02 Shard与replicas
- Elasticsearch索引由一个或多个主分片以及零个或多个副本分片构成;
- 每个shard都是一个最小工作单元,都是一个lucene实例,能够承载部分数据, 具有完整的建立索引和处理请求的能力;
- 增减节点时,shard会自动在nodes中负载均衡(rebalance);
- shard分为primary shard和replica shard。每个document只能存在于某一个primary shard以及其对应的replica shard中, 不可能存在于多个primary shard。
- replica shard是primary shard的副本,负责容错,以及承担读请求负载;
- 一个索引的primary shard的数量在创建索引的时候就固定了, replica shard的数量可以随时修改;
- primary shard的默认数量是5,replica默认是1。 默认有10个shard, 5个primary shard, 5个replica shard;
- 一个索引的多个primary shard可以分布在同一个node上,但primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用),但是可以和其他primary shard的replica shard放在同一个节点上。此外,同一个primary shard对应的多个replica shard之间也不能在同一个节点上。总结:存储相同数据的shard不能在同一个节点上,无论是primary shard与其对应的replica shard,还是互为备份的replica shard之间。
PUT test_index
{
"settings": {
"number_of_shards": 3, # primary shard的数量
"number_of_replicas": 1
}
}
如何超出扩容极限,以及如何提升容错性?
primary&replica能够自动负载均衡,对于"number_of_shards": 3,"number_of_replicas": 1的集群,一共会有6个shard(3 primary+3 replica)。如果对该集群进行扩容,扩容的极限是:6个shard最多扩容到6台机器,每个shard可以占用单台服务器的所有资源,性能最好。如果超出扩容极限,可以动态修改replica数量到9个shard (3primary+ 6 replica),然后扩容到9台机器,比3台机器时,拥有3倍的读吞吐量。
http://blog.itpub.net/9399028/viewspace-2666851/
es如何选主:必须获取半数以上的选票才可以成为主,所以node数一般设置为奇数台。
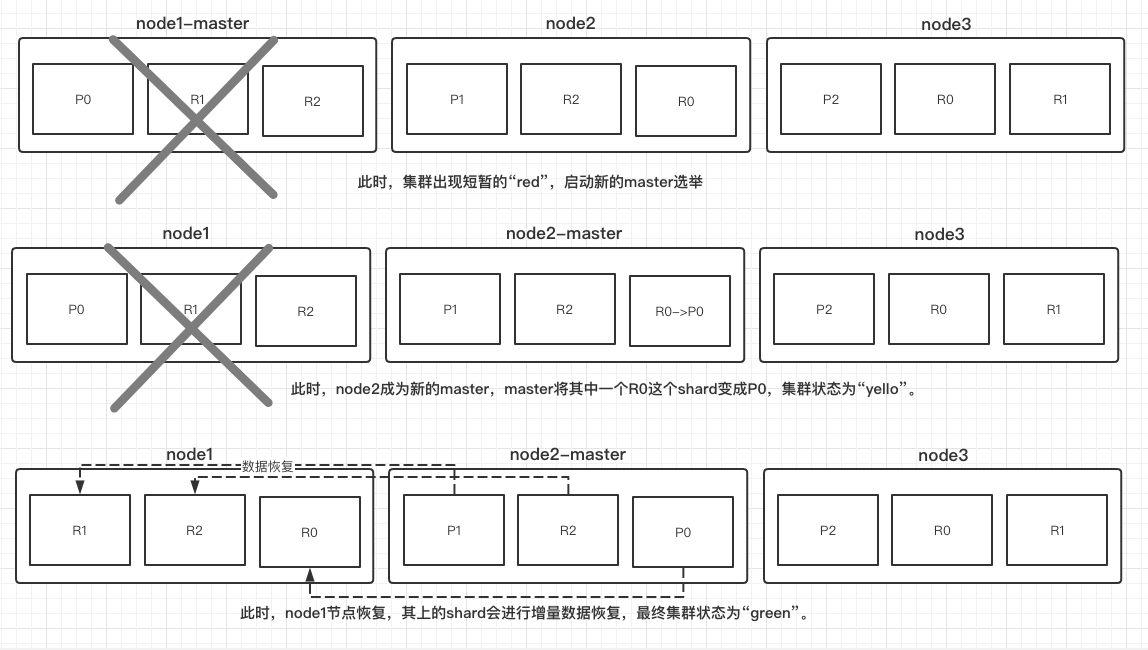
Elasticsearch在满足如下时间点的时候会触发选举
- 集群启动初始化
- 集群的Master崩溃的时候
- 任何一个节点发现当前集群中的Master节点没有得到
n/2 + 1节点认可的时候,触发选举
ES选举最核心的是Elasticsearch的选举流程,笔者研究了Elasticsearch选举源代码,同时看了很多文章之后,梳理出了选举过程中各个流程要点,下图是elasticsearch选举的流程图
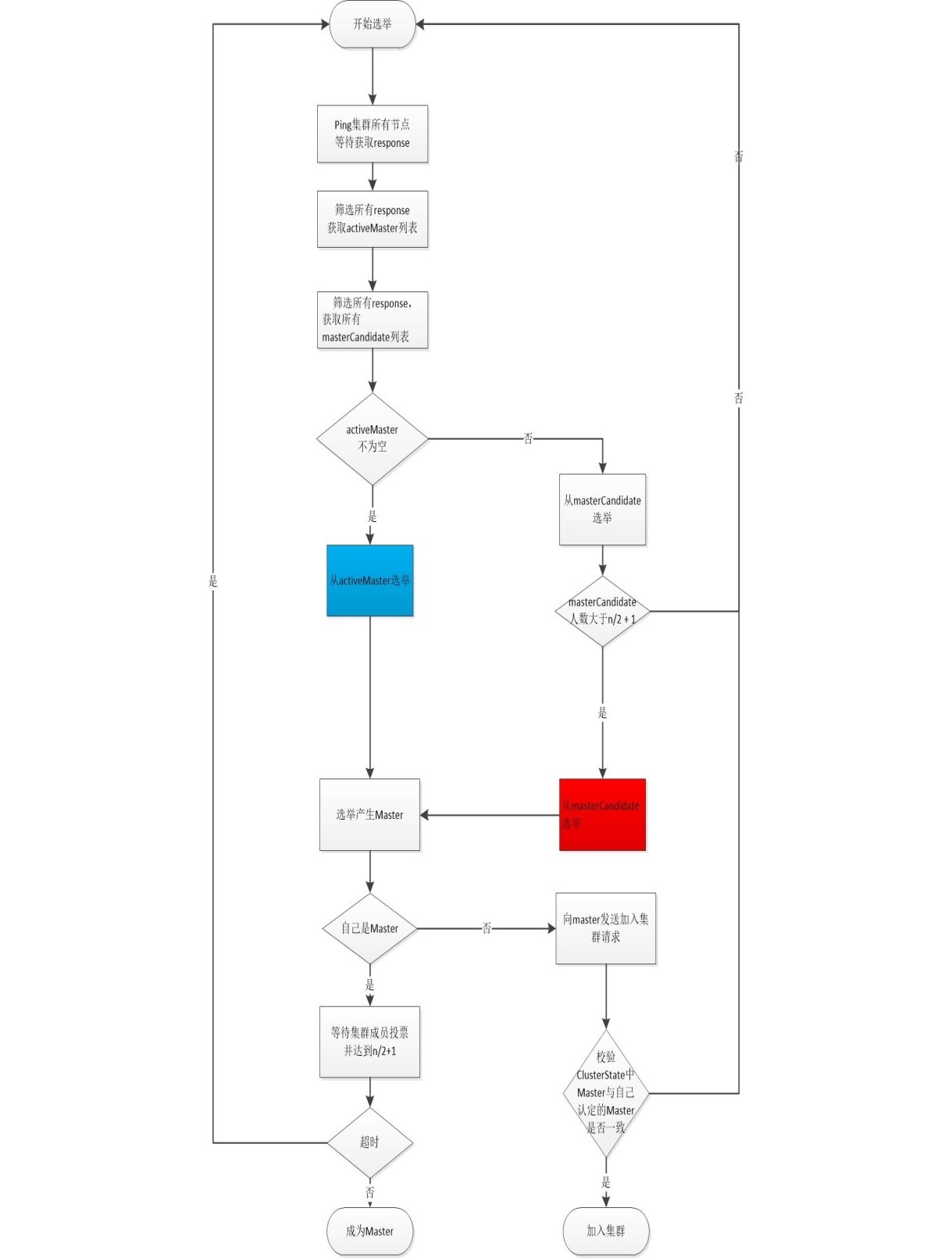
Es的master就是从activeMasters列表或者masterCandidates列表选举出来,所以选举之前es首先需要得到这两个列表。Elasticsearch节点成员首先向集群中的所有成员发送Ping请求,elasticsearch默认等待discovery.zen.ping_timeout时间,然后elasticsearch针对获取的全部response进行过滤,筛选出其中activeMasters列表,activeMaster列表是其它节点认为的当前集群的Master节点
源代码如下
List<DiscoveryNode> activeMasters = new ArrayList<>();
for (ZenPing.PingResponse pingResponse : pingResponses) {
//不允许将自己放在activeMasters列表中
if (pingResponse.master() != null && !localNode.equals(pingResponse.master())) {
activeMasters.add(pingResponse.master());
}
}
可以看到elasticsearch在获取activeMasters列表的时候会排除本地节点,目的是为了避免脑裂,假设这样一个场景,当前最小编号的节点P0认为自己就是master并且P0和其它节点发生网络分区,同时es允许将自己放在activeMaster中,因为P0编号最小,那么P0永远会选择自己作为master节点,那么就会出现脑裂的情况
masterCandidates列表是当前集群有资格成为Master的节点,如果我们在elasticsearch.yml中配置了如下参数,那么这个节点就没有资格成为Master节点,也就不会被筛选进入masterCandidates列表
# 配置某个节点没有成为master资格
node.master:false
源代码如下所示
List<ElectMasterService.MasterCandidate> masterCandidates = new ArrayList<>();
for (ZenPing.PingResponse pingResponse : pingResponses) {
if (pingResponse.node().isMasterNode()) {
masterCandidates.add(new ElectMasterService.MasterCandidate(pingResponse.node(), pingResponse.getClusterStateVersion()));
}
}
activeMaster列表是其它节点认为的当前集群的Master节点列表,如果activeMasters列表不为空,elasticsearch会优先从activeMasters列表中选举,也就是对应着流程图中的蓝色框,选举的算法是Bully算法,笔者在前文中详细介绍了Bully算法,Bully算法会涉及到优先级比较, 在activeMasters列表优先级比较的时候,如果节点有成为master的资格,那么优先级比较高,如果activeMaster列表有多个节点具有master资格,那么选择id最小的节点
代码如下
private static int compareNodes(DiscoveryNode o1, DiscoveryNode o2) {
if (o1.isMasterNode() && !o2.isMasterNode()) {
return -1;
}
if (!o1.isMasterNode() && o2.isMasterNode()) {
return 1;
}
return o1.getId().compareTo(o2.getId());
}
public DiscoveryNode tieBreakActiveMasters(Collection<DiscoveryNode> activeMasters) {
return activeMasters.stream().min(ElectMasterService::compareNodes).get();
}
这一节对应的是红色流程图中红色部分,如果activeMaster列表为空,那么会在masterCandidates中选举,masterCandidates选举也会涉及到优先级比较,masterCandidates选举的优先级比较和masterCandidates选举的优先级比较不同。它首先会判断masterCandidates列表成员数目是否达到了最小数目discovery.zen.minimum_master_nodes。如果达到的情况下比较优先级,优先级比较的时候首先比较节点拥有的集群状态版本编号,然后再比较id,这一流程的目的是让拥有最新集群状态的节点成为master
public static int compare(MasterCandidate c1, MasterCandidate c2) {
int ret = Long.compare(c2.clusterStateVersion, c1.clusterStateVersion);
if (ret == 0) {
ret = compareNodes(c1.getNode(), c2.getNode());
}
return ret;
}
经过上述选举之后,会选举出一个准master节点, 准master节点会等待其它节点的投票,如果有discovery.zen.minimum_master_nodes-1个节点投票认为当前节点是master,那么选举就成功,准master会等待discovery.zen.master_election.wait_for_joins_timeout时间,如果超时,那么就失败。在代码实现上准master通过注册一个回调来实现,同时借助了AtomicReference和CountDownLatch等并发构建实现
if (clusterService.localNode().equals(masterNode)) {
final int requiredJoins = Math.max(0, electMaster.minimumMasterNodes() - 1);
nodeJoinController.waitToBeElectedAsMaster(requiredJoins, masterElectionWaitForJoinsTimeout,
new NodeJoinController.ElectionCallback() {
@Override
public void onElectedAsMaster(ClusterState state) {
joinThreadControl.markThreadAsDone(currentThread);
nodesFD.updateNodesAndPing(state); // start the nodes FD
}
@Override
public void onFailure(Throwable t) {
logger.trace("failed while waiting for nodes to join, rejoining", t);
joinThreadControl.markThreadAsDoneAndStartNew(currentThread);
}
}
);
本地节点是Master的时候,Master节点会开启错误检测(NodeFaultDetection机制),它节点会定期扫描集群所有的成员,将失活的成员移除集群,同时将最新的集群状态发布到集群中,集群成员收到最新的集群状态后会进行相应的调整,比如重新选择主分片,进行数据复制等操作
当前节点判定在集群当前状态下如果自己不可能是master节点,首先会禁止其他节点加入自己,然后投票选举出准Master节点。同时监听master发布的集群状态(MasterFaultDetection机制),如果集群状态显示的master节点和当前节点认为的master节点不是同一个节点,那么当前节点就重新发起选举。
非Master节点也会监听Master节点进行错误检测,如果成员节点发现master连接不上,重新加入新的Master节点,如果发现当前集群中有很多节点都连不上master节点,那么会重新发起选举。