08 集群shard均衡策略 Ilm
https://zhuanlan.zhihu.com/p/164970344
ES集群的rebalance和allocation功能,可以自动均衡集群内部数据、分配分片,保证各个节点间尽量均衡。但是,在高访问量或者节点宕机的情况下,大范围的rebalance会影响到集群性能。所以,调整好集群相关参数,是重中之重。
集群分片分配是指将索引的shard分配到其他节点的过程,会在如下情况下触发:
- 集群内有节点宕机,需要故障恢复;
- 增加副本;
- 索引的动态均衡,包括集群内部节点数量调整、删除索引副本、删除索引等情况;
上述策略开关,可以动态调整,由参数cluster.routing.allocation.enable控制,启用或者禁用特定分片的分配。该参数的可选参数有:
- all - 默认值,允许为所有类型分片分配分片;
- primaries - 仅允许分配主分片的分片;
- new_primaries - 仅允许为新索引的主分片分配分片;
- none - 任何索引都不允许任何类型的分片;
重新启动节点时,此设置不会影响本地主分片的恢复。如果重新启动的节点具有未分配的主分片的副本,会立即恢复该主分片。
PUT _cluster/settings
{
"persistent" :
{
"cluster.routing.rebalance.enable": "none",
##允许在一个节点上发生多少并发传入分片恢复。 默认为2。
##多数为副本
"cluster.routing.allocation.node_concurrent_incoming_recoveries":2,
##允许在一个节点上发生多少并发传出分片恢复,默认为2.
## 多数为主分片
"cluster.routing.allocation.node_concurrent_outgoing_recoveries":2,
##为上面两个的统一简写
"cluster.routing.allocation.node_concurrent_recoveries":2,
##在通过网络恢复副本时,节点重新启动后未分配的主节点的恢复使用来自本地 磁盘的数据。
##这些应该很快,因此更多初始主要恢复可以在同一节点上并行发生。 默认为4。
"cluster.routing.allocation.node_initial_primaries_recoveries":4,
##允许执行检查以防止基于主机名和主机地址在单个主机上分配同一分片的多个实例。
##默认为false,表示默认情况下不执行检查。 此设置仅适用于在同一台计算机上启动多个节点的情况。这个我的理解是如果设置为false,
##则同一个节点上多个实例可以存储同一个shard的多个副本没有容灾作用了
"cluster.routing.allocation.same_shard.host":true
}
}
cluster.routing.rebalance.enable为特定类型的分片启用或禁用重新平衡:
- all - (默认值)允许各种分片的分片平衡;
- primaries - 仅允许主分片的分片平衡;
- replicas - 仅允许对副本分片进行分片平衡;
- none - 任何索引都不允许任何类型的分片平衡;
cluster.routing.allocation.allow_rebalance用来控制rebalance触发条件:
- always - 始终允许重新平衡;
- indices_primaries_active - 仅在所有主分片可用时;
- indices_all_active - (默认)仅当所有分片都激活时;
cluster.routing.allocation.cluster_concurrent_rebalance用来控制均衡力度,允许集群内并发分片的rebalance数量,默认为2。
cluster.routing.allocation.node_concurrent_recoveries,每个node上允许rebalance的片数量。
rebalance策略的触发条件,主要由下面几个参数控制:
## 每个节点上的从shard数量,-1代表不限制
cluster.routing.allocation.total_shards_per_node: -1
## 定义分配在该节点的分片数的因子 阈值=因子*(当前节点的分片数-集群的总分片数/节点数,即每个节点的平均分片数)
cluster.routing.allocation.balance.shard: 0.45f
## 定义分配在该节点某个索引的分片数的因子,阈值=因子*(保存当前节点的某个索引的分片数-索引的总分片数/节点数,即每个节点某个索引的平均分片数)
cluster.routing.allocation.balance.index: 0.55f
## 超出这个阈值就会重新分配分片
cluster.routing.allocation.balance.threshold: 1.0f
## 磁盘参数
## 启用基于磁盘的分发策略
cluster.routing.allocation.disk.threshold_enabled: true
## 硬盘使用率高于这个值的节点,则不会分配分片
cluster.routing.allocation.disk.watermark.low: "85%"
## 如果硬盘使用率高于这个值,则会重新分片该节点的分片到别的节点
cluster.routing.allocation.disk.watermark.high: "90%"
## 当前硬盘使用率的查询频率
cluster.info.update.interval: "30s"
## 计算硬盘使用率时,是否加上正在重新分配给其他节点的分片的大小
cluster.routing.allocation.disk.include_relocations: true
elasticsearch内部计算公式是:
weightindex(node, index) = indexBalance * (node.numShards(index) – avgShardsPerNode(index))
weightnode(node, index) = shardBalance * (node.numShards() – avgShardsPerNode)
weightprimary(node, index) = primaryBalance * (node.numPrimaries() – avgPrimariesPerNode)
weight(node, index) = weightindex(node, index) + weightnode(node, index) + weightprimary(node, index)
如果计算最后的weight(node, index)大于threshold, 就会发生shard迁移。
可以通过设置分片的分布规则来人为地影响分片的分布,示例如下:
假设有几个机架,可以在每个节点设置机架的属性:
node.attr.rack_id: r1
现在添加一条策略,设置rack_id作为分片规则的一个属性
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.awareness.attributes":"r1"
}
}
上面设置意味着rack_id会用来作为分片分布的依据。例如:我们启动两个node.attr.rack_id设置r1的节点,然后建立一个5个分片,一个副本的索引。这个索引就会完全分布在这两个节点上。如果再启动另外两个节点,node.attr.rack_id设置成r2,分片会重新分布,但是一个分片和它的副本不会分配到同样rack_id值的节点上。
可以为分片分布规则设置多个属性,例如:
cluster.routing.allocation.awareness.attributes: rack_id,zone
注意:当设置了分片分布属性时,如果集群中的节点没有设置其中任何一个属性,那么分片就不会分布到这个节点中。
强制分布规则 更多的时候,我们不想更多的副本被分布到相同分布规则属性值的一群节点上,那么,我们可以强制分片规则为一个指定的值。
例如,我们有一个分片规则属性叫zone,并且我们知道有两个zone,zone1和zone2。下面是设置:
cluster.routing.allocation.awareness.force.zone.values: zone1,zone2
cluster.routing.allocation.awareness.attributes: zone
现在我们启动两个node.zone设置成zone1的节点,然后创建一个5个分片,一个副本的索引。索引建立完成后只有5个分片(没有副本),只有当我们启动node.zone设置成zone2的节点时,副本才会分配到那节点上。
分片分布过滤
允许通过include/exclude过滤器来控制分片的分布。这些过滤器可以设置在索引级别上或集群级别上。下面是个索引级别上的例子:
假如我们有四个节点,每个节点都有一个叫tag(可以是任何名字)的属性。每个节点都指定一个tag的值。如:节点一设置成node.tag: value1,节点二设置成node.tag: value2,如此类推。我们可以创建一个索引然后只把它分布到tag值为value1和value2的节点中,可以通过设置index.routing.allocation.include.tag为value1,value2达到这样的效果,如:
PUT /test/_settings
{
"index.routing.allocation.include.tag" : "value1,value2"
}
与此相反,通过设置index.routing.allocation.exclude.tag为value3,我们也可以创建一个索引让其分布在除了tag设置为value3的所有节点中,如:
PUT /test/_settings
{
"index.routing.allocation.include.tag" : "value3"
}
include或exclude过滤器的值都会使用通配符来匹配,如value*。一个特别的属性名是_ip,它可以用来匹配节点的ip地址。
显然,一个节点可能拥有多个属性值,所有属性的名字和值都在配置文件中配置。如,下面是多个节点的配置:
node.group1: group1_value1
node.group2: group2_value4
同样的方法,include和exclude也可以设置多个值,如:
PUT /test/_settings
{
"index.routing.allocation.include.group1" : "xxx" ,
"index.routing.allocation.include.group1" : "yyy",
"index.routing.allocation. exclude.group1" : "zzz"
}
上面的设置可以通过索引更新的api实时更新到索引上,允许实时移动索引分片。
转载:https://cloud.tencent.com/developer/article/1648879
概述(推荐):https://www.cnblogs.com/zsql/p/13745772.html
推荐:
https://blog.csdn.net/wmg_fly/article/details/112986484
https://blog.csdn.net/liangwenmail/article/details/115378975
https://www.cnblogs.com/mikelaowang/p/13345318.html
实际生产工作中,我们经常会遇到集群日志索引特别大、日志分片特别多、近而导致集群数据索引、检索经常出现问题,比如:写入数据出现拒绝、查询超时、甚至出现分片丢失等情况,那么今天我们就以一个实际列子来讲讲这类问题的处理过程:
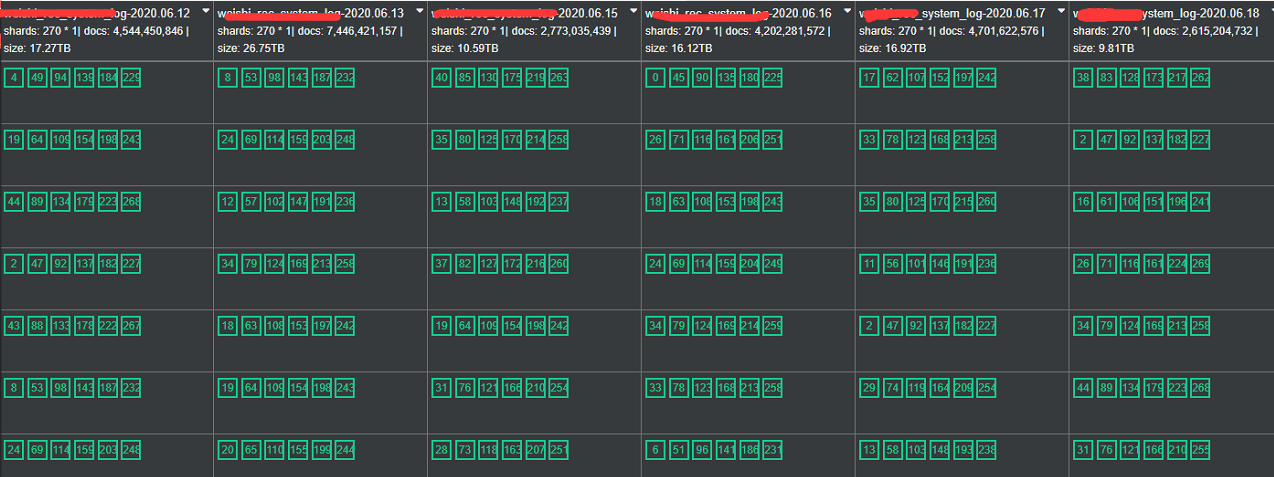
<1>这是日志收集的环境,索引属于时间序列,每个索引270主分片,索引大小从17T-27T左右不等;
<2>日志环境的索引分片应按照每个分片30G的大小进行分片,而我们发现这个环境中的分片有的达到来100G甚至200G的大小,索引的分片太大导致集群管理出现来问题;
<3> 集群读写出现reject现象,集群经常出现分片丢失的情况。符合文章开始提到的问题预期。
ES的索引本身没有大小限制一说,索引与分片的大小有关,索引分片的数量与ES集群的硬件配置有关。每个分片的数量根据业务场景来分,日志场景按照40G/分片,搜索场景按照20G/分片来定。而每个节点分片的数量我们一般按照1:20比列来定,也就是1G的堆内存对应20个主分片的设定,比如我这个节点是32G的堆内存,那么这个节点所能承担的最大的分片应该是32*20个分片。
在ES早期版本中,比如ES5我们可以通过Curator+Rollover实现大索引的自动化创建、管理,在ES6.6以后版本中提供了一个叫ilm<索引生命周期>功能,它可以结合rollover实现企业生产环境中大索引的自动滚动更新生成新索引的方式,这样就解决了单个索引过大造成的各种集群管理问题,本节我们将使用ILM+rollover实现大索引的滚动更新;
1,Rollover 与 时间序列的索引的实际场景
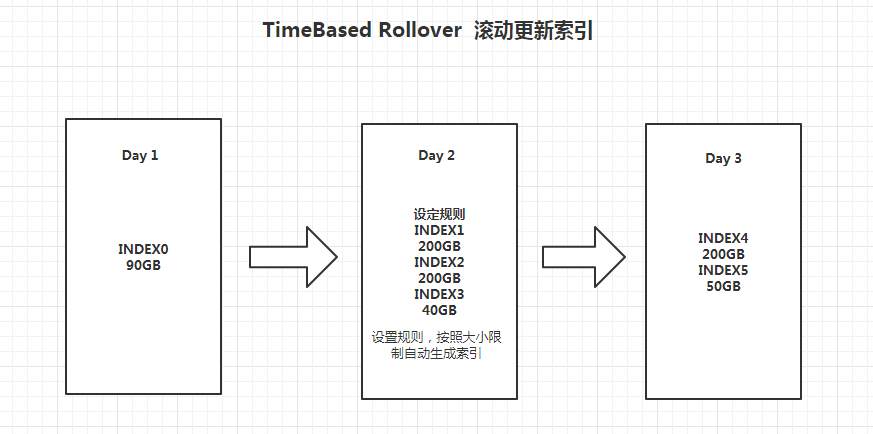
2,Rollover API 特点
<1> 当满足一系列的条件,Rollover API支持将一个 alias指向一个新的索引,它具有以下3个条件
A:存活的时间
B: 最大文档数
C: 最大文件尺寸
<2> 应用场景:当一个索引数据量过大
3,索引生命周期管理策略 Index Lifecle Management Policies
索引生命周期管理策略除了有冷热场景得使用外,在索引管理方面也有着非常大的实际应用。其支持基于大小和时间周期滚动,还支持定期删除,不用像老版本那样需要用户自己定义任务计划,非常好用。那么我们今天就以这个方法来解决这类大型索引的管理问题:那么我首先看一下大致的数据流程吧:
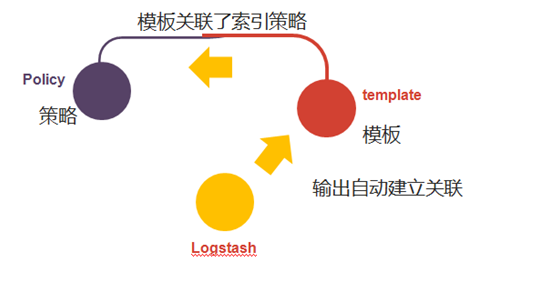
通过上图我们可以确定执行这个过程只需要3步:
第一步:创建索引生命周期策略,这个策略是基于rollover进行设置,
第二步:创建模板,匹配特定的索引并指定别名
第三步: logstash Output设置ILM;
鉴于企业ES生产环境索引数据比较大,我们可以设置当集群索引达到800G的时候滚动更新到下一个索引,按照上面的三步走策略:
第一步:创建ilm 策略:

第二步:定义模板,设置如下:
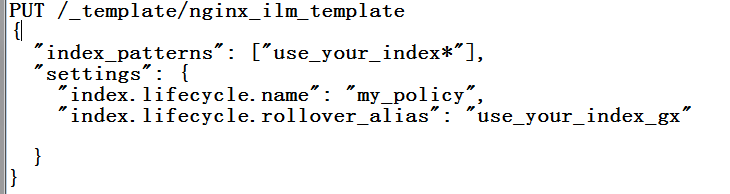
第三步:修改Logstash的输出设置,在output中添加如下参数:
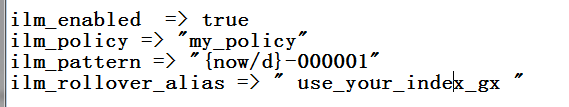
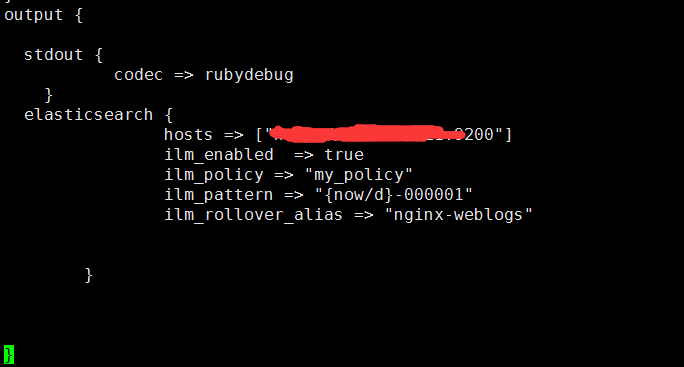

只需要以上3步这么设置,就可以实现从Logstash写入文件到index alias别名,然后索引根据策略自动按照规则滚动到下一个索引中。这里要注意:Rollover是针对索引别名进行管理的,通过对别名的写入管理自动滚动更新索引,做到了索引自动切换的作用。有效规避了大索引带来的管理问题,这样就保证了集群节点分片数据量的均匀分布。
在实际生产测试中,要注意模板索引别名跟Logstash Output配置别名的一致性。当然,可以在前期测试阶段使用手动滚动更新测试无误后再上生产环境。这里就不一一介绍。ES官网有详细的各个组建的文档介绍。
大致的流向就是这样,通过别名的形式实现数据索引的动态切换,如下图:
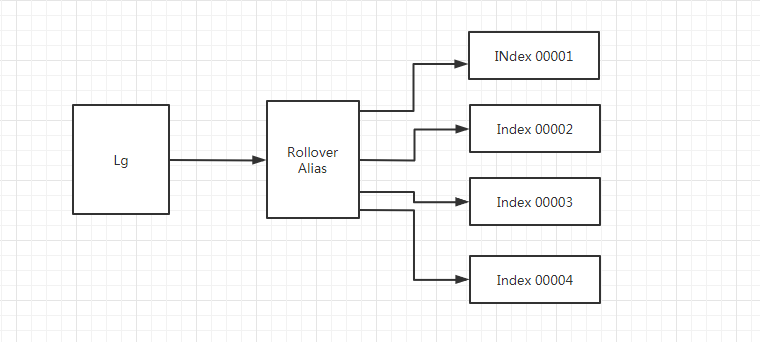 数据流向分析
数据流向分析
root@elasticsearch-0:/usr/share/elasticsearch# curl http://127.0.0.1:9200/log-000027/_ilm/explain?pretty
{
"indices" : {
"log-000027" : {
"index" : "log-000027",
"managed" : true,
"policy" : "policy-1",
"lifecycle_date_millis" : 1657265554555,
"age" : "2.7d",
"phase" : "warm",
"phase_time_millis" : 1657265555154,
"action" : "complete",
"action_time_millis" : 1657265555237,
"step" : "complete",
"step_time_millis" : 1657265555237,
"phase_execution" : {
"policy" : "policy-1",
"phase_definition" : {
"min_age" : "0d",
"actions" : {
"set_priority" : {
"priority" : 1
}
}
},
"version" : 3,
"modified_date_in_millis" : 1656688581070
}
}
}
}
root@elasticsearch-0:/usr/share/elasticsearch# curl http://127.0.0.1:9200/_ilm/policy/policy-1?pretty
{
"policy-1" : {
"version" : 3,
"modified_date" : "2022-07-01T15:16:21.070Z",
"policy" : {
"phases" : {
"hot" : {
"min_age" : "0ms",
"actions" : {
"rollover" : {
"max_size" : "30gb",
"max_age" : "7d"
},
"set_priority" : {
"priority" : 2
}
}
},
"delete" : {
"min_age" : "7d",
"actions" : {
"delete" : {
"delete_searchable_snapshot" : true
}
}
},
"warm" : {
"min_age" : "0d",
"actions" : {
"set_priority" : {
"priority" : 1
}
}
}
}
}
}
}
那么本节我们从一个实际生产环境的列子引出本节的重点,如何通过rollover+ilm的形式实现大型索引的规范化管理,保证ES集群的健壮稳定,此方法经过多套生产环境验证测试,测试无误,实为经验贴,希望能对有类似问题的朋友提供参考建议。因为本节并不属于基础知识的讲解。大家可以自行去ELasticsearch官方补齐相关知识。
通过本文你要了解:
1,ilm是ES6.6以后推出的新功能,可以在多种场景下使用。与冷热无关;
2,Rollover是对别名进行管理,与具体索引无关;
3, logstash本身CPU占用比较严重,这个现象可以值得关注、后续优化;
4,多种API的结合能有效管理集群中的大索引;