This instance number: 0
2022-07-19 10:40:53,252 - OpenStack-Helm Mariadb - INFO - Kubernetes API Version: v1.20.13-21
2022-07-19 10:40:53,255 - OpenStack-Helm Mariadb - INFO - Will use "common-mariadb-mariadb-state" configmap for cluster state info
2022-07-19 10:40:53,256 - OpenStack-Helm Mariadb - INFO - Getting cluster state
2022-07-19 10:40:53,266 - OpenStack-Helm Mariadb - INFO - The cluster is currently in "live" state.
2022-07-19 10:40:53,266 - OpenStack-Helm Mariadb - INFO - Getting cluster state
2022-07-19 10:40:53,269 - OpenStack-Helm Mariadb - INFO - The cluster is currently in "live" state.
2022-07-19 10:40:53,269 - OpenStack-Helm Mariadb - INFO - Getting cluster state
2022-07-19 10:40:53,272 - OpenStack-Helm Mariadb - INFO - The cluster is currently in "live" state.
2022-07-19 10:40:53,272 - OpenStack-Helm Mariadb - INFO - Cluster has been running starting restore/rejoin
2022-07-19 10:40:53,272 - OpenStack-Helm Mariadb - INFO - Checking for active nodes
2022-07-19 10:40:53,275 - OpenStack-Helm Mariadb - INFO - This cluster has lost all running nodes, we need to determine the new lead node
2022-07-19 10:40:53,275 - OpenStack-Helm Mariadb - INFO - Updating grastate info for node
2022-07-19 10:40:53,275 - OpenStack-Helm Mariadb - INFO - Node shutdown was not clean, getting position via wsrep-recover
2022-07-19 10:40:54,653 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: 2022-07-19 10:40:53 139837413705664 [Note] mysqld (mysqld 10.2.18-MariaDB-1:10.2.18+maria~bionic) starting as process 46 ...
2022-07-19 10:40:54,653 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: 2022-07-19 10:40:53 139837413705664 [Warning] InnoDB: Using innodb_file_format is deprecated and the parameter may be removed in future releases. See https://mariadb.com/kb/en/library/xtradbinnodb-file-format/
2022-07-19 10:40:54,653 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: 2022-07-19 10:40:53 139837413705664 [Warning] InnoDB: Using innodb_locks_unsafe_for_binlog is DEPRECATED. This option may be removed in future releases. Please use READ COMMITTED transaction isolation level instead; Please refer to https://mariadb.com/kb/en/library/set-transaction/
2022-07-19 10:40:54,654 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: 2022-07-19 10:40:53 139837413705664 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins
2022-07-19 10:40:54,654 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: 2022-07-19 10:40:53 139837413705664 [Note] InnoDB: Uses event mutexes
2022-07-19 10:40:54,654 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: 2022-07-19 10:40:53 139837413705664 [Note] InnoDB: Compressed tables use zlib 1.2.11
......
2022-07-19 10:40:54,668 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: 2022-07-19 10:40:53 139835920758528 [ERROR] InnoDB: Page [page id: space=24, page number=3] log sequence number 896878434 is in the future! Current system log sequence number 788461271.
2022-07-19 10:40:54,668 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: 2022-07-19 10:40:53 139835920758528 [ERROR] InnoDB: Your database may be corrupt or you may have copied the InnoDB tablespace but not the InnoDB log files. Please refer to https://mariadb.com/kb/en/library/xtradbinnodb-recovery-modes/ for information about forcing recovery.
2022-07-19 10:40:54,668 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: 2022-07-19 10:40:54 139837413705664 [Note] InnoDB: 128 out of 128 rollback segments are active.
2022-07-19 10:40:54,668 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: 2022-07-19 10:40:54 139835970418432 [Note] InnoDB: Starting in background the rollback of recovered transactions
2022-07-19 10:40:54,668 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: 2022-07-19 10:40:54 139835970418432 [ERROR] [FATAL] InnoDB: Trying to read page number 623 in space 25, space name test/t2, which is outside the tablespace bounds. Byte offset 0, len 16384
2022-07-19 10:40:54,668 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: 220719 10:40:54 [ERROR] mysqld got signal 6 ;
2022-07-19 10:40:54,668 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: This could be because you hit a bug. It is also possible that this binary
2022-07-19 10:40:54,668 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: or one of the libraries it was linked against is corrupt, improperly built,
2022-07-19 10:40:54,668 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: or misconfigured. This error can also be caused by malfunctioning hardware.
2022-07-19 10:40:54,668 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position:
2022-07-19 10:40:54,668 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: To report this bug, see https://mariadb.com/kb/en/reporting-bugs
2022-07-19 10:40:54,668 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position:
2022-07-19 10:40:54,668 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: We will try our best to scrape up some info that will hopefully help
2022-07-19 10:40:54,668 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: diagnose the problem, but since we have already crashed,
2022-07-19 10:40:54,668 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: something is definitely wrong and this may fail.
2022-07-19 10:40:54,668 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position:
2022-07-19 10:40:54,668 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: Server version: 10.2.18-MariaDB-1:10.2.18+maria~bionic
2022-07-19 10:40:54,668 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: 2022-07-19 10:40:54 139837413705664 [Note] InnoDB: Removed temporary tablespace data file: "ibtmp1"
2022-07-19 10:40:54,668 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: key_buffer_size=134217728
2022-07-19 10:40:54,668 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: read_buffer_size=131072
2022-07-19 10:40:54,669 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: max_used_connections=0
2022-07-19 10:40:54,669 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: max_threads=8194
2022-07-19 10:40:54,669 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: thread_count=0
2022-07-19 10:40:54,669 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: It is possible that mysqld could use up to
2022-07-19 10:40:54,669 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: key_buffer_size + (read_buffer_size + sort_buffer_size)*max_threads = 18136341 K bytes of memory
2022-07-19 10:40:54,669 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: Hope that's ok; if not, decrease some variables in the equation.
2022-07-19 10:40:54,669 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position:
2022-07-19 10:40:54,669 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: Thread pointer: 0x0
2022-07-19 10:40:54,669 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: Attempting backtrace. You can use the following information to find out
2022-07-19 10:40:54,669 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: where mysqld died. If you see no messages after this, something went
2022-07-19 10:40:54,669 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: terribly wrong...
2022-07-19 10:40:54,669 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: 2022-07-19 10:40:54 139837413705664 [Note] InnoDB: Creating shared tablespace for temporary tables
2022-07-19 10:40:54,669 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: stack_bottom = 0x0 thread_stack 0x49000
2022-07-19 10:40:54,669 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: 2022-07-19 10:40:54 139837413705664 [Note] InnoDB: Setting file './ibtmp1' size to 12 MB. Physically writing the file full; Please wait ...
2022-07-19 10:40:54,669 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: 2022-07-19 10:40:54 139837413705664 [Note] InnoDB: File './ibtmp1' size is now 12 MB.
2022-07-19 10:40:54,669 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: mysqld(my_print_stacktrace+0x2e)[0x563e6c1d121e]
2022-07-19 10:40:54,669 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: mysqld(handle_fatal_signal+0x5a3)[0x563e6bc54f13]
2022-07-19 10:40:54,669 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: /lib/x86_64-linux-gnu/libpthread.so.0(+0x12890)[0x7f2e6d96e890]
2022-07-19 10:40:54,669 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: /lib/x86_64-linux-gnu/libc.so.6(gsignal+0xc7)[0x7f2e6ce82e97]
2022-07-19 10:40:54,669 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: /lib/x86_64-linux-gnu/libc.so.6(abort+0x141)[0x7f2e6ce84801]
2022-07-19 10:40:54,669 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: mysqld(+0x93bab1)[0x563e6bf3bab1]
2022-07-19 10:40:54,670 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: mysqld(+0x40c265)[0x563e6ba0c265]
2022-07-19 10:40:54,670 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: mysqld(+0x9f4dd0)[0x563e6bff4dd0]
2022-07-19 10:40:54,670 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: mysqld(+0x9a6783)[0x563e6bfa6783]
2022-07-19 10:40:54,670 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: mysqld(+0x97bcb5)[0x563e6bf7bcb5]
2022-07-19 10:40:54,670 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: mysqld(+0x959058)[0x563e6bf59058]
2022-07-19 10:40:54,670 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: mysqld(+0x8b4ca3)[0x563e6beb4ca3]
2022-07-19 10:40:54,670 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: mysqld(+0x8b695c)[0x563e6beb695c]
2022-07-19 10:40:54,670 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: mysqld(+0x8ce081)[0x563e6bece081]
2022-07-19 10:40:54,670 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: mysqld(+0xa594fb)[0x563e6c0594fb]
2022-07-19 10:40:54,670 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: mysqld(+0xa5b113)[0x563e6c05b113]
2022-07-19 10:40:54,670 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: mysqld(+0x8cdcd3)[0x563e6becdcd3]
2022-07-19 10:40:54,670 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: mysqld(+0x87064c)[0x563e6be7064c]
2022-07-19 10:40:54,670 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: mysqld(+0x916fde)[0x563e6bf16fde]
2022-07-19 10:40:54,670 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: mysqld(+0x918901)[0x563e6bf18901]
2022-07-19 10:40:54,670 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: /lib/x86_64-linux-gnu/libpthread.so.0(+0x76db)[0x7f2e6d9636db]
2022-07-19 10:40:54,670 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: /lib/x86_64-linux-gnu/libc.so.6(clone+0x3f)[0x7f2e6cf6588f]
2022-07-19 10:40:54,670 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: The manual page at http://dev.mysql.com/doc/mysql/en/crashing.html contains
2022-07-19 10:40:54,670 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position: information that should help you find out what is causing the crash.
2022-07-19 10:40:54,670 - OpenStack-Helm Mariadb - INFO - Recovering wsrep position:
Traceback (most recent call last):
File "/tmp/start.py", line 820, in <module>
update_grastate_on_restart()
File "/tmp/start.py", line 532, in update_grastate_on_restart
set_grastate_val(key='seqno', value=recover_wsrep_position())
File "/tmp/start.py", line 530, in recover_wsrep_position
return wsrep_rec_pos
UnboundLocalError: local variable 'wsrep_rec_pos' referenced before assignment
root@drbd1:~# apt install -y flex xsltproc asciidoctor
root@drbd1:~# git clone https://github.com/LINBIT/drbd-utils -b 9.21.2
root@drbd1:~# cd drbd-utils-9.21.2/
root@drbd1:~/drbd-utils-9.21.2# bash autogen.sh #生成configure命令
root@drbd1:~/drbd-utils-9.21.2# ./configure --prefix=/usr --localstatedir=/var --sysconfdir=/etc --without-manual
root@drbd1:~/drbd-utils-9.21.2# make && make install
提示:
- LV和SLV(快照卷)必须位于同一个VG下,所以创建LV时,应预留SLV的空间。为了安全起见,建议为SLV预留同等大小的空间
pvcreate /dev/sdb -f
vgcreate vgdrbd /dev/sdb
lvcreate -L 80G -n lvdrbd vgdrbd
sed -i 's#/dev/sdb#/dev/vgdrbd/lvdrbd#g' /etc/drbd.d/cke_mariadb.res
LC_ALL=C
DRBD_MY_AF=ipv4
LANG=C
DRBD_PEER_ADDRESS=172.16.2.13
DRBD_MINOR=0
DRBD_VOLUME=0
DRBD_CONF=/etc/drbd.conf
DRBD_PEER_AF=ipv4
DRBD_MY_ADDRESS=172.16.1.13
PWD=/
HOME=/
DRBD_NODE_ID_1=remote_172.16.2.13
DRBD_NODE_ID_2=worker13
DRBD_RESOURCE=mariadb
DRBD_PEER_NODE_ID=1
TERM=linux
SHLVL=1
DRBD_BACKING_DEV=/dev/vgdrbd/lvdrbd
PATH=/sbin:/usr/sbin:/bin:/usr/bin
DRBD_LL_DISK=/dev/vgdrbd/lvdrbd
DRBD_CSTATE=Connected
DRBD_MY_NODE_ID=2
_=/usr/bin/env
这些环境变量会传给snapshot-resync-target-lvm.sh脚本。但是实际脚本使用的是:DRBD_RESOURCE, DRBD_VOLUME, DRBD_MINOR, DRBD_LL_DISK
1、disk配置应为LV
lvcreate -n lvmariadb -L 250G lvmvg
2、handlers启用before-resync-target、after-resync-target配置,也可以在/etc/drbd.d/global_common.conf的common段内配置。
vim /etc/drbd.d/global_common.conf
handlers {
before-resync-target "/usr/lib/drbd/snapshot-resync-target-lvm.sh";
after-resync-target "/usr/lib/drbd/unsnapshot-resync-target-lvm.sh";
}
root@worker01:~# cat /etc/drbd.d/cke_mariadb.res
resource mariadb {
net {
# 同步复制协议
protocol C;
# 不允许双主
allow-two-primaries no;
}
options {
# 不允许自动提升为主角色
auto-promote no;
}
# 节点名称,与 hostname 一致
on worker01 {
# drbd 生成的设备盘符
device /dev/drbd0;
# 底层物理盘符
disk /dev/lvmvg/lvmariadb;
# 本地 ip + 端口号
address 10.221.6.31:7789;
# 节点 id, 自己分配控制,每个节点唯一,取值范围 1~32,一旦分配生效,不可随意更改
node-id 1;
}
# 对端节点名称,可自定义,无需与实际节点 hostname 一致
on remote_10.58.240.28_7789 {
# 对端地址+端口号,必须直通,若走代理则配置代理地址和端口号
address 10.58.240.28:7789;
# 对端 drbd 设备盘符
device /dev/drbd0;
# 对端底层物理盘符
disk /dev/lvmvg/lvmariadb;
# 对端节点 id
node-id 2;
}
}
或:
root@worker12:~# cat /etc/drbd.d/cke_mariadb.res
resource mariadb {
net {
# 同步复制协议
protocol C;
# 不允许双主
allow-two-primaries no;
}
options {
# 不允许自动提升为主角色
auto-promote no;
}
handlers {
before-resync-target "/usr/lib/drbd/snapshot-resync-target-lvm.sh";
after-resync-target "/usr/lib/drbd/unsnapshot-resync-target-lvm.sh";
}
# 节点名称,与 hostname 一致
on remote_172.16.1.12 {
# drbd 生成的设备盘符
device /dev/drbd0;
# 底层物理盘符
disk /dev/vgdrbd/lvdrbd;
# 本地 ip + 端口号
address 172.16.1.12:7790;
# 节点 id, 自己分配控制,每个节点唯一,取值范围 1~32,一旦分配生效,不可随意更改
node-id 2;
}
# 对端节点名称,可自定义,无需与实际节点 hostname 一致
on worker12 {
# 对端地址+端口号,必须直通,若走代理则配置代理地址和端口号
address 172.16.2.12:7790;
# 对端 drbd 设备盘符
device /dev/drbd0;
# 对端底层物理盘符
disk /dev/vgdrbd/lvdrbd;
# 对端节点 id
node-id 1;
}
}
主+备:
drbdadm create-md mariadb
# drbdadm attach mariadb # 如果status显示disk:Diskless时,执行
drbdadm up mariadb
主:
drbdadm primary mariadb --force
如果reSync阶段Primary出现不可恢复的宕机,导致Secondary处于Inconsistent状态。则需要通过lvm快照卷恢复数据到一个数据一致的时间点。但是需要注意的是:恢复后,数据是一致的,但是是一个过时(out-of-date)的数据。
umount /dev/drbd0
drbdadm down mariadb
lvconvert --merge SNAP_LV_NAME
快照卷的容量必须等同与逻辑卷的容量;快照卷仅一次有效,一旦执行还原操作
lvconvert --merge后即立即删除。建议使用mount+cp的方式。LV和SLV(快照卷)必须位于同一个VG下,所以创建LV时,应预留SLV的空间。为了安全起见,建议为SLV预留同等大小的空间:(VGsize/2-1)G
首次全量同步也会触发lvm快照,所以需要100%的源LV的大小
快照卷建议使用只读快照,但测试drbd创建的只读快照无法挂载。只能使用lvconvert进行merge操作。
reSync过程,中断-恢复-中断- 恢复 ,多次resync会不会创建多个快照。
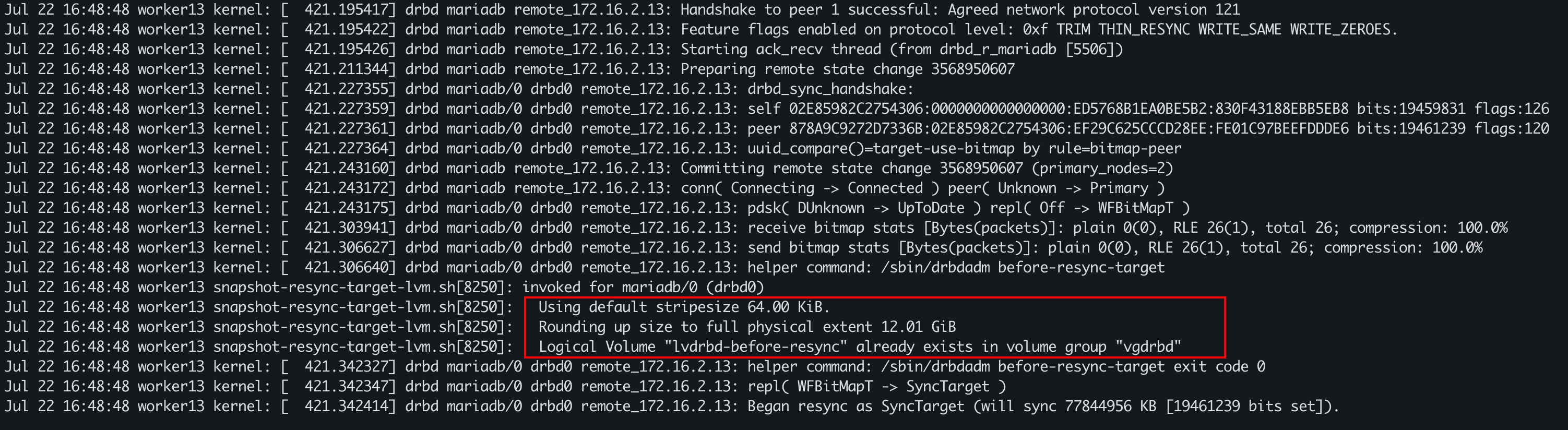
小提示:before-resync-target是由drbdadm命令调用的。
lvconvert失败,处理方法:
恢复快照之前必须umount和down掉drbd,否则会报错。
root@worker13:~# lvconvert --merge /dev/vgdrbd/lvdrbd-before-resync
Can't merge until origin volume is closed.
Merging of snapshot vgdrbd/lvdrbd-before-resync will occur on next activation of vgdrbd/lvdrbd.
#这是由于没有关闭drbd导致的,需要执行umount操作和drbdadm down mariadb
root@worker13:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
lvdrbd vgdrbd Owi-aos--- 10.00g
root@worker13:~# lvs -a
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
lvdrbd vgdrbd Owi-aos--- 10.00g
[lvdrbd-before-resync] vgdrbd Sri-a-s--- 10.01g lvdrbd 0.41
# 找到执行merge操作时的卷组的元数据的备份文件(可根据时间判断是哪个文件)
## vgcfgrestore -l vgdrbd |grep -C 2 -- --merge # 或grep -l "\--merge" /etc/lvm/archive/*
root@worker13:~# vgcfgrestore -l vgdrbd |grep -C 2 -- --merge
--
File: /etc/lvm/archive/vgdrbd_00067-1800443920.vg
VG name: vgdrbd
Description: Created *before* executing 'lvconvert --merge /dev/vgdrbd/lvdrbd-before-resync'
Backup Time: Wed Jul 27 15:13:31 2022
--
File: /etc/lvm/archive/vgdrbd_00068-464154123.vg
VG name: vgdrbd
Description: Created *before* executing 'lvconvert --merge /dev/vgdrbd/lvdrbd-before-resync'
Backup Time: Wed Jul 27 15:25:18 2022
--
File: /etc/lvm/archive/vgdrbd_00072-696664673.vg
VG name: vgdrbd
Description: Created *before* executing 'lvconvert --merge /dev/vgdrbd/lvdrbd-before-resync' #应该使用该次备份
Backup Time: Wed Jul 27 15:42:57 2022
--
File: /etc/lvm/backup/vgdrbd
VG name: vgdrbd
Description: Created *after* executing 'lvconvert --merge /dev/vgdrbd/lvdrbd-before-resync'
Backup Time: Wed Jul 27 15:42:57 2022
# 根据时间判断出备份文件应该为/etc/lvm/archive/vgdrbd_00072-696664673.vg,然后使用该文件进行vg元数据的恢复
root@worker13:~# vgcfgrestore -f /etc/lvm/archive/vgdrbd_00072-696664673.vg vgdrbd
Restored volume group vgdrbd
root@worker13:~# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
lvdrbd vgdrbd owi-aos--- 10.00g
lvdrbd-before-resync vgdrbd sri-a-s--- 10.01g lvdrbd 0.41
root@worker13:~# drbdadm down mariadb
root@worker13:~# lvconvert --merge /dev/vgdrbd/lvdrbd-before-resync
Merging of volume vgdrbd/lvdrbd-before-resync started.
vgdrbd/lvdrbd: Merged: 99.67%
vgdrbd/lvdrbd: Merged: 100.00%
参考连接:
Merging snapshot causing activation failure of origin volume
如果MariaDB Galera集群的3个节点有其中一个处于UpToDate状态,表示该盘完成了reSync操作,为最新的数据,应使用该数据进行恢复。具体操作:
使用
scp -r -p命令拷贝该节点的MySQL的数据到mariadb-server-0节点的数据目录(确保拷贝的文件属性保持不变),然后启动Galera集群即可。对于mariadb-server-1和mariadb-server-2节点的数据,无论其数据是否有效,都会被删除,然后从mariadb-server-0中全量同步最新的数据。
以新的PV:/dev/sdc
1、底层扩容
# # on all nodes, resize the backing LV:
root@worker13:~# pvcreate /dev/sdc
Physical volume "/dev/sdc" successfully created.
root@worker13:~# vgextend vgdrbd /dev/sdc
Volume group "vgdrbd" successfully extended
# lvextend -L +${additional_gb}g VG/LV
root@worker13:~# lvextend -L +2G /dev/vgdrbd/lvdrbd
2、drbd卷扩容
# # on one node:
# drbdadm resize ${resource_name}/${volume_number} # 将触发新增部分的同步
root@worker13:~# drbdadm resize mariadb/0
# on the Primary only:
# # resize the file system using the file system specific tool, see below
#resize2fs /dev/drbd#
root@worker13:~# resize2fs /dev/drbd0
说明:
如果是xfs文件系统,可使用如下命令进行文件系统扩容:
xfs_growfs /where/you/have/it/mounted # 参数为挂载点
复制与同步的区别:
- 复制:与复制协议有关,Protocol C是实时的。复制过程中,磁盘状态为UpToDate
- 同步(reSync):只有连接中断并恢复后,才会触发。过程中磁盘状态为InConsistent,该状态的磁盘数据不完整、不可用。
使用外部元数据,可以纳管已经存在数据的数据盘,不会导致数据盘上的数据丢失 。
限速条件下,drbd 读写功能正常;但drbd 数据盘 io 数据写入受限,吞吐量等于限速值。