14 函数
def 函数名(参数…):
...
函数体
...
返回值
说明:
- def:表示定义函数的关键字。def语句将创建一个函数对象并将其赋值给一个变量名,这个变量名我们一般称之为“函数名“。
- 函数名:函数的名称,定义函数后根据函数名调用函数。
- 函数体:函数中进行一系列的逻辑计算,如:发送邮件、计算出 [11,22,38,888,2]中的最大数等…
- 参数:为函数体传递的数据,位于括号内,可省略。
- 返回值:当函数执行完毕后,可以给调用者返回数据。return关键字定义返回值,缺省返回None。注意,一旦遇到return语句,就会结束函数的执行跳出函数,即函数内部return语句后面函数体的其他部分不再执行。
- 局部变量:函数体中定义的变量为局部变量,作用域为整个函数体。建议局部变量使用小写。
- 全局变量:函数体外定义的变量为全局变量,所有的函数中都继承此变量值。如果函数中定义了与全局的变量同名的局部变量,则以局部变量优先生效。Python中,可以理解为同名的全局变量和局部变量为两个不同的变量,局部变量并没有修改全局变量的值。如果要让局部变量修改同名的全局变量,需要使用global关键字对函数体内的变量进行全局声明。例如global aa;aa=‘hello’,此时局部变量aa=‘hello’就会修改全局变量aa的值。建议全局变量使用大写。(这点与shell不同,shell在函数中定义的变量是本地变量,shell中的本地变量的作用域是整个shell脚本,而不是整个函数,不过可以使用local声明为局部变量,使之的作用域为整个函数)
1、函数定义在代码执行过程中是如何执行的?
当Python运行到def语句并执行了def语句时,它将会创建一个新的函数对象,封装这个函数的代码到这个对象中并将这个对象并赋值给变量名。python在运行函数定义代码时,只运行了def语句,然后将主体代码封装在该函数对象中。主体代码是在函数调用的时候才运行的。
2、在def运行之后,我们就可以调用函数了。如何调用?
可以在程序中通过在函数名后增加括号调用(运行)这个函数。括号中可以包含一个或多个对象参数,这些参数将会传递(赋值/引用)给函数头部的参数名。参数传递之后,函数的主体就开始运行。
函数定义中,形参定义顺序:def func(value,key=value,*args,kw-only[=value],**kwargs),Python的函数支持位置参数、默认值参数、任意参数、关键字参数。
在函数调用中,使用的最复杂的实参也就是func(value,key=value,*args,**kwargs)这个样子,虽然复杂但是最终可以解析为有两类参数:位置参数和关键字参数。因为*args本质也是位置参数,只不过它需要事先进行参数解包,解包后变成了位置参数;同理,**kwargs会被分解成关键字参数。在*args和**kwargs进行完参数解包之后,原先所有的参数就只有位置参数和关键字参数这两种了。
1、参数解包:我们首先将实参中的*args,**kwargs两种参数进行参数解包,*args会解包成一个value的列表并会append到原先的value列表中组合成一个新的value列表;**kwargs解包成key=value的列表。此时解包完成后,最终形成一个只有value,key=value两种形式的实参列表。
2、按顺序赋值:将第一步中的实参列表按照如下形参顺序进行赋值:kw-only,value,key=value,*args,**kwargs。在以上赋值过程中,我们先对kw-only进行赋值,然后拿实参的位置参数对value依次赋值,待形参中所有的有名称参数value都被赋值完后,剩余的位置参数会被组成一个名称为args的元组(*args,名为args的元组);再然后拿所有的关键字参数根据key值对key进行赋值,也会将赋值后剩余的key=value组合成一个名为kwargs的字典(**kwargs)。
- 实参中,多个位置参数之间是有先后顺序的,这也是他们被称之为位置参数的原因;多个关键字参数之间是没有先后顺序的,它们是通过key进行定位;但是所有的位置参数都必须在关键字参数之前。
- Keyword-Only参数在调用中只能使用关键字语法来传递。定义时要定义在
*args和**kwargs之间,调用时新版本对其位置不再限制。不过建议与定义时的顺序一致。Keyword-Only参数也分为有默认值和无默认值- 无论是def中还是函数调用中,value都要在key=value之前。
- Keyword-Only参数在调用中只能使用关键字语法来传递。定义时要定义在
*args和**kwargs之间,调用时新版本对其位置不再限制。不过建议与定义时的顺序一致。
def f(a,b,c):
print(a,b,c)
f(1,2,3) #位置参数,顺序匹配。精确地传递和函数头部参数名一样多的参数
f(b=2,c=3,a=1) #关键字参数,允许通过变量名进行匹配,而不是通过位置,所以位置可乱序\。精确地传递和函数头部参数名一样多的参数
f(1,c=3,b=2) #位置参数+关键字参数:位置参数必须位于关键字参数之前
def f(a,b,c=5,d=6): #默认参数:在所有的参数匹配之后,没有被匹配的参数将使用默认值。所以默认参数要在普通参数之后
print(a,b,c,d)
f(1,2,3,4) #1 2 3 4
f(1,2) #1 2 5 6
f(1,d=4,b=2) #1 2 5 4
f(b=2,a=1) #1 2 5 6
f(c=3,b=2,a=1) #1 2 3 6
def f(*args): #在函数定义中使用,将收集不匹配的位置参数定义在一个元组中
print(args)
f() #()
f(1) #(1,)
f(1,2,3,4) #(1, 2, 3, 4)
def f(**kwargs): #收集不匹配的关键字参数,将这些关键字参数传递给一个新的字典,例如本例的字典kwargs。在函数中可以对改字典进行调用
print(kwargs)
kwargs['a']=2 #对字典kwargs中的建'a'进行调用(赋值)
f() #{}
f(a=1,b=2) #{'a': 1, 'b': 2}
def f(a,*args,**kwargs): #一般参数(普通参数+默认字参数) + *参数 + **参数。注意顺序
print(a,args,kwargs)
f(1,2,3,4) #1 (2, 3, 4) {}
f(1,2,3,b=4,c=5) #1 (2, 3) {'b': 4, 'c': 5}
f(1,2,3,a=4,b=5,c=6) #TypeError: f() got multiple values for argument 'a'。a=1之后又赋值a=4导致错误
def f(a,d=5,*args,**kwargs): #在一般参数(包括普通参数和默认参数)匹配之后,将剩余的参数赋值给*args和**kwargs
print(a,args,kwargs,d)
f(1) #1 () {} 5
f(1,2,3,4) #1 (3, 4) {} 2
f(1,2,3,b=4,c=5) #1 (3,) {'b': 4, 'c': 5} 2
def f(a,b,c,d):
print(a,b,c,d)
args=[1,2,3,4]
error_args=[1,2,3,4,5]
kwargs={'a':1,'b':2,'c':3,'d':4}
f(*args) #1 2 3 4 ==>注意args元素个数要与函数的参数个数相同
f(**kwargs) #1 2 3 4
f(*error_args) #TypeError: f() takes 4 positional arguments but 5 were given
f(*(1,2),**{'c':3,'d':4}) #1 2 3 4
f(1,*(1,2),**{'d':4}) #1 1 2 4
f(1,*(2,3),d=4) #1 2 3 4
f(1,d=4,*(2,),**{'c':3}) #1 2 3 4
f(1,*(2,),d=4,**{'c':3}) #1 2 3 4 ==> 匹配顺序:位置参数>关键字参数>任意参数(*参数+**参数)
# 一个实用的例子:
def tracer(function, *pargs, **kargs):
print('calling:', function.__name__)
return function(*pargs, **kargs)
def func(a, b, c, d):
return a + b + c + d
print(tracer(func, 1, 2, c=3, d=4))
# calling: func
# 10
一个错误的赋值示例:
def f(a,b,c,d):
print a,b,c,d
f(2,3,4,a=1) #TypeError: f() got multiple values for keyword argument 'a'
# 这个例子说明了,先将2,3,4分别赋值给了a,b,c;然后再将a=1赋值给了a,所以a参数赋了两个值。
从语法上讲,keyword-only参数编码为“命名的参数”,出现在参数列表中的*args之后。Keyword-Only参数在调用中只能使用关键字语法来传递。
def f(a, *b, **d, c=6): #SyntaxError: invalid syntax
def f(a, *b, c=6, **d):
如果函数列表中不想使用任意参数,但是想使用Keyword-Only参数。我们也可以在参数列表中使用一个*字符来代替任意参数,但是参数列表不接受任意参数。
def kwonly(a, *b, c):
def kwonly(a, *, b, c):
def kwonly(a, *, b='spam', c='ham'):
例如定义函数def func(a,b,c,notify=**True**,*d)的参数列表中有一个参数notify是我们关注的,要么为True要么为False,但是我们可能被任意参数func(1,*(2,3,4,5,6))或位置参数func(1,2,3,4,5,6)给错误覆盖。为了避免这种覆盖,使用keyword-only参数def func(a,b,c,*d,notify=**True**),因为keyword-only参数会所有其他参数之前被赋值。
def kwonly(a, *b, c):
print(a, b, c)
kwonly(1, 2, c=3) #1 (2,) 3
kwonly(a=1, c=3) #1 () 3
kwonly(1, 2, 3) #TypeError: kwonly() missing 1 required keyword-only argument: 'c',c参数必须通过关键字方式赋值
def kwonly(a, *, b='spam', c='ham'): #具有默认值的 Keyword-Only参数
print(a, b, c)
kwonly(1) #1 spam ham
kwonly(1,b=2) #1 2 ham
kwonly(b=2,c=3,a=1) #1 2 3
kwonly(1,2,3) #TypeError: kwonly() takes 1 positional argument but 3 were given
局部变量(本地变量):所有在函数def语句(或者lambda表达式)内赋值的变量默认均为本地变量。换而言之,一个函数内部的任何类型的赋值都会把变量划定为本地变量。这里的赋值操作包括=语句、import中的模块名称、def中的函数名称、函数参数名称(因为函数参数在调用时也是通过赋值操作来传递的)等。如果在一个def中以任何方式赋值一个名称,这个名称的作用域都会对于该函数成为本地的。此外,注意原处改变对象并不会把变量划分为本地变量,实际上只有对变量名赋值才会。例如,如果变量名L在模块的顶层被赋值为一个列表,在函数内部的像L.append(X)这样的语句并不会将L划分为本地变量,而L=X却可以。修改一个对象并不是对一个名称赋值。
L1=[1,2,3] L2=[4,5,6] def f1(): L1.append(4) print(L1) def f2(): X=[7,8,9] L2=X L2.append(7) print(L2) f1() # [1, 2, 3, 4] print(L1) # [1, 2, 3, 4 f2() # [7, 8, 9, 7] print(L2) # [4, 5, 6]全局变量:在模块文件的顶层中(def语句之外)赋值的变量称之为全局变量,作用域为整个模块文件。如果在函数内使用global语句,可以将变量主动声明为全局变量。“全局”是相对于变量所在的这个模块文件而言,而不是针对所有的模块文件。如果想在该模块文件中使用其他模块文件A中的全局变量,可以将模块文件A导入(import)到该模块文件中。对于导入的外部模块文件的全局变量就成为一个模块对象的属性,但是能够像简单的变量一样使用(导入模块的作用域是全局的,每个模块都是一个全局作用域)。
函数中的变量和模块文件的顶层变量一样,变量的使用无需提前声明变量类型,可以直接进行赋值操作,但是函数中的变量默认属性为为局部变量,如果需要改变变量的属性,必须声明为非本地变量(nonlocal关键字用来在函数或其他作用域中使用外层(非全局)变量)和全局变量(global)去改变变量属性。
Python的变量名解析机制有时称为LEGB法则,这也是由作用域的命令而来的。 当在函数中使用未认证的变量名时,Python搜索4个作用域[本地作用域(L),之后是上一层结构中def或lambda的本地作用域(E),之后是全局作用域(G),最后是内置作用域(B)]并且在第一处能够找到这个变量名的地方停下来不在继续寻找。如果变量名在这次搜索中没有找到,Python会报错。变量名在使用前首先必须赋值过。 当在函数中给一个变量名赋值时(而不是在一个表达式中对其进行引用),Python总是创建或改变变量名的作用域为本地作用域,除非它已经在那个函数中声明为全局变量。 当在函数之外给一个变量名赋值时(也就是,在一个模块文件的顶层),本地作用域与全局作用域的范围(这个模块的命名空间)是相同的。

def scope_test(): def do_local(): spam = "local spam" # 此函数定义了另外的一个spam字符串变量,并且生命周期只在此函数内。 def do_nonlocal(): nonlocal spam # 使用外层的spam变量 spam = "nonlocal spam" def do_global(): global spam spam = "global spam" spam = "test spam" do_local() print("After local assignmane:", spam) # After local assignmane: test spam do_nonlocal() print("After nonlocal assignment:", spam) # After nonlocal assignment: nonlocal spam do_global() print("After global assignment:", spam) # After global assignment: nonlocal spam spam='Global' scope_test() print("In global scope:", spam) # In global scope: global spam导入的模块是全局作用域。一个模块文件的全局变量一旦被导入就成为了这个模块对象的一个属性:导入者自动得到了这个被导入的模块文件的所有全局变量的访问权,所以在一个文件被导入后,它的全局作用域实际上就构成了一个对象的属性。
# first.py X = 99 # This code doesn't know about second.py # second.py import first print(first.X) #99 first.X = 88 print(first.X) #88下例中,会报错“变量在声明前被引用”!
aa=10 def func(): print(aa) #UnboundLocalError: local variable 'aa' referenced before assignment aa=14 print(aa) func()分析:在python的函数中和全局同名的变量,如果你对该变量进行赋值操作就会变成局部变量,在修改之前对该变量的引用自然就会出现没定义这样的错误了,如果确定要引用全局变量,并且要对它修改,必须加上global关键字。
就像三元运算是简单的if-else语句的缩写形式一样,lambda表达式就是简单的自定义函数的缩写形式(等同简单的def语句);
匿名函数lambda就像def一样,这个表达式创建了一个之后能够调用的函数,但是它返回了一个函数对象而不是将这个函数赋值给一个变量名。这也就是lambda有时叫做匿名函数(也就是没有函数名)的原因。实际上,它们常常以一种行内进行函数定义的形式使用,或者用作推迟执行一些代码。
定义格式:
lambda关键字,冒号分割,分割对象为参数列表和返回值表达式
lambda arg1,… : 返回值表达式
我们可以把lambda表达式的结果赋值给一个变量,以便后续调用该函数:
函数名 = lambda arg1,… : 返回值表达式
示例:
sum2 = lambda a1,a2 : a1 + a2
a=sum2(5,6)
print(a)
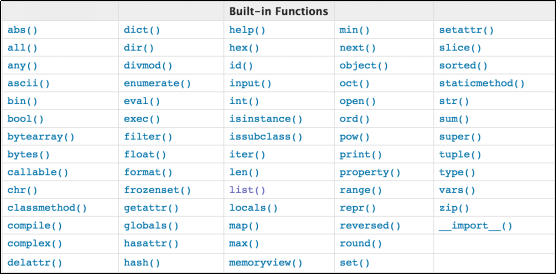
abs() #绝对值
all(iter,…) #循环iter的元素,如果所有元素都为真,则返回True。如果iter为空,也返回True。如:all([11,22,33,44,0]) ; all([])返回True
any(iter,…) #循环参数,只要其中一个元素为真,则返回True。
ascii(obj) #去对象obj的类中找__repr__方法,获取返回值。ascii()函数返回一个可打印的对象的字符串方式表示。当遇到非ASCII码时,就会输出\x,\u或\U等unicode码来表示。
repr(obj) #执行对象的__repr__方法 【representation描述】
>>> ascii('123abc李聚章def&')
"'123abc\\u674e\\u805a\\u7ae0def&'"
>>> repr('123abc李聚章def&')
"'123abc李聚章def&'"
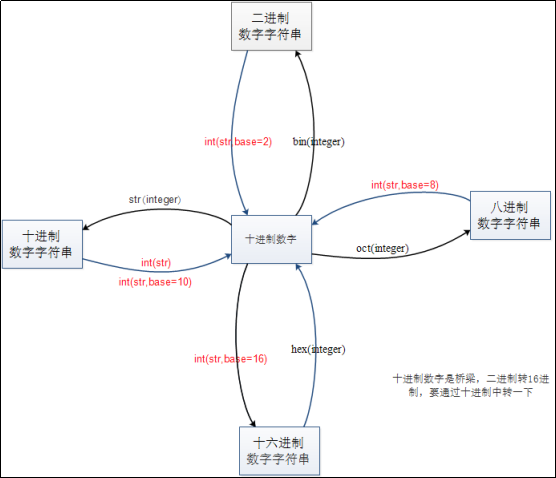
将10进制数字转换为其他进制的字符串:
bin(integer) #将10进制数字转换为2进制字符串 binary的缩写
oct(integer) #将10进制数字转换为8进制字符串 octal的缩写,['ɒktl]
hex(integer) #将10进制数字转换为16进制字符串 hexadecimal的缩写,[ˌheksəˈdesɪml]
>>> bin(3)
'0b11'
>>> oct(9)
'0o11'
>>> hex(17)
'0x11'
将其他进制数字字符串转换为10进制数字:
int('integer') 将10进制字符串或数字转换为10进制数字
int('xxx',base=x) 将x进制的数字字符串转换为10进制数字,默认base=10
>>> int('11',base=2) #将二进制的"111"转换为10进制
3
>>> int('0o11',base=8) #将八进制的"111"转换为10进制(前缀0o可以省略)
9
>>> int('11',base=16) #将十六进制的"111"转换为10进制
17
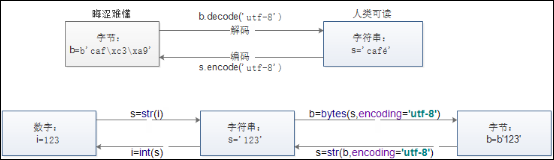
#字符串转换为字节
bytes(str, encoding=None) #函数返回一个新的bytes对象,该对象是一个 0 <= x < 256 区间内的整数不可变序列。它是 bytearray 的不可变版本。如果第一个参数为字符串str时,encoding参数也必须提供,函数将字符串使用str.encode方法转换成不可变的字节数组(字节是一种二进制的字符串,Python2中不区分bytes和str类型)
bytearray() #方法返回一个新字节数组。这个数组里的元素是可变的,并且每个元素的值范围: 0 <= x < 256。
#字节转字符串
str(bytes, encoding=None) #将字节转换为encoding编码的字符串
str(obj) #将对象转换为字符串(只有字符和字符串、文件才有编码??对象没有)
>>> bytes('中国',encoding="utf-8") #将utf-8编码的“中国”转为字节
b'\xe4\xb8\xad\xe5\x9b\xbd'
>>> str(b'\xe4\xb8\xad\xe5\x9b\xbd',encoding="utf-8") #将字节转换为utf-8编码的字符串
'中国'
>>> bytearray(3)
bytearray(b'\x00\x00\x00')
>>> str([1,2,3])
'[1, 2, 3]'
#bytes()用法总结(bytearray()类似):
#1、如果 source 为整数,则返回一个长度为 source 的初始化数组;
>>> bytes(3)
b'\x00\x00\x00'
#2、如果 source 为字符串,则按照指定的 encoding 将字符串转换为字节序列;
>>> bytes('中国',encoding="utf-8")
b'\xe4\xb8\xad\xe5\x9b\xbd'
#3、如果 source 为可迭代类型,则元素必须为[0 ,255] 中的整数;
>>> bytes([1,2,3])
b'\x01\x02\x03'
#4、如果没有输入任何参数,默认就是初始化数组为0个元素。
>>> bytes()
b''
字节与字符串的转换:
bytes是Python 3中特有的,Python 2 里不区分bytes和str类型。
- bytes是byte的序列,而str是unicode的序列。
- string使用str.encode()方法转化为 bytes
- bytes通过bytes.decode()转化为str
chr(int) #将整数int转换为ASCII对应的字符character,如chr(65)对应A
ord(char) #将单字符char转换为ASCII对应的整数,如ord('A')对应65 . ord是ordinal的缩写,序数
示例:利用随机数产生由大写字母和数字组合的4位验证码
import random
veri_code=''
for i in range(4):
m=random.randint(0,4) # random.randint(0,4)产生0-4之间的随机整数,包括0和4。
if m ==0 or m==3:
rand_num = random.randint(0, 9)
veri_code+=str(rand_num)
else:
rand_char = random.randint(65, 90)
veri_code=veri_code+chr(rand_char)
print(veri_code)
bool() #判断真假,将一个对象转换成布尔值
callable(obj) #判断对象obj是否可被调用,如果可以被调用,返回True。
delattr() #等同于del object.attr
getattr() #通过name字符串来,获取对象object的属性或者方法,如果存在打印出来,如果不存在,打印出默认值,默认值可选,缺省时为None。
hasattr() #判断一个对象里面是否有name属性或者name方法,返回BOOL值,有name特性返回True, 否则返回False。
setattr() #给对象的属性赋值,若属性不存在,先创建再赋值。等同于object.name = value
dir() #获取对象的属性
help() #获取帮助
divmod(a,b) #得到a/b的商c和余数d组成的元祖(c,d)。一般用于分页操作。
enumerate(iterable) #对于一个可迭代的(iterable)/可遍历的对象(如列表、字符串),enumerate将其组成一个索引序列,利用它可以同时获得索引和值。返回enumerate对象。
>>> list1 = ["这", "是", "一个", "测试"]
>>> for index, item in enumerate(list1):
... print(index,item)
...
0 这
1 是
2 一个
3 测试
eval() #执行字符串形式的表达式,有返回值。例如eval("3+4")
exec() #将字符串作为python代码执行,无返回值。例如exec("for i in range(5):print(i)")
filter(func,iter) #对元素进行过滤:将迭代对象的每个元素传递给函数,如果函数返回值为True,则filter返回iter的此元素。
map(func,iter) #元素映射:将迭代对象的每个元素传递给函数,函数返回值作为map对象的元素。
globals() #获取所有的全局变量(代码执行到当前位置的全部全局变量)
locals() #获取所有的局部变量
hash() #获取对象的hash值,经常用于将字典的key进行hash
id() #内存地址
input(“tips:”) #用户输入,返回对象类型为字符串
isinstance(obj,class) #判断对象类型。如果obj为class实例化而来,返回Ture,否则返回False。例如:isinstance(“hello”,str)返回True。
issubclass(subcls,parcls) #判断subcls是不是parcls的子类。返回值True/False
iter(obj) #迭代器对象,使用next()获取下一个元素。iter([11,22,33])
next()
max() #最大值。max([11,22,33,44])
min() #最小值
sum() #求和
open() #打开文件
pow() #求幂 pow(2,10),2的10次方。 power的缩写
reversed() #反转
round() #四舍五入
slice() #切片,基本不用
sorted() #排序(重点)
#同一种类型排序,不同类不能一起进行排序。
#数字排序:按大小顺序
#字符串排序:按照字符顺序按位比较,先比较第一个字符,当第一个字符相同时,再比较第二个,直到分出大小。单个字符排序时:数字形式的字符(数字大小)<纯字母(ASCII顺序)<汉字。
zip() #zip函数接受任意多个(包括0个和1个)序列作为参数,返回一个tuple列表(python3返回zip对象,可以使用list()转换为列表)。如果元素长度不一致会被砍到一样长。
>>>a = [1,2,3]
>>> b = [4,5,6]
>>> c = [4,5,6,7,8]
>>> zipped = zip(a,b) # 打包为元组的列表
[(1, 4), (2, 5), (3, 6)]
>>> zip(a,c) # 元素个数与最短的列表一致
[(1, 4), (2, 5), (3, 6)]
>>> zip(*zipped) # 与 zip 相反,可理解为解压,返回二维矩阵式
[(1, 2, 3), (4, 5, 6)]
__import__ #导入模块,并可以对导入的模块做别名。
imp = __import__(random)
imp.randint(0,5)
类似:
import random
random.randint(0,5)