Time Wait状态连接过多
由于TCP连接是全双工的,因此每个方向都必须单独进行关闭。其原则是当一方完成它的数据发送任务后就能发送一个FIN来终止这个方向的连接。收到一个FIN只意味着这一方向上没有数据流动,一个TCP连接在收到一个FIN后仍能发送数据。首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。
(1) TCP客户端发送一个FIN,用来关闭客户到服务器的数据传送(报文段1)。
(2) 服务器收到这个FIN,它发回一个ACK,确认序号为收到的序号加1(报文段2)。和SYN一样,一个FIN将占用一个序号。
(3) 服务器关闭客户端的连接,发送一个FIN给客户端(报文段3)。
(4) 客户段发回ACK报文确认,并将确认序号设置为收到序号加1(报文段4)。
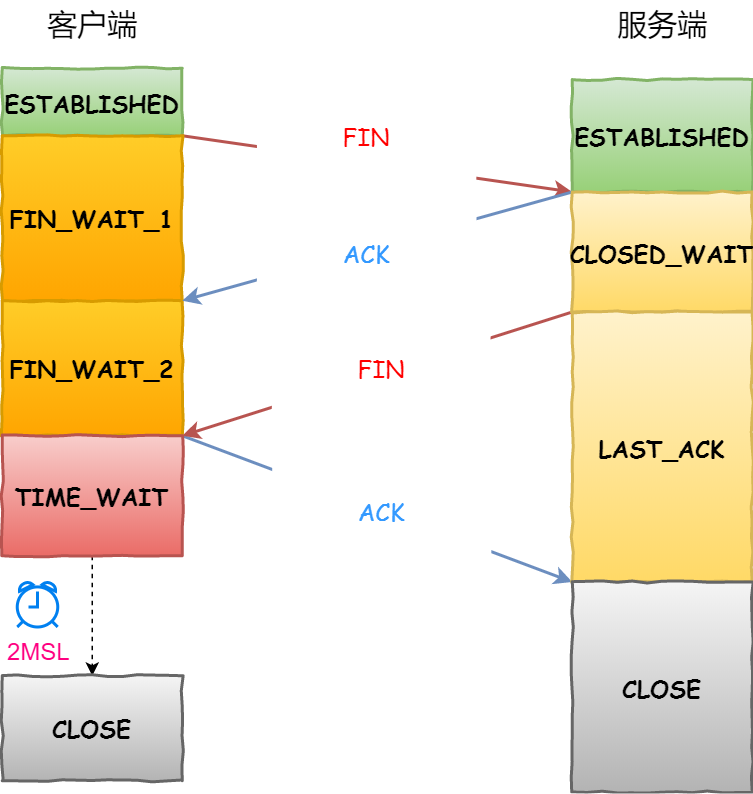
ESTABLISHED: 双方建立了连接。
FIN_WAIT_1: 这个状态要好好解释一下,其实FIN_WAIT_1和FIN_WAIT_2状态的真正含义都是表示等待对方的FIN报文。而这两种状态的区别是:FIN_WAIT_1状态实际上是当SOCKET在ESTABLISHED状态时,它想主动关闭连接,向对方发送了FIN报文,此时该SOCKET即进入到FIN_WAIT_1状态。而当对方回应ACK报文后,则进入到FIN_WAIT_2状态,当然在实际的正常情况下,无论对方何种情况下,都应该马上回应ACK报文,所以FIN_WAIT_1状态一般是比较难见到的,而FIN_WAIT_2状态还有时常常可以用netstat看到。
FIN_WAIT_2:上面已经详细解释了这种状态,实际上FIN_WAIT_2状态下的SOCKET,表示半连接,也即有一方要求close连接,但另外还告诉对方,我暂时还有点数据需要传送给你,稍后再关闭连接。
TIME_WAIT: 表示收到了对方的FIN报文,并发送出了ACK报文,就等2MSL后即可回到CLOSED可用状态了。如果FIN_WAIT_1状态下,收到了对方同时带FIN标志和ACK标志的报文时,可以直接进入到TIME_WAIT状态,而无须经过FIN_WAIT_2状态。
CLOSE_WAIT: 这种状态的含义其实是表示在等待关闭。怎么理解呢?当对方close一个SOCKET后发送FIN报文给自己,你系统毫无疑问地会回应一个ACK报文给对方,此时则进入到CLOSE_WAIT状态。接下来呢,实际上你真正需要考虑的事情是察看你是否还有数据发送给对方,如果没有的话,那么你也就可以close这个SOCKET,发送FIN报文给对方,也即关闭连接。所以你在CLOSE_WAIT状态下,需要完成的事情是等待你去关闭连接。
LAST_ACK: 这个状态还是比较容易好理解的,它是被动关闭一方在发送FIN报文后,最后等待对方的ACK报文。当收到ACK报文后,也即可以进入到CLOSED可用状态了。
我们可以看到,主动关闭方在接收到对方发送的FIN报文后会进入TIME_WAIT状态等待2MSL时长。
RFC 793协议中给出的建议是两分钟,不过实际上不同的操作系统可能有不同的设置,以Linux为例,通常是半分钟,两倍的MSL就是一分钟,也就是60秒,
- 为实现TCP全双工连接的可靠释放
- 为使旧的数据包在网络因过期而消失
1.为实现TCP全双工连接的可靠释放
**TIME_WAIT是为了等待足够的时间以确保主动关闭方最后发送的ACK能够让被动关闭方接受,从而使其正确关闭。**由TCP状态变迁图可知,假设发起主动关闭的一方(client)最后发送的ACK在网络中丢失,由于TCP协议的重传机制,执行被动关闭的一方(server)将会重发其FIN,在该FIN到达client之前,client必须维护这条连接状态,也就说这条TCP连接所对应的资源(client方的local_ip,local_port)不能被立即释放或重新分配,直到另一方重发的FIN达到之后,client重发ACK后,经过2MSL时间周期没有再收到另一方的FIN之后,该TCP连接才能恢复初始的CLOSED状态。如果主动关闭一方不维护这样一个TIME_WAIT状态,那么当被动关闭一方重发的FIN到达时,主动关闭一方的TCP传输层会用RST包响应对方,这会被对方认为是有错误发生,然而这事实上只是正常的关闭连接过程,并非异常。
2.为使旧的数据包在网络因过期而消失
TIME_WAIT状态会持续2MSL时长,这个时长足以让两个方向上的数据包都被丢弃,使得原来连接的数据包在网络中都自然消失。再出现的数据包一定就是新连接产生的。
MSL(Maximum Segment Lifetime)最大报文生存时间:每个TCP实现必须选择一个MSL。它是任何报文段被丢弃前在网络内的最长时间。这个时间是有限的,因为TCP报文段以IP数据报在网络内传输,而IP数据报则有限制其生存时间的TTL时间。RFC 793指出MSL为2分钟,现实中常用30秒或1分钟。
为说明这个问题,我们先假设TCP协议中不存在TIME_WAIT状态的限制,再假设当前有一条TCP连接:(local_ip, local_port, remote_ip,remote_port),因某些原因,我们先关闭,接着很快以相同的四元组建立一条新连接。而TCP连接由四元组唯一标识,因此,在我们假设的情况中,TCP协议栈是无法区分前后两条TCP连接的不同的,在它看来,这根本就是同一条连接,中间先释放再建立的过程对其来说是“感知”不到的。这样就可能发生这样的情况:前一条TCP连接由其中一方发送的数据到达另外一方后,会被这一方的TCP传输层当做当前TCP连接的正常数据接收并向上传递至应用层(而事实上,在我们假设的场景下,这些旧数据到达前,旧连接已断开且一条由相同四元组构成的新TCP连接已建立,因此,这些旧数据是不应该被向上传递至应用层的),从而引起数据错乱进而导致各种无法预知的诡异现象。作为一种可靠的传输协议,TCP必须在协议层面考虑并避免这种情况的发生,这正是TIME_WAIT状态存在的第2个原因。
TIME_WAIT状态是TCP链接中正常产生的一个状态,但凡事都有利弊,TIME_WAIT状态过多会存在以下的问题:
内存资源占用:大量的time_wait状态也会系统一定的fd,内存和cpu资源,当然这个量一般比较小,并不是主要危害
对端口资源的占用,一个 TCP 连接至少消耗"发起连接方"的一个本地端口;
第二个危害是会造成严重的后果的,要知道,端口资源也是有限的,一般可以开启的端口为 32768~61000,也可以通过如下参数设置指定:
net.ipv4.ip_local_port_range = 32768 61000
如果“发起连接方”的 TIME_WAIT 状态过多,占满了所有端口资源,则会导致无法创建新连接。
- 客户端(发起连接方)受端口资源限制:
客户端TIME_WAIT过多,在socket的TIME_WAIT状态结束之前,该socket所占用的本地端口号将一直无法释放。在高并发(每秒几万qps)并且采用短连接方式进行交互的系统中运行一段时间后,系统中就会存在大量的time_wait状态,如果time_wait状态把系统所有可用端口都占完了且尚未被系统回收时,就会出现无法向服务端创建新的socket连接的情况。此时系统几乎停转,任何链接都不能建立。端口就 65536 个,被占满就会导致无法创建新的连接。
- 服务端(被动连接方)受系统资源限制:
由于一个四元组表示 TCP 连接,理论上服务端可以建立很多连接,因为服务端只监听一个端口,不会因为 TCP连接过多而导致端口资源受限。但是 TCP 连接过多,会占用系统资源,比如文件描述符、内存资源、CPU 资源、线程资源等,当然这个量一般比较小,并不是主要危害。
说明:
TCP 连接使用一个四元组表示,所以客户端可以使用同一个ip+port去连接不同的服务器。例如下图中使用172.16.0.21:50001分别与3台服务器的22端口创建了连接。
详细参考:https://www.zhihu.com/question/361111920/answer/1828767342

参考:
内核参数:https://developer.aliyun.com/article/473735
关于net.ipv4.tcp_timestamps:https://blog.csdn.net/qq_42168438/article/details/121943726
nginx参数:https://blog.csdn.net/weixin_39590058/article/details/105681569
其他:https://blog.csdn.net/weixin_35794072/article/details/116632249
https://developer.aliyun.com/article/473735
我们用vim打开配置文件:
#vim /etc/sysctl.conf
然后,在这个文件中,加入下面的几行内容:
net.ipv4.tcp_syncookies = 1 net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_tw_recycle = 1 net.ipv4.tcp_fin_timeout = 30
最后输入下面的命令,让内核参数生效:
#/sbin/sysctl -p
简单的说明下,上面的参数的含义:
net.ipv4.tcp_syncookies = 1 表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭; net.ipv4.tcp_tw_reuse = 1 表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭; net.ipv4.tcp_tw_recycle = 1 表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭;(4.12内核中被移除) net.ipv4.tcp_fin_timeout 修改系統默认的 TIMEOUT 时间。
在经过这样的调整之后,除了会进一步提升服务器的负载能力之外,还能够防御一定程度的DDoS、CC和SYN攻击,是个一举两得的做法。
此外,如果你的连接数本身就很多,我们可以再优化一下TCP/IP的可使用端口范围,进一步提升服务器的并发能力。依然是往上面的参数文件中,加入下面这些配置:
net.ipv4.tcp_keepalive_time = 1200 net.ipv4.ip_local_port_range = 10000 65000 net.ipv4.tcp_max_syn_backlog = 8192 net.ipv4.tcp_max_tw_buckets = 5000
这几个参数,建议只在流量非常大的服务器上开启,会有显著的效果。一般的流量小的服务器上,没有必要去设置这几个参数。这几个参数的含义如下:
net.ipv4.tcp_keepalive_time = 1200 表示当keepalive起用的时候,TCP发送keepalive消息的频度。缺省是2小时,改为20分钟。 net.ipv4.ip_local_port_range = 10000 65000 表示用于向外连接的端口范围。缺省情况下很小:32768到61000,改为10000到65000。(注意:这里不要将最低值设的太低,否则可能会占用掉正常的端口!) net.ipv4.tcp_max_syn_backlog = 8192 表示SYN队列的长度,默认为1024,加大队列长度为8192,可以容纳更多等待连接的网络连接数。 net.ipv4.tcp_max_tw_buckets = 5000 表示系统同时保持TIME_WAIT的最大数量,如果超过这个数字,TIME_WAIT将立刻被清除并打印警告信息。默 认为180000,改为5000。对于Apache、Nginx等服务器,上几行的参数可以很好地减少TIME_WAIT套接字数量,但是对于 Squid,效果却不大。此项参数可以控制TIME_WAIT的最大数量,避免Squid服务器被大量的TIME_WAIT拖死。
经过这样的配置之后,你的服务器的TCP/IP并发能力又会上一个新台阶。
推荐阅读:https://blog.csdn.net/qq_42168438/article/details/121965593
方案1:net.ipv4.ip_local_port_range + net.ipv4.tcp_tw_reuse
vim /etc/sysctl.conf
net.ipv4.ip_local_port_range = 10000 61000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_timestamps = 1
方案2:net.ipv4.ip_local_port_range + net.ipv4.tcp_max_tw_buckets
vi /etc/sysctl.conf
net.ipv4.ip_local_port_range = 10000 61000
# 关闭reuse
net.ipv4.tcp_tw_reuse = 0
net.ipv4.tcp_max_tw_buckets = 50000
net.ipv4.tcp_timestamps = 1
短连接和长连接工作方式的区别:
- 短连接
连接->传输数据->关闭连接 HTTP是无状态的,浏览器和服务器每进行一次HTTP操作,就建立一次连接,但任务结束就中断连接。 也可以这样说:短连接是指SOCKET连接后发送后接收完数据后马上断开连接。
- 长连接
连接->传输数据->保持连接 -> 传输数据-> 。。。->关闭连接。 长连接指建立SOCKET连接后不管是否使用都保持连接,但安全性较差。
从区别上可以看出,长连接比短连接从根本上减少了关闭连接的次数,减少了TIME_WAIT状态的产生数量,在高并发的系统中,这种方式的改动非常有效果,可以明显减少系统TIME_WAIT的数量。
当使用nginx作为反向代理时,为了支持长连接,需要做到两点:
从client到nginx的连接是长连接 从nginx到server的连接是长连接
默认情况下,nginx已经自动开启了对client连接的keep alive支持(同时client发送的HTTP请求要求keep alive)。一般场景可以直接使用,但是对于一些比较特殊的场景,还是有必要调整个别参数(keepalive_timeout和keepalive_requests)。
http {
keepalive_timeout 120s 120s;
keepalive_requests 10000;
}
- keepalive_timeout的第一个参数:设置keep-alive客户端连接在服务器端保持开启的超时值(默认75s);值为0会禁用keep-alive客户端连接;
- keepalive_timeout的第二个参数:可选、在响应的header域中设置一个值“Keep-Alive: timeout=time”;通常可以不用设置;
为了让nginx和后端server(nginx称为upstream)之间保持长连接,典型设置如下:(默认nginx访问后端都是用的短连接(HTTP1.0),一个请求来了,Nginx 新开一个端口和后端建立连接,后端执行完毕后主动关闭该链接)Nginx 1.1以上版本的upstream已经支持keep-alive的,所以我们可以开启Nginx proxy的keep-alive来减少tcp连接:
upstream http_backend {
server 127.0.0.1:8080;
keepalive 1000; #设置nginx到upstream服务器的空闲keepalive连接的最大数量
}
server {
...
location /http/ {
proxy_pass http://http_backend;
proxy_http_version 1.1; #开启长链接
proxy_set_header Connection "";
...
}
}
优化Linux下的内核TCP参数来提高服务器负载能力:https://blog.51cto.com/birdinroom/1600709
https://blog.csdn.net/lianggx3/article/details/118498840 https://blog.csdn.net/ccw_922/article/details/124578396 https://blog.csdn.net/weixin_44718794/article/details/108649255 https://blog.csdn.net/weixin_39590058/article/details/105681569
https://blog.csdn.net/qq_42168438/article/details/121965593
大家好,我是小林。
上周有个读者在面试微信的时候,被问到既然打开 net.ipv4.tcp_tw_reuse 参数可以快速复用处于 TIME_WAIT 状态的 TCP 连接,那为什么 Linux 默认是关闭状态呢?

好家伙,真的问好细节!
当时看到读者这个问题的时候,我也是一脸懵逼的,经过我的一番思考后,终于知道怎么回答这题了。
其实这题在变相问「如果 TIME_WAIT 状态持续时间过短或者没有,会有什么问题?」
因为开启 tcp_tw_reuse 参数可以快速复用处于 TIME_WAIT 状态的 TCP 连接时,相当于缩短了 TIME_WAIT 状态的持续时间。
可能有的同学会问说,使用 tcp_tw_reuse 快速复用处于 TIME_WAIT 状态的 TCP 连接时,是需要保证 net.ipv4.tcp_timestamps 参数是开启的(默认是开启的),而 tcp_timestamps 参数可以避免旧连接的延迟报文,这不是解决了没有 TIME_WAIT 状态时的问题了吗?
是解决部分问题,但是不能完全解决,接下来,我跟大家聊聊这个问题。
TCP 四次挥手过程,如下图:
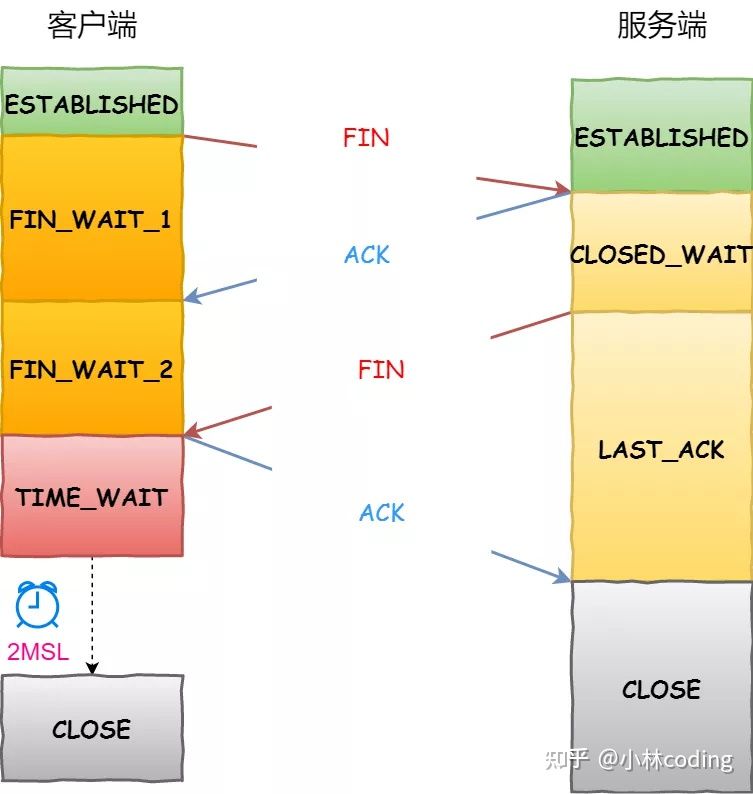
- 客户端打算关闭连接,此时会发送一个 TCP 首部
FIN标志位被置为1的报文,也即FIN报文,之后客户端进入FIN_WAIT_1状态。 - 服务端收到该报文后,就向客户端发送
ACK应答报文,接着服务端进入CLOSED_WAIT状态。 - 客户端收到服务端的
ACK应答报文后,之后进入FIN_WAIT_2状态。 - 等待服务端处理完数据后,也向客户端发送
FIN报文,之后服务端进入LAST_ACK状态。 - 客户端收到服务端的
FIN报文后,回一个ACK应答报文,之后进入TIME_WAIT状态 - 服务器收到了
ACK应答报文后,就进入了CLOSE状态,至此服务端已经完成连接的关闭。 - 客户端在经过
2MSL一段时间后,自动进入CLOSE状态,至此客户端也完成连接的关闭。
你可以看到,两个方向都需要一个 FIN 和一个 ACK,因此通常被称为四次挥手。
这里一点需要注意是:主动关闭连接的,才有 TIME_WAIT 状态。
可以看到,TIME_WAIT 是「主动关闭方」断开连接时的最后一个状态,该状态会持续 *2MSL(Maximum Segment Lifetime)* 时长,之后进入CLOSED 状态。
MSL 指的是 TCP 协议中任何报文在网络上最大的生存时间,任何超过这个时间的数据都将被丢弃。虽然 RFC 793 规定 MSL 为 2 分钟,但是在实际实现的时候会有所不同,比如 Linux 默认为 30 秒,那么 2MSL 就是 60 秒。
MSL 是由网络层的 IP 包中的 TTL 来保证的,TTL 是 IP 头部的一个字段,用于设置一个数据报可经过的路由器的数量上限。报文每经过一次路由器的转发,IP 头部的 TTL 字段就会减 1,减到 0 时报文就被丢弃。
MSL 与 TTL 的区别:MSL 的单位是时间,而 TTL 是经过路由跳数。所以 MSL 应该要大于等于 TTL 消耗为 0 的时间,以确保报文已被自然消亡。
TTL 的值一般是 64,Linux 将 MSL 设置为 30 秒,意味着 Linux 认为数据报文经过 64 个路由器的时间不会超过 30 秒,如果超过了,就认为报文已经消失在网络中了。
设计 TIME_WAIT 状态,主要有两个原因:
- 防止历史连接中的数据,被后面相同四元组的连接错误的接收;
- 保证「被动关闭连接」的一方,能被正确的关闭;
为了能更好的理解这个原因,我们先来了解序列号(SEQ)和初始序列号(ISN)。
- 序列号,是 TCP 一个头部字段,标识了 TCP 发送端到 TCP 接收端的数据流的一个字节,因为 TCP 是面向字节流的可靠协议,为了保证消息的顺序性和可靠性,TCP 为每个传输方向上的每个字节都赋予了一个编号,以便于传输成功后确认、丢失后重传以及在接收端保证不会乱序。序列号是一个 32 位的无符号数,因此在到达 4G 之后再循环回到 0。
- 初始序列号,在 TCP 建立连接的时候,客户端和服务端都会各自生成一个初始序列号,它是基于时钟生成的一个随机数,来保证每个连接都拥有不同的初始序列号。初始化序列号可被视为一个 32 位的计数器,该计数器的数值每 4 微秒加 1,循环一次需要 4.55 小时。
给大家抓了一个包,下图中的 Seq 就是序列号,其中红色框住的分别是客户端和服务端各自生成的初始序列号。
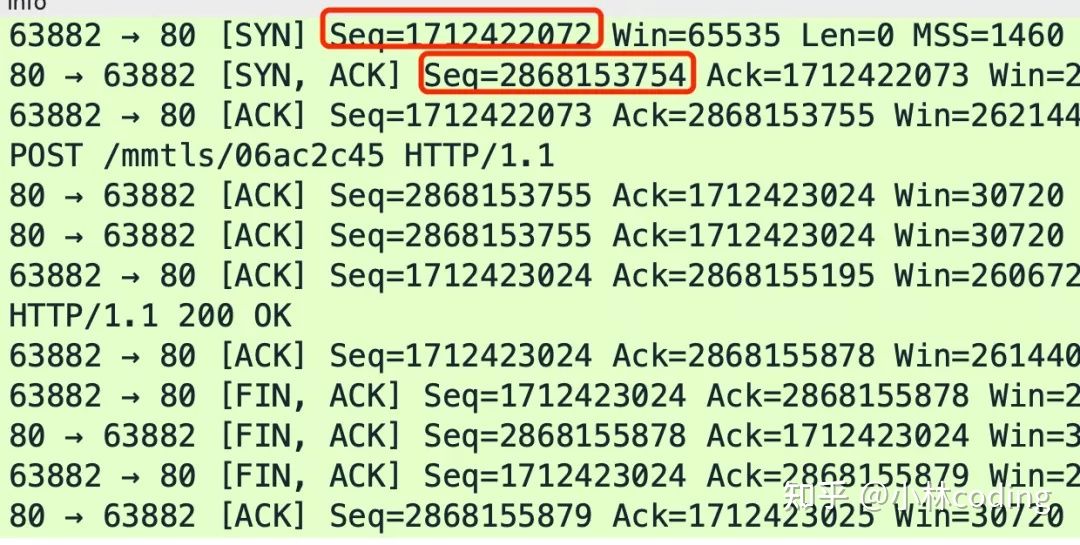
通过前面我们知道,序列号和初始化序列号并不是无限递增的,会发生回绕为初始值的情况,这意味着无法根据序列号来判断新老数据。
假设 TIME-WAIT 没有等待时间或时间过短,被延迟的数据包抵达后会发生什么呢?
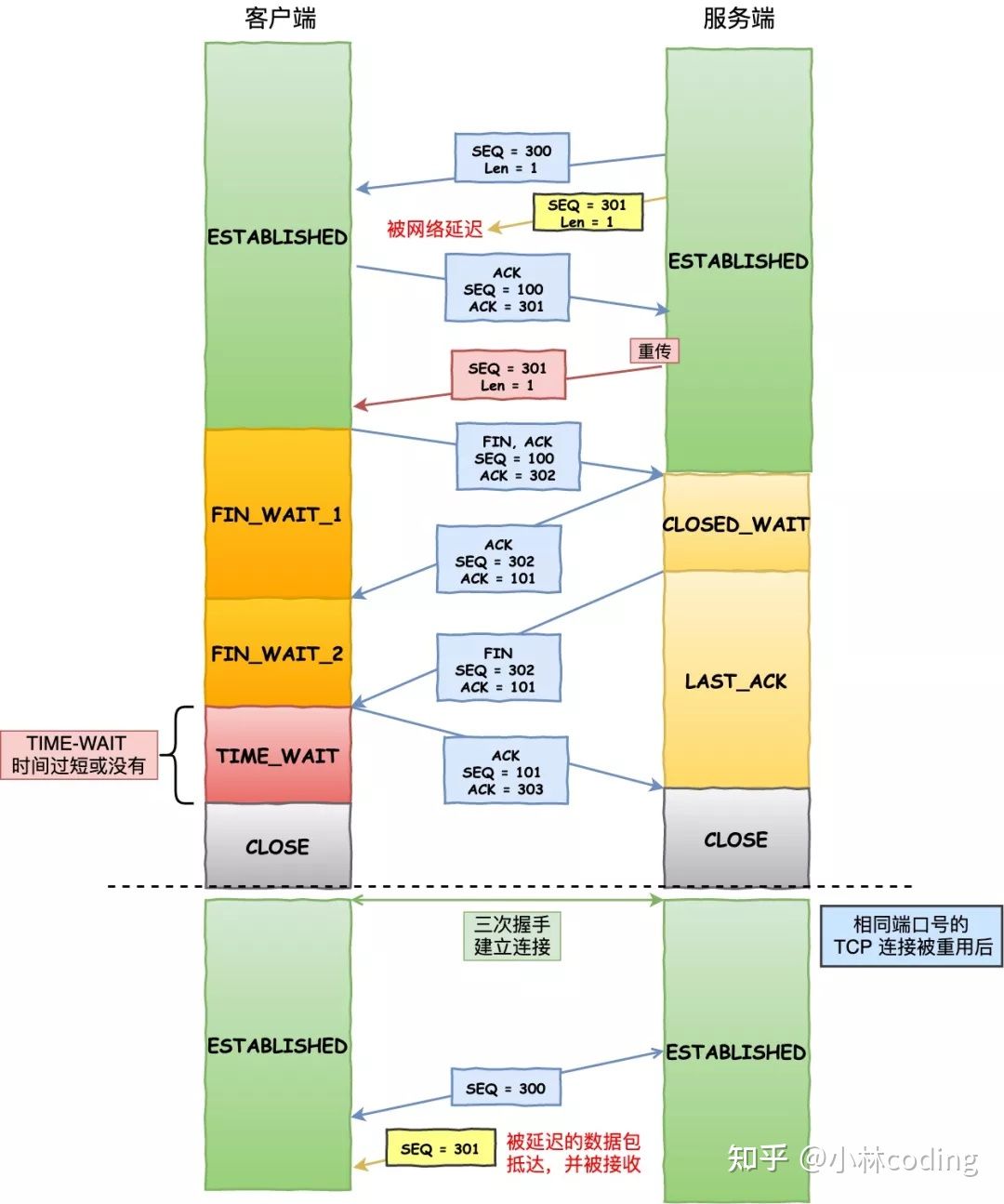
- 服务端在关闭连接之前发送的
SEQ = 301报文,被网络延迟了。 - 接着,服务端以相同的四元组重新打开了新连接,前面被延迟的
SEQ = 301这时抵达了客户端,而且该数据报文的序列号刚好在客户端接收窗口内,因此客户端会正常接收这个数据报文,但是这个数据报文是上一个连接残留下来的,这样就产生数据错乱等严重的问题。
为了防止历史连接中的数据,被后面相同四元组的连接错误的接收,因此 TCP 设计了 TIME_WAIT 状态,状态会持续 2MSL 时长,这个时间足以让两个方向上的数据包都被丢弃,使得原来连接的数据包在网络中都自然消失,再出现的数据包一定都是新建立连接所产生的。
如果客户端(主动关闭方)最后一次 ACK 报文(第四次挥手)在网络中丢失了,那么按照 TCP 可靠性原则,服务端(被动关闭方)会重发 FIN 报文。
假设客户端没有 TIME_WAIT 状态,而是在发完最后一次回 ACK 报文就直接进入 CLOSED 状态,如果该 ACK 报文丢失了,服务端则重传的 FIN 报文,而这时客户端已经进入到关闭状态了,在收到服务端重传的 FIN 报文后,就会回 RST 报文。
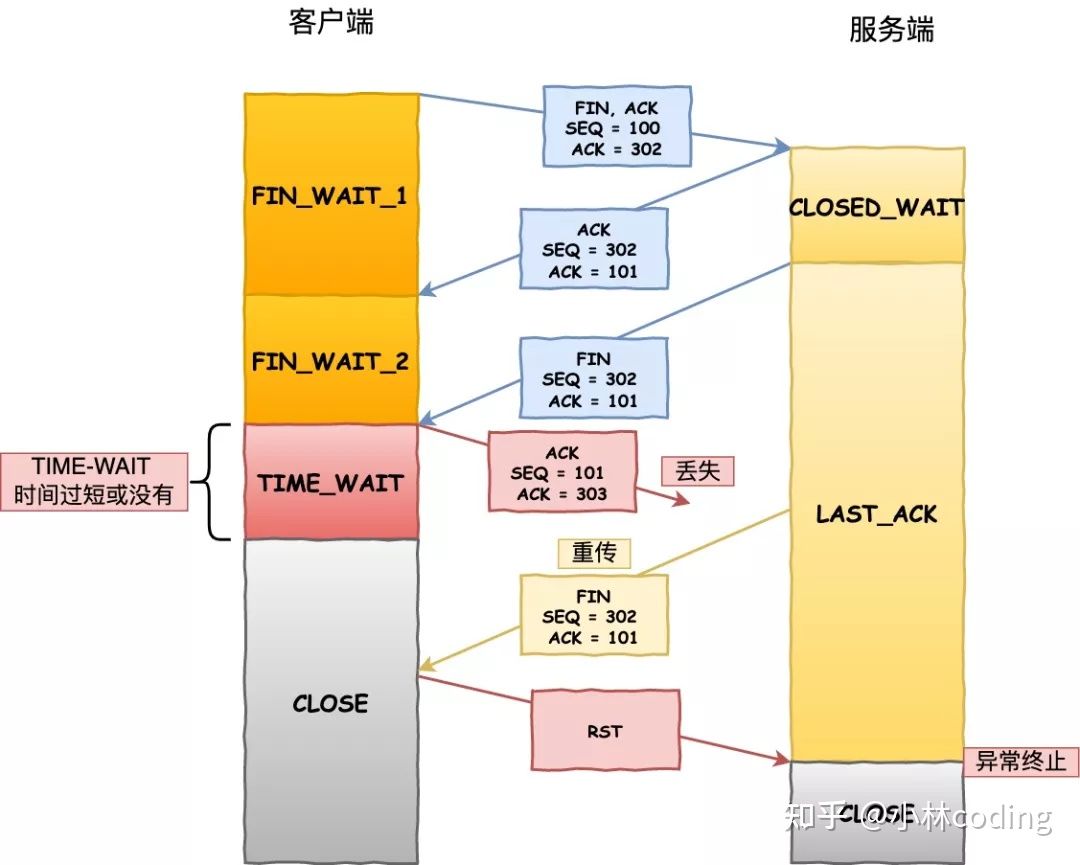
服务端收到这个 RST 并将其解释为一个错误(Connection reset by peer),这对于一个可靠的协议来说不是一个优雅的终止方式。
为了防止这种情况出现,客户端必须等待足够长的时间确保对端收到 ACK,如果对端没有收到 ACK,那么就会触发 TCP 重传机制,服务端会重新发送一个 FIN,这样一去一来刚好两个 MSL 的时间。
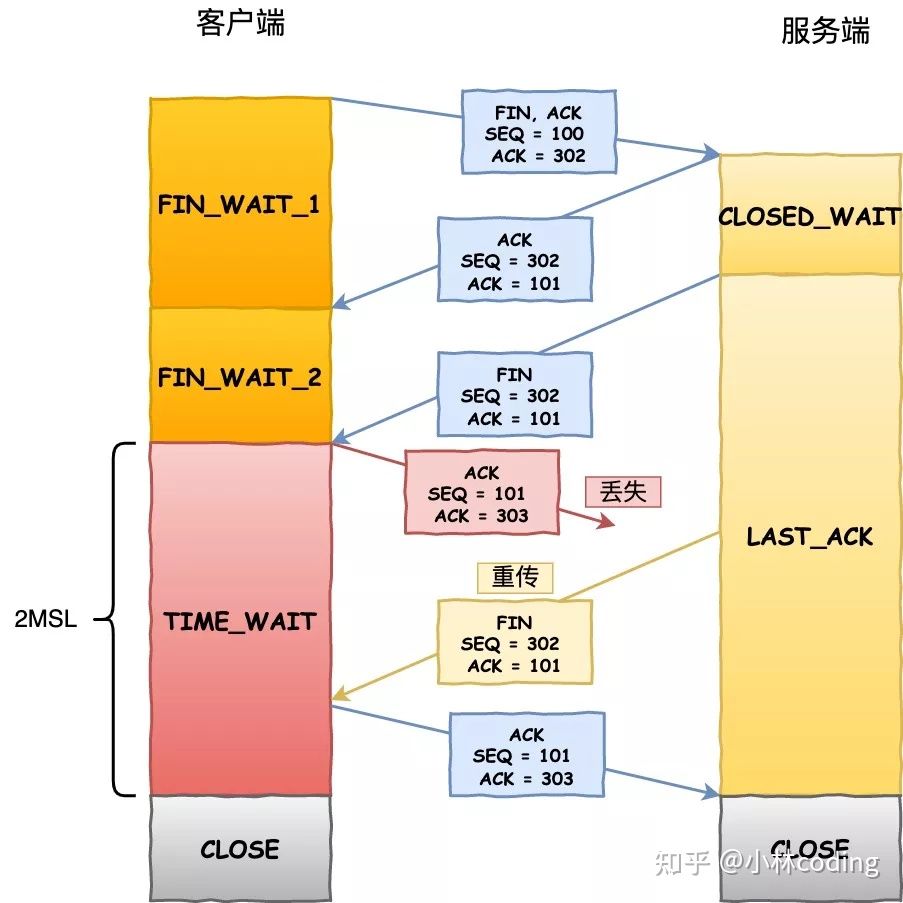
但是你可能会说重新发送的 ACK 还是有可能丢失啊,没错,但 TCP 已经等待了那么长的时间了,已经算仁至义尽了。
在 Linux 操作系统下,TIME_WAIT 状态的持续时间是 60 秒,这意味着这 60 秒内,客户端一直会占用着这个端口。要知道,端口资源也是有限的,一般可以开启的端口为 32768~61000 ,也可以通过如下参数设置指定范围:
net.ipv4.ip_local_port_range
那么,如果如果主动关闭连接方的 TIME_WAIT 状态过多,占满了所有端口资源,则会导致无法创建新连接。
不过,Linux 操作系统提供了两个可以系统参数来快速回收处于 TIME_WAIT 状态的连接,这两个参数都是默认关闭的:
- net.ipv4.tcp_tw_reuse,如果开启该选项的话,客户端(连接发起方) 在调用 connect() 函数时,内核会随机找一个 TIME_WAIT 状态超过 1 秒的连接给新的连接复用,所以该选项只适用于连接发起方。
- net.ipv4.tcp_tw_recycle,如果开启该选项的话,允许处于 TIME_WAIT 状态的连接被快速回收,该参数在 **NAT 的网络下是不安全的!**详细见这篇文章介绍:字节面试:SYN 报文什么时候情况下会被丢弃?
要使得上面这两个参数生效,有一个前提条件,就是要打开 TCP 时间戳,即 net.ipv4.tcp_timestamps=1(默认即为 1)。
开启了 tcp_timestamps 参数,TCP 头部就会使用时间戳选项,它有两个好处,一个是便于精确计算 RTT ,另一个是能防止序列号回绕(PAWS),我们先来介绍这个功能。
序列号是一个 32 位的无符号整型,上限值是 4GB,超过 4GB 后就需要将序列号回绕进行重用。这在以前网速慢的年代不会造成什么问题,但在一个速度足够快的网络中传输大量数据时,序列号的回绕时间就会变短。如果序列号回绕的时间极短,我们就会再次面临之前延迟的报文抵达后序列号依然有效的问题。
为了解决这个问题,就需要有 TCP 时间戳。
试看下面的示例,假设 TCP 的发送窗口是 1 GB,并且使用了时间戳选项,发送方会为每个 TCP 报文分配时间戳数值,我们假设每个报文时间加 1,然后使用这个连接传输一个 6GB 大小的数据流。

32 位的序列号在时刻 D 和 E 之间回绕。假设在时刻B有一个报文丢失并被重传,又假设这个报文段在网络上绕了远路并在时刻 F 重新出现。如果 TCP 无法识别这个绕回的报文,那么数据完整性就会遭到破坏。
使用时间戳选项能够有效的防止上述问题,如果丢失的报文会在时刻 F 重新出现,由于它的时间戳为 2,小于最近的有效时间戳(5 或 6),因此防回绕序列号算法(PAWS)会将其丢弃。
防回绕序列号算法要求连接双方维护最近一次收到的数据包的时间戳(Recent TSval),每收到一个新数据包都会读取数据包中的时间戳值跟 Recent TSval 值做比较,如果发现收到的数据包中时间戳不是递增的,则表示该数据包是过期的,就会直接丢弃这个数据包。
通过前面这么多铺垫,终于可以说这个问题了。
开启 tcp_tw_reuse 会有什么风险呢?我觉得会有 2 个问题。
我们知道开启 tcp_tw_reuse 的同时,也需要开启 tcp_timestamps,意味着可以用时间戳的方式有效的判断回绕序列号的历史报文。
但是在看我看了防回绕序列号算法的源码后,发现对于 RST 报文的时间戳即使过期了,只要 RST 报文的序列号在对方的接收窗口内,也是能被接受的。
下面 tcp_validate_incoming 函数就是验证接收到的 TCP 报文是否合格的函数,其中第一步就会进行 PAWS 检查,由 tcp_paws_discard 函数负责。
static bool tcp_validate_incoming(struct sock *sk, struct sk_buff *skb, const struct tcphdr *th, int syn_inerr)
{
struct tcp_sock *tp = tcp_sk(sk);
/* RFC1323: H1. Apply PAWS check first. */
if (tcp_fast_parse_options(sock_net(sk), skb, th, tp) &&
tp->rx_opt.saw_tstamp &&
tcp_paws_discard(sk, skb)) {
if (!th->rst) {
....
goto discard;
}
/* Reset is accepted even if it did not pass PAWS. */
}
当 tcp_paws_discard 返回 true,就代表报文是一个历史报文,于是就要丢弃这个报文。但是在丢掉这个报文的时候,会先判断是不是 RST 报文,如果不是 RST 报文,才会将报文丢掉。也就是说,即使 RST 报文是一个历史报文,并不会被丢弃。
假设有这样的场景,如下图:
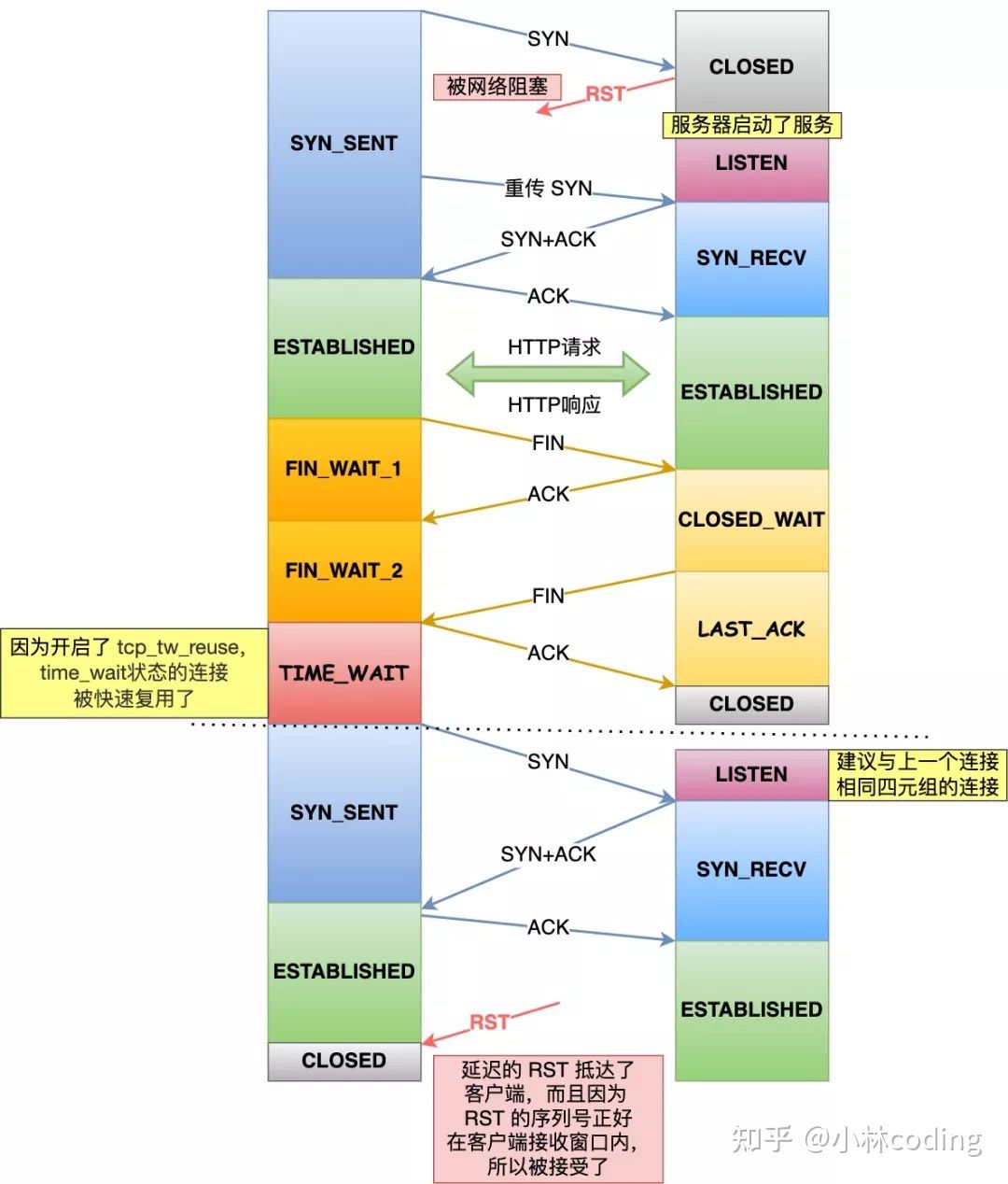
- 客户端向一个还没有被服务端监听的端口发起了 HTTP 请求,接着服务端就会回 RST 报文给对方,很可惜的是 RST 报文被网络阻塞了。
- 由于客户端迟迟没有收到 TCP 第二次握手,于是重发了 SYN 包,与此同时服务端已经开启了服务,监听了对应的端口。于是接下来,客户端和服务端就进行了 TCP 三次握手、数据传输(HTTP应答-响应)、四次挥手。
- 因为客户端开启了 tcp_tw_reuse,于是快速复用 TIME_WAIT 状态的端口,又与服务端建立了一个与刚才相同的四元组的连接。
- 接着,前面被网络延迟 RST 报文这时抵达了客户端,而且 RST 报文的序列号在客户端的接收窗口内,由于防回绕序列号算法不会防止过期的 RST,所以 RST 报文会被客户端接受了,于是客户端的连接就断开了。
上面这个场景就是开启 tcp_tw_reuse 风险,因为快速复用 TIME_WAIT 状态的端口,导致新连接可能被回绕序列号的 RST 报文断开了,而如果不跳过 TIME_WAIT 状态,而是停留 2MSL 时长,那么这个 RST 报文就不会出现下一个新的连接。
可能大家会有这样的疑问,为什么 PAWS 检查要放过过期的 RST 报文。我翻了 RFC 1323 ,里面有一句提到:
It is recommended that RST segments NOT carry timestamps, and that RST segments be acceptable regardless of their timestamp. Old duplicate RST segments should be exceedingly unlikely, and their cleanup function should take precedence over timestamps.
大概的意思:建议 RST 段不携带时间戳,并且无论其时间戳如何,RST 段都是可接受的。老的重复的 RST 段应该是极不可能的,并且它们的清除功能应优先于时间戳。
RFC 1323 提到说收历史的 RST 报文是极不可能,之所以有这样的想法是因为 TIME_WAIT 状态持续的 2MSL 时间,足以让连接中的报文在网络中自然消失,所以认为按正常操作来说是不会发生的,因此认为清除连接优先于时间戳。
而我前面提到的案例,是因为开启了 tcp_tw_reuse 状态,跳过了 TIME_WAIT 状态,才发生的事情。
有同学会说,都经过一个 HTTP 请求了,延迟的 RST 报文竟然还会存活?
一个 HTTP 请求其实很快的,比如我下面这个抓包,只需要 0.2 秒就完成了,远小于 MSL,所以延迟的 RST 报文存活是有可能的。
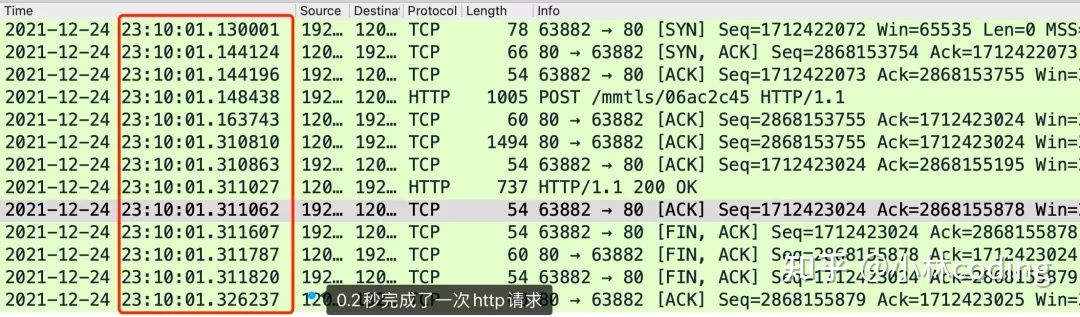
开启 tcp_tw_reuse 来快速复用 TIME_WAIT 状态的连接,如果第四次挥手的 ACK 报文丢失了,有可能会导致被动关闭连接的一方不能被正常的关闭,如下图:
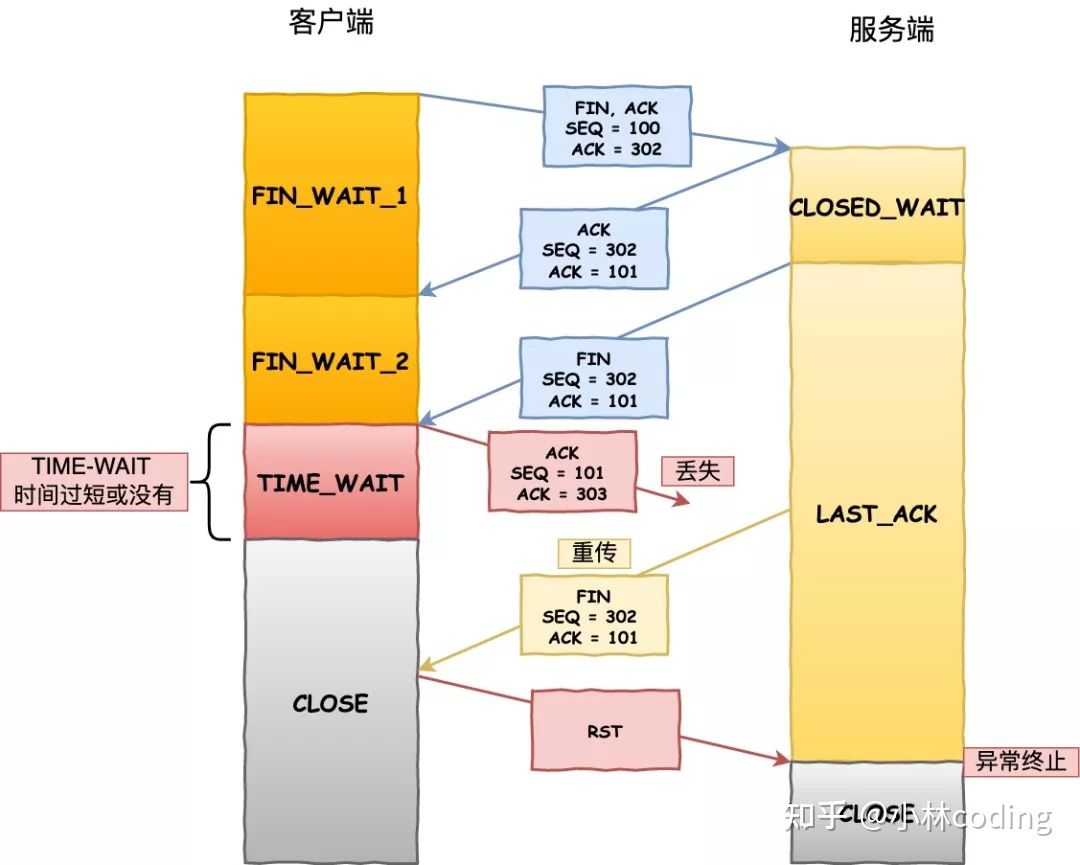
tcp_tw_reuse 的作用是让客户端快速复用处于 TIME_WAIT 状态的端口,相当于跳过了 TIME_WAIT 状态,这可能会出现这样的两个问题:
- 历史 RST 报文可能会终止后面相同四元组的连接,因为 PAWS 检查到即使 RST 是过期的,也不会丢弃。
- 如果第四次挥手的 ACK 报文丢失了,有可能被动关闭连接的一方不能被正常的关闭;
虽然 TIME_WAIT 状态持续的时间是有一点长,显得很不友好,但是它被设计来就是用来避免发生乱七八糟的事情。
《UNIX网络编程》一书中却说道:TIME_WAIT 是我们的朋友,它是有助于我们的,不要试图避免这个状态,而是应该弄清楚它。