Nova
OpenStack的核心项目主要是计算服务、网络服务和存储服务,并通过Dashboard 将这三大服务呈现给用户,实现云用户与数据中心资源池的交互。
在云计算领域,亚马逊的AWS 通常被认为是云计算的鼻祖和标杆,而Openstack 的目标便是帮助用户基于开源项目搭建具备类似AWS 功能的云计算基础架构设施服务(IaaS)。
Nova 由负责不同功能的服务进程所构成,其对外提供的服务接口为 REST API,而各个内部组件之间通过RPC消息传递机制进行通信。Nova 中提供API 请求处理功能的模块是Nova-API,由API服务进程来处理数据库读写请求、向其他服务组件发送 RPC 消息的请求和生成RPC调用应答的请求等。
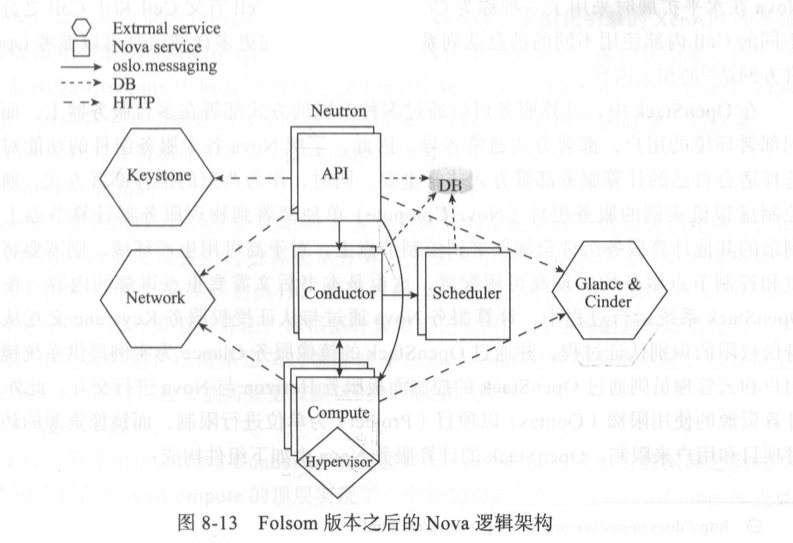
- Nova-API
Nova API服务组件。Nova-API服务负责接收和响应终端用户对OpenStack计算资源发起的API调用请求,如WSGI APP路由请求和授权相关请求。Nova-API接收到请求后,通常将请求转发给Nova的其他组件进行处理,如Nova-scheduler。 Nova-API除了支持OpenStack Compute API,还支持AWS EC2 API和授权用户执行管理任务的特定API。Nova-API遵循特定的策略并初始化大部分的编排操作,如用户发起一个创建实例的请求,则创建实例的初始编排工作由Nova-API首先发起。
- Nova-API-Metadata
Nova API服务组件。Nova-API-Metadata服务主要用于接收来自实例的元数据请求,此服务通常只有在使用Nova-network 部署OpenStack网络并使用Multi一host模式时启用。Multi一host网络模式类似于Juno版本 Neutron项目中发布的虚拟分布式路由(DestributeVirtual Route, DVR)功能,即网络的东西和南北向流量不经过网络节点而直接由计算节点来负责网络功能。
- Nova-Compute
Nova核心服务组件。Nova-Compute是一个通过调用Hypervisor API创建和终止实例的Worker进程,通常将 Nova-Compute单独部署在支持虚拟化的物理服务器上,而部署 Nova-Compute服务的节点通常称为计算节点。
Nova-Compute常见的Hypervisor API有支持KVM/QEMU虚拟化引擎的Libvirt API、支持 XenServer/XCP虚拟化引擎的 XenAPI 和支持VMware虚拟化引擎的VMware API。OpenStack 默认使用的是KVM虚拟化引擎,因此在OpenStack Nova一Compute 中最常使用的还是Libvirt API。Nova-Compute的工作流程相对比较复杂,但是其主要功能是接收来自队列的请求,并执行一系列系统命令,如创建一个KVM虚拟机实例并在数据库中更新对应实例的状态等。
- Nova-Scheduler
Nova 核心服务组件。Nova-Scheduler主要负责从队列中截取虚拟机实例创建请求,依据默认或者用户自定义设置的过滤算法从计算节点集群中选取某个节点,并将虚拟机实例创建请求转发到该计算节点上执行,即最终的虚拟机将运行在该计算节点上。Nova-Scheduler 采用的过滤计算节点算法,即根据计算节点的CPU、内存和磁盘等参数进行筛选过滤。用户也可以根据自己需求定义过滤算法并在 nova.conf配置文件中指定,如在配置Host Aggregate功能时,通常就需要更改默认的Scheduler规则。
- Nova-Conductor
Nova核心服务组件。Nova-Conductor 主要起到Nova-Compute服务与数据库之间的交互承接作用,其在Nova-Compute的顶层实现了一个新的对象层以防止 Nova-Compute直接访问数据库带来的安全风险。在实际运行中,Nova一Compute并不直接读写访问数据库,而是通过 Nova一Conductor实现数据库访问。Nova一Conductor组件可以水平扩展到多个节点上同时运行,但是Nova一Conductor不能部署到运行Nova一Compute的计算节点上,否则将不能隔离Nova一Compute对数据库的直接访问,从而不能真正起到降低数据安全风险的作用。
Region 是地理位置上隔离的数据中心区域,不同 Region 之间是彼此独立的,即 某个Region 范围内的人为或自然灾害并不会影响到其他 Region 的正常运行 。
在具体的实现过程中,不同的 Region 通常共用相同的认证服务和控制面板服务 。 在OpenStack 中,如果是基于 OpenStack 部署公有云,则多个 Region 之间通常共享同一个Keystone 和 Dashboard 服务,而如果是基于 OpenStack 来部署私有云,并希望通过不同的 Region 来实现业务系统的高可用或者灾备,则通常还需要部署单一的共享存储池 。 不同的 Region 之间可以通过共享存储池进行数据复制同步来实现高可用(根据需求和实现技 术, 也可以部署隔离区域专有的存储池) 。
图 8-18 为 OpenStack 官方推荐的私有云多区域部署架 构, Region1和 Region2 共享 Horizon, Keystone 和 Swift 服务,其他 OpenStack 服务在 Region 中独立部署 。 由于不同 Region 内部服务独立部署,因而不同Region 内部相同的OpenStack 服务会有不同的 Endpints API ,对不同 Region 内部服务的访问就需要指定不同的 API,在实际应用中,用户通常是通过负载均衡器实现不同 Region 中服务 API 的访问 。
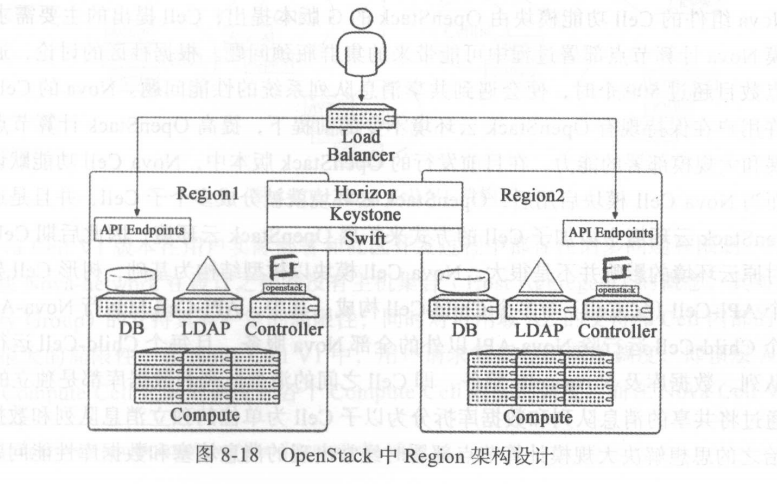
从理论而言, Region 其实是个很灵活的设计概念 。 它的地理位置级别的计算资源隔离并不意味着只有相隔至少几十公里的数据中心之间才能部署,其理论范围可以很小,如位于相同数据中心同一个机柜或相邻机柜的服务器也可以被划分为不同的 Region ,只不过这样的划分并无实际意义 。
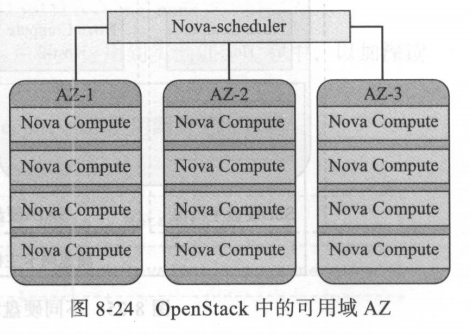
可用域( Availability Zone, AZ )是对计算资源的另一种划分方式,在 AWS 的区域划分设计中, AZ 是对 Region 的再次划分,例如可以把同处相同机架或者相邻机架上的服务器划分到同一个 AZ 中,或者可以把同一个 Region 中彼此独立供电和制冷的机房划分为独立的 AZ 。 按照 AWS 的解释,划分 AZ 的主要目的是为了提高容灾性和提供廉价的故障隔离服务 。 用户在不同的 Region 之间做出选择时,主要考虑的是距离自己最近的 Region 或者 Region 所处国家 /地区的政策法规是否满足自己服务器和业务系统运行的需求 。 通常,在没有特殊考虑的情况下,距离用户最近的 Region 应该是首选,例如 AWS 的美国用户,自然会选择离美国近的较近或国内的 Region,而用户在选定 Region 后, 还可以选择将自己的实例部署在不同的 AZ 中,选择不同 AZ 部署实例的主要原因在于防止某个 AZ 故障时位于其上的所有实例同时者机。
从功能实现而言, OpenStack 中的 AZ 功能主要是基于 Nova 的调度服务 Nova-scheduler 来实 现的 。 AZ 对用户是可见的,因此用户在创建实例时,可以显式告知 Nova 应该将实例创建在哪个 AZ 中,当 Nova-scheduler 接收到 AZ 参数后,便会将创建实例的请求调度到指定的 AZ 主机聚合中 ,并将实例创建在此AZ 中的某台主机上
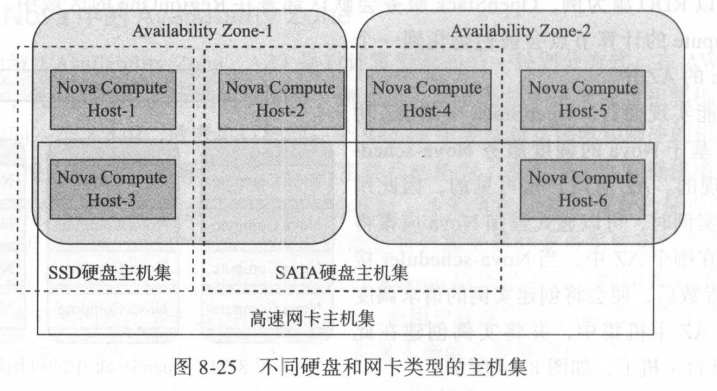
AZ 是一个面向终端用户的概念和计算资源划分方式, 主要用来进行故障隔离,是对用户可见的 。 而 Host Aggregate 是 OpenStack 云平台管理员用来进行主机划分的另 一种方式,即管理员可以根据硬件资源的某一属性,将具有相同硬件属性的服务器归类划分的方式。 Host Aggregate 可以用来进一步细分 AZ ,并且只对 Nova 调度器可见 。 简单来说,如果用户想要将实例创建到具体某台指定的主机上,通过 AZ 便可实现,但是不能通过 Host Aggregate 实现 。 Host Aggregate 对用户不可见,因此无法通过 Host Aggregate 指定创建实例的具体主机,需要通过 Nova 的模板( Flavors )配合 Nova-scheduler 调度器才能实现。对Host Aggregate 的理解可以参考很多公有云供应商的云计算资源供给实现,例如供应商的数据中心机房部署了不同类型的服务器,某些物理服务器因为特定的配置而具有强大的计算能力,而另外一些服务器具有强大的 I/O 能力,其他的一些服务器配置了高速网卡具有强大的网络吞吐能力,这样供应商为了提供针对特定领域使用的用户,便会将具有强大计算能力的主机放置到一个主机聚合合中(取名为 A ),具有强大 1/0 能力同时计算能力也不错的主机放置到另一个主机聚合合中(取名 B ) 。供应商便可根据用户选择进行差异计费,通常计算能力和 I/O 能力都不错的主机聚合合 B 收费要高于仅提供计算能力的主机聚合合 A。当然供应商还可以根据很多硬件参数来设置 Host Aggregate,例如使用固态硬盘的机器,内存超过 32G 的机器等,这些服务器的硬件配置都可以成为供应商设置 Host Aggregate 的标准 。Host Aggregate 与 AZ 之间的关系如图 8-25 所示,在图 中,根据服务器硬盘所属类型,将 AZ 中的服务器又细分为 SSD 硬盘主机聚合、 SATA 硬盘主机聚合和高速网卡主机聚合。
一个主机可以同时属于多个主机聚合。
在实际使用中, AZ 常用于在创建实例时指定 Launch 实例的目标主机,为了简单起见,OpenStack 官方推荐直接使用默认的 AZ 。 而 Host Aggregate 的使用主要是对服务器进行硬件归类划分,通常需要用户自己创建 Host Aggregate 。
当 Nova 客户端发起创建实例请求时, Nova-API 会将请求转发到 Nova-scheduler ,由 Nova-scheduler 在运行 Nova-compute 的计算节点中选取用于创建符合请求虚拟机资源条件的宿主机。 Nova-scheduler 对宿主机的选取分为两个步骤:
第一步从计算节点集群中选取符合请求虚拟机资源条件的全部节点,这一过程称为过滤(Filter);
第二步从符合创建请求虚拟机的计算节点中选取唯一最佳的计算节点,作为本次请求虚拟机的宿主机,这一过程称为加权( Weigh ) 。
Nova-scheduler 的过滤加权过程如图 8-37所示,在经过第一步的过滤之后, host2 和 host4 被排除,即只有 hostl 、 host3 、 host5 和host6 符合创建请求虚拟机的条件,这 四个主机经过第二步的加权后,得到一个主机权重排序列表 ,此处的 host5 主机便是创建请求虚拟机的最佳宿主机,即本次虚拟机创建请求会被指派到 host5 主机并最终在 host5 上创建虚拟机。
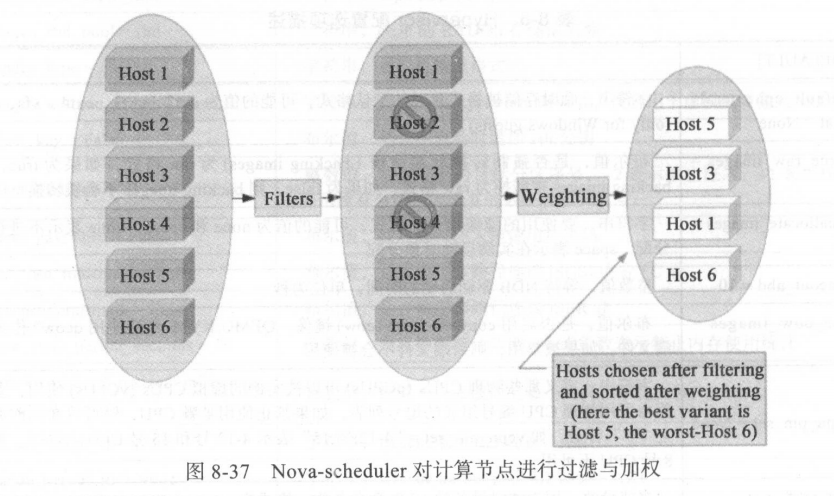
在 Nova-scheduler 的过滤阶段, Nova 的 Filter Scheduler 根据配置文件 nova.conf 中设置的策略集合( Filters Set)对 OpenStack 集群中全部计算节点进行过滤迭代 。 在 nova. conf中,通过三个参数来配置 Nova-scheduler ,即 scheduler driver 、 scheduler available filters和 scheduler_default_ filters ,这三个参数的默认值如下:

在 Nova 的配置文件/etc/nova/nova.conf 中,配置参数 scheduler driver 用于设置 Novascheduler 使用的 Scheduler, FilterScheduler(nova.scheduler.filter_scheduler.FilterScheduler)是 Nova-scheduler 默认使用的 Scheduler。 此外, Nova-scheduler 允许使用第三方的 Scheduler ,用户只需设置 scheduler driver 即可 。 在使用默认的 FilterScheduler 时, Nova-schedu ler首先通过过滤器筛选出满足条件的计算节点,再通过加权计算选择最优的计算节点以在其上创建实例 。
在 nova.conf 中,配置参数 scheduler available filters 用于指定 Scheduler 可以使用的过滤器,默认情况下 Nova 自带的全部过滤器均可被使用( nova.scheduler. filters.all filters ) 。可用过滤器参数可以重复指定,如用户自己实现了一个过滤器 myfilter.WarriorFilter ,然后用户既想使用 Nova 自带的过滤器又想使用自建的过滤器,则可以将可用过滤器参数scheduler available filters 在 nova.conf 中进行如下重复配置:

nova.conf 中的另外一个配置参数 scheduler default filters 用于指定 Nova-scheduler 服务使用 的过滤器列表。
在 Nova-scheduler 进行 主机过滤 时,主机会被此参数指定的列 表过滤器顺序过滤一遍 。 Nova-scheduler 默认使用的过滤器依次为 RetryFilter 、 AvailabilityZoneFilter 、 RamFilter 、 ComputeFilter 、 ComputeCapabilitiesFilter 、 ImagePropertiesFilter 、ServerGroupAntiAffinityFilter 和ServerGroupAffinityFil ter ,在主机进入每个过滤器时,如果主机条件满足请求中的实例需求,则返回 True ,否则返回 False 。 当返回 False 后,该主机的过滤流也就结束,不再进入后续过滤器继续过滤 。
当然, Nova-scheduler 内建自带的过滤器不局限于上述 8 个,下面将分别对 Nova-scheduler 的主要内建过滤器进行介绍 。
以 Aggregate 为前缀的过滤器通常只在创建了 Host Aggregate 的情况下才会使用到 。
AggregateCoreFilter 表示通过主机CPU核数来过滤每个Aggregate中的主机。主机可用CPU 核心数通过每个主机聚合配置文件中的 cpu_allocation_ratio 值(默认为 16 )来计算 。 如果主机 CPU 核心数满足请求创建实例的vCPUS 需求,则返回 True 。 如果当前主机属于多个Host Aggregate ,并且有多个 cpu_allocation_ratio 值,则使用 cpu_allocation_ratio 的最小值 。
cpu_allocation_ratio 参数主要用于设置主机 CPU 的 overcommit ,如 cpu_allocation_ratio=l6 ,而主机 vCPUs 为 8 ,则调度时 Scheduler 认为主机可用 vCPU 为 128 。
AggregateDiskFilter 表示通过主机磁盘使用率来过滤每个Aggregate中的主机 。 主机磁盘使用率会根据每个主机聚合配置文件中的disk_allocation_ratio(默认值为 1 ,即按实际磁盘容量来调度)参数来计算,如果 OpenStack 集群中没有创建主机聚合,则 disk_allocation_ratio便会成为全局性的参数。如果主机聚合中主机上的可用磁盘容量(单位为 GB )满足请求虚拟机中的磁盘需求(镜像系统盘大小和临时存储大小 ), 则返回 True 。
AggregatelmagePropertieslsolation 表示根据实例创建请求中的镜像属性来过滤主机聚合中的主机,通常用于将基于特定镜像的实例创建到与镜像匹配的特定主机上。
镜像属性与主机匹配与否根据如下规则来判断:如果当前主机属于某个主机聚合,并且此主机聚合定义了相应的元数据来匹配某个镜像的属性,则认为该主机与镜像属性匹配,并且该主机将成为启动这个匹配镜像的候选主机;如果当前主机不属于任何主机聚合,则该主机可以启动任何镜像。
例如对于主机聚合HAI ,有如下的主机成员和元数据信息:


AggregatelnstanceExtraSpecsFilter 与 AggregatelmagePropertieslsolation 过滤器的功能类似,只是AggregatelnstanceExtraSpecsFi lter 匹配的是 Nova 中 Flavor 与主机集的元数据,而不是镜像属性与主机集的元数据 。 在使用 AggregatelnstanceExtraSpecsFilter 过滤器时 ,通常需要为 Flavor 的属性aggregate_instance_extra_specs 设置一个属性值 。 过滤器将会根据主机集的元数据与实例创建请求中 Flavor 的 aggregate_instance_extra_specs 属性值来判断主机是否符合要求 。
AggregateloOpsFilter 表示根据主机的IO负载来过滤每个主机集中的主机。主机 IO 负载根据参数 max_io_ops_per_host 值(默认为 8 )来决定, 此过滤器会将 IO 负载过高的主机过滤掉。
AggregateNumlnstancesFilter 表示根据主机已有实例数目来过滤每个主机集中的主机,过滤标准为主机集中允许的最大主机实例数目参数 max_instances_per_host (默认 50 )值,当前运行实例数目超过此参数值的主机将会被过滤掉。
AggregateMultiTenancylsolation 用于将特定某个租户或多个租户的实例创建到特定的主机集或可用域中 。 如果主机属于某个具有元数据且 key为自filter_tenant_id的主机集, 则对应filter_tenant_id值的某个租户或多个租户发起的创建实例请求将会在该主机上创建实例 。 而如果主机不属于元数据 key 为filter_tenant_id的主机集, 则所有组合都可以在该主机上创建实例 。 AggregateMultiTenancyIsolation 过滤器并不会将具有元数据 Key 为 filter_tenant_id 的主机集与其他租户隔离,任何租户仍然可以在指定的主机集上创建实例 。
在经过 SchedulerFilter 中一系列的过滤器过滤之后, Nova-scheduler 会选出符合请求实例资源的主机,但是如果有多台主机同时符合要求,则经过 SchedulerFilter 之后,仍然会得到一个主机列表 。 为了得到最终的实例创建主机, Nova-scheduler 会给过滤后的主机列表中的计算节点进行“评分”,分数最高的主机将成为最终的实例创建主机,这个 “评分”的过程即是所谓的权重计算( Weighting ) 。 权重计算就是给有效主机列表中的主机进行权重赋值并选出最优权重值主机的过程。每个计算节点都可以通过不同的维度参数来进行评估,如内存 、 磁盘、 CPU 和 IO 负载,而这些不同维度的参数被称为一个权重( Weigher ) 。 由于各个权重的单位不同,如内存单位为 MB ,磁盘单位为 GB, CPU 单位为核数等,因此不能对这些权重进行简单的线性相加来获取计算节点最终的权重值。 同时,不同的权重对用户而言可能重要程度并不一样(如 A 用户认为内存比 CPU 重要 ,而 B 用户认为 CPU 比内存更重要)。为了解决这一问题,需要预先为每个权重定义关联的权重因子( multiplier),如果认为此权重要优于其他权重,则可以为其设置较大的权重因子。
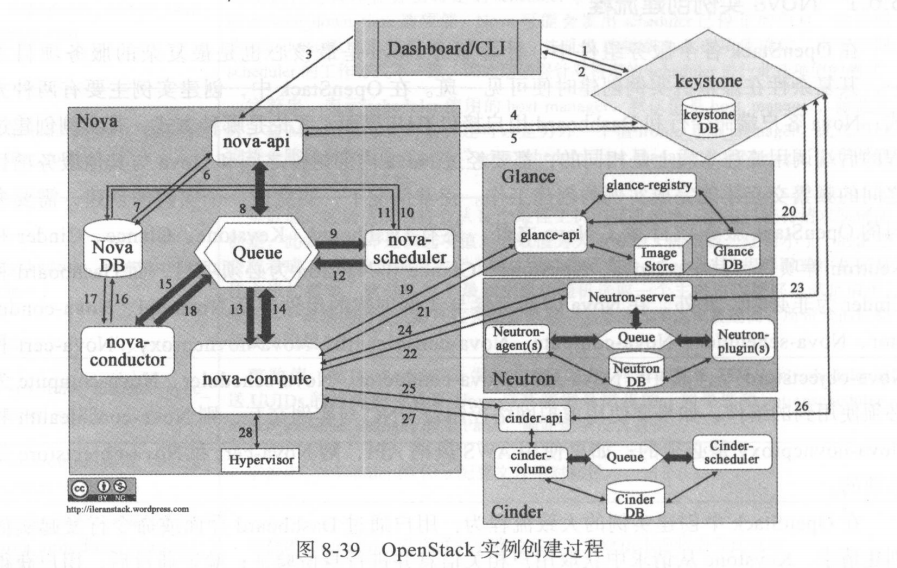
在 OpenStack 中创建实例的大致流程为:
用户通过 Dashboard 界面或命令行发起实例创建请求, Keystone 从请求中获取用户相关信息并进行身份验证;验证通过后,用户获得认证 Token , 实例创建请求进入 Nova-api ;在向 Keystone 验证用户 Token 有效后,Novaapi 将请求转入 Nova-scheduler ; Nova-scheduler 进行实例创建目的主机的调度选择,目标主机选取完成后,请求转入 Nova-compute; Nova-compute 与 Nova-conductor 交互以获取创建实例 的信息 , 在成功获取实例信息后, Nova-compute 分别与 Glance 、 Neutron 和 Cinder交互以获取镜像资源 、 网络资源和云存储资源; 一切资源准备就绪后, Nova-compute 便通过 Libvi rt API 与具体的 Hypervisor 交互并创建虚拟机 。
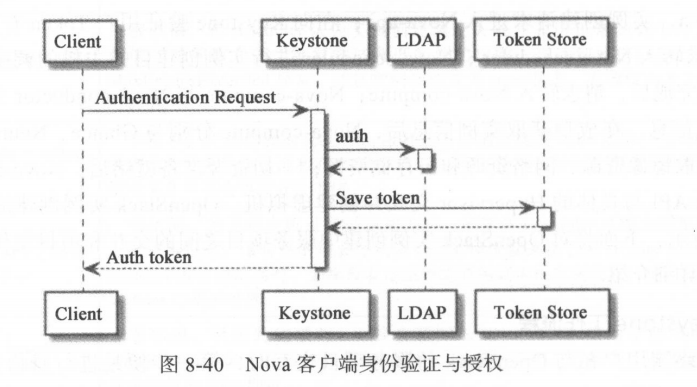
任何终端用户 在与 OpenStack 的服务项目交互时,第一步便是进行身份认证与授权,而 Keystone 负 责 OpenStack 全部项目的认证与授权任务 。 当 Nova 客户端发起实例创建请求时, Nova 客户端便与 Keystone 进行交五以获取授权 Token ,如果 Nova 客户端通过Keystone 的身份验证,则 Keystone 为其生成授权 Token ,并将此 Token 存储到后端数据库中 。 Keystone 的后端数据库可以是 SQL 数据库,也可以是如 Memcache 这样的缓存系统。为了快速响应后续 OpenStack 服务组件发起的 Token 核实过程,建议尽量使用基于内存的缓存系统作为 Keystone 的后端存储数据库 。 Keystone 的身份验证过程可以在本地进行,也可以通过 LDAP 服务器进行身份验证。
图 8-40 为 Nova 客户端与 Keystone 交互进行身份验证和 Token 颁发过程(这里 Keystone 使用 LDAP 进行身份验证) 。
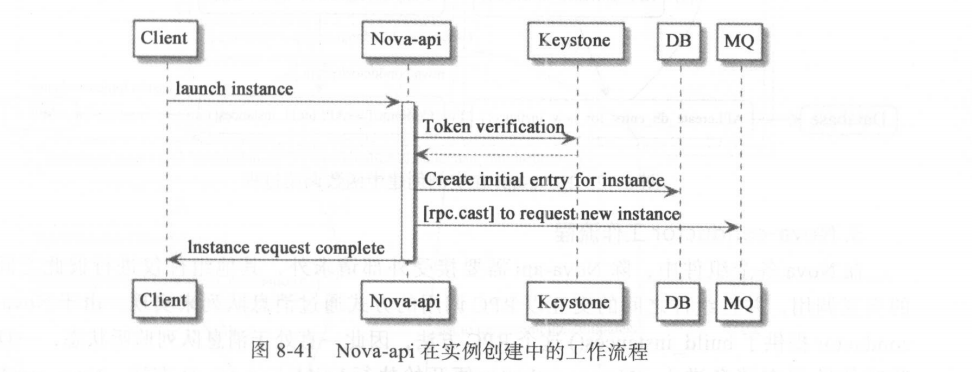
Nova 客户端在通过 Keystone 的验证并获取 Token 后,便会携带Token向 Nova-api 发出实例创建的请求, Nova-api 接收到请求后向 Keystone 验证 Token 的有效性,验证成功后, Nova-api 开始判断实例创建请求所携带的参数是否有效合法,如
检查虚拟机名 字是否符合命名规范,使用的虚拟机模板 flavor_id 在数据库中是否存在,使用的镜像 image_uuid 是否是有效的 uuid 格式等 。
检查 instance、 vCPU、RAM 的数量是否超出了配置文件中的限制 ,通常每个 Project 拥有的资源都是有限的,如创建虚拟机的个数、 vCPU 个数、内存大小和 volume 个数等,这些限制是管理员通过与 Project 相关的 Quota 来设置的,如 quota_instances 、 quota_cores 、 quota ram 、 quota_volumes 等 。 如果管理员未做设置更改,则默认情况下所有 Project 拥有相等的资源数量 。
此外, Nova-api 还会检查相关 metadata 的长度是否超过限制,inject_files 的数目是否超过限制,一般情况下这些参数都为空,因此都能通过检查。
实例请求中的网络 、 镜像和 flavor 也是 Nova-api 主要的检查对象,其主要检查请求中 的 network 是否存在且可用以及 image 和 flavor 是否存在且可用,同时还会检测请求中 flavor 的磁盘是否满足 image 需求等 。
当所有资源检查都通过后, Nova-api 便在 nova 数据库中初始化虚拟机相关的记录( intial entry ),主要包括 instance 、 block_device_mapping和 quota 等记录,并将 instance 记录中的 vm_states 字段设为 building, task_state 字段设为scheduling 。
之后, Nova-api 调用 Nova-conductor 并将请求传递到消息队列( MQ )中 。 由于 Nova-api 将请求以 RPC cast 的方式发送给 Nova-conductor ,而 cast()方法发送的请求并不会返回消息,因此 Nova 客户端此时只会接收到请求已被接受的返回,但是具体的虚拟创建过程还在后台继续执行,而 Nova 客户端可以查到的虚拟机 vmstate 为 building, task_state 为 scheduling 。只此, Nova-api 的工作执行完成,客户端可以进行其他操作,实例创建过程在后台继续进行 。
Nova-api 在实例创建过程中的工作流程如图 8-41 所示 。
在 Nova 各个组件中,除 Nova-api 需要接受外部请求外,其他组件仅进行彼此之间的交互调用,并且组件之间的交互以 RPC 调用的方式通过消息队列来实现 。
由于 Novaconductor 提供了 build_instances()这个 RPC 方法,因此一直处于消息队列监听状态, 一旦监听的队列有消息进入, Nova-conductor 便开始执行 build_instances()方法 。 Nova-conductor 还向 Nova-schduler 发出 RPCcall 调用, 并要求其返回计算节点调度结果,在收到 Nova-scheduler 的调度结果后, Nova-conductor 的 build_instances()方法将请求传递到Nova-compute 的消息队列中。如 图 8-43 所示 。
可见nova-conductor起到一个中间协调其他组件的作用:
- 接收nova-api发起的实例创建请求
- 向Nova-schduler发起请求获取宿主机节点
- 向Nova-compute发起请求创建实例
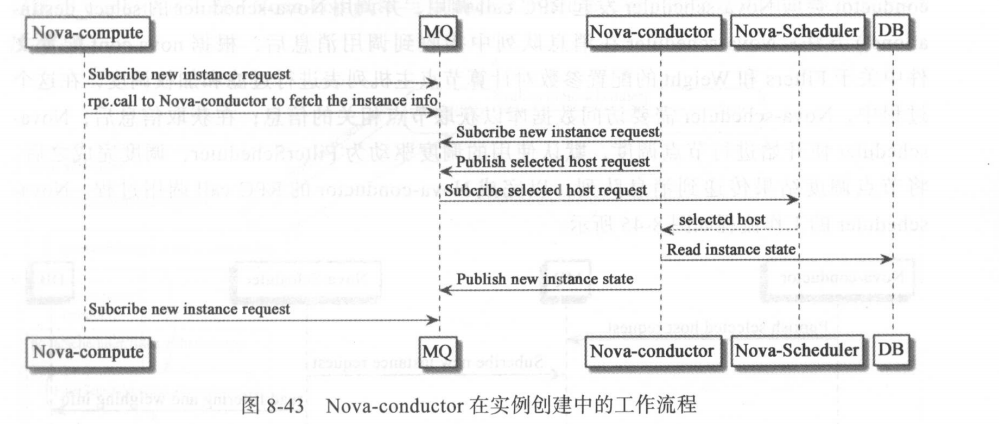
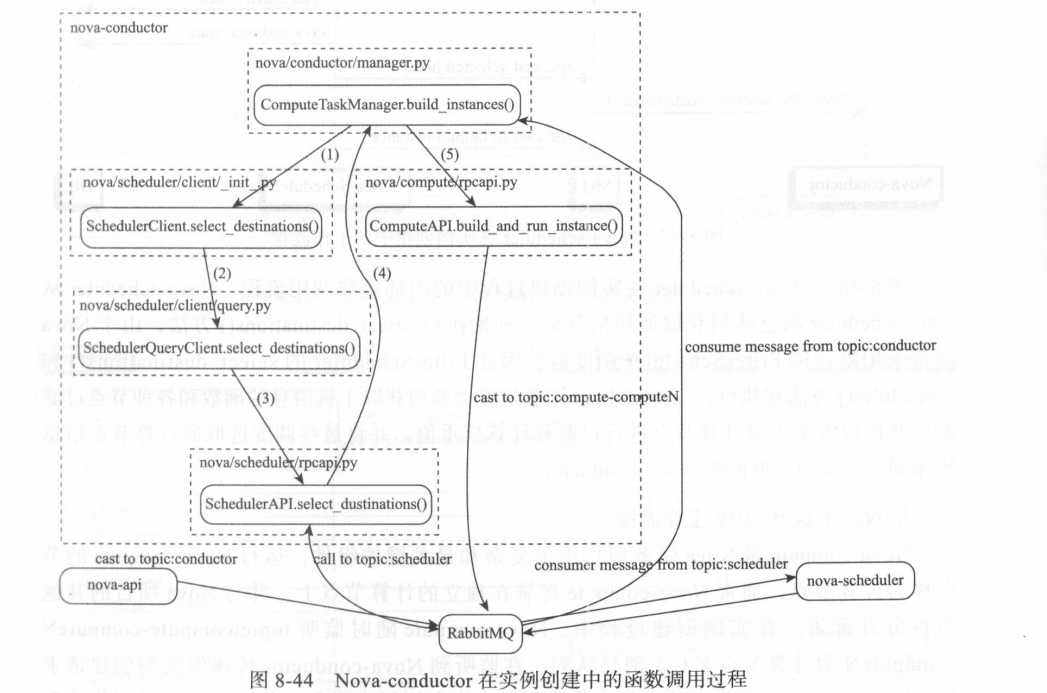
图 8-44 是 Nova-conductor 组件的内部函数执行流程, Nova-conductor 从 topic:conductor 消息队列中提取 Nova-api 传递进来的消息,并执行 build_instances()方法,此方法经过一系列函数调用,向 topic: scheduler 队列发出 RPC call 调用消息, Nova-scheduler 在获取topic : scheduler 对象消息后, 经过 内部 Filter 和 Weigh 过程,调度出 一个或多个最优计算节点,并将经过返回给消息队列, Nova-conductor 通过消息队列获取 Nova-scheduler 返回的计算节点列表值,并通过 build_and_run_instance()方法将实例创建请求发送到 Nova-compute的 topic:compute-computeN 队列中( computeN 表示某个计算节点名称) 。
Nova-scheduler 的功能就是负责监听消息队列,并在获取消息队列之后进行计算节点的调度选取,同时将调度结果传递给消息队列 。
为了获取创建实例的目标主机, Nova-conductor 会向 Nova-scheduler 发起 RPC call 调用,并调用 Nova-scheduler 的 select_destinations()方法; Nova-scheduler 在消息队列中接收到调用消息后,根据 nova.conf 配置 文件中关于 Filters 和 Weight 的配置参数对计算节点主机列表进行过滤和加权调度,在这个过程中, Nova-scheduler 需要访问数据库以获取节点相关的信息;在获取信息后, Nova-scheduler 便开始进行节点调度,默认使用的调度驱动为 FilterScheduler ,调度完成之后,将节点调度结果传递到消息队列,以完成 Nova-conductor 的 RPC call 调用过程 。 Novascheduler 的工作流程如图 8-45 所示 。
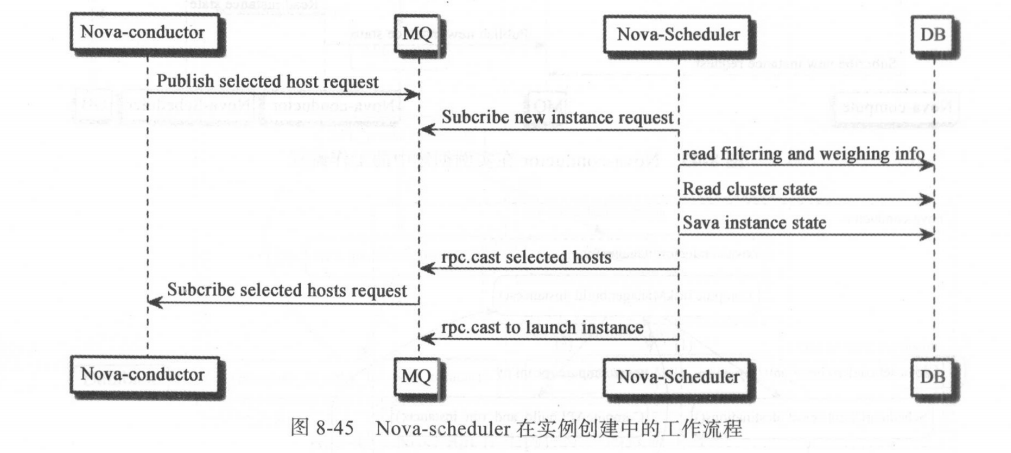
Nova-scheduler 在实例创建过程中的内部函数调用流程:Nova-scheduler 从topic:scheduler 消息队列获取调用信息后,开始执行 select_destinations()方法,由于 Nova通常采用默认的 FilterScheduler 调度器,因此 FilterScheduler 的 select_destinations()和_scheduler()方法被执行,_scheduler()函数最终会调用获取主机信息的函数和各种节点过滤器以及加权方法以对计算节点进行过滤和计算权重值,并将最终调度选取的计算节点信息传递到消息队列,返回给 Nova-conductor。
Nova-compute 是 Nova 服务项目中最复杂和最关键的组件,运行 Nova-compute 的 节点称为计算节点,通常 Nova-compute 部署在独立的计算节点上,并与 Nova 项目的其他组件分开部署 。
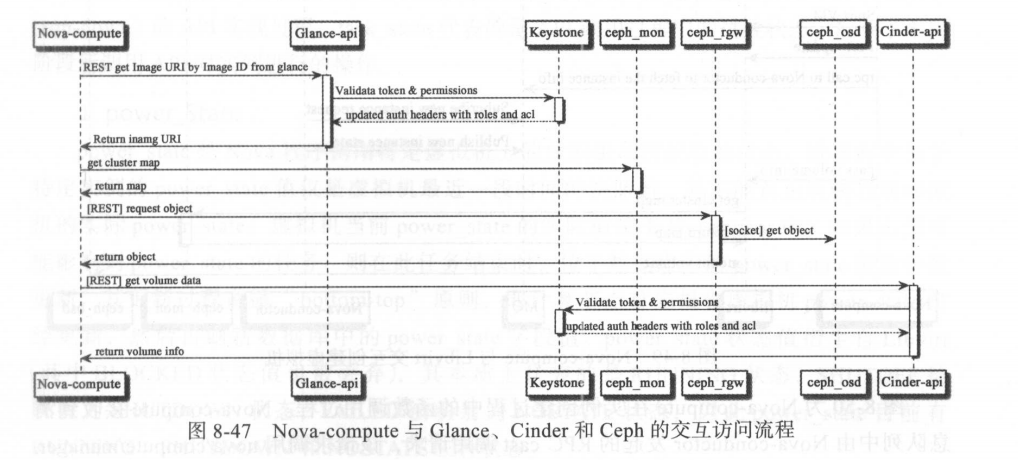
在实例创建过程中, Nova-compute 随时监听 topic:compute-computeN( computeN 为计算节点名称)消息队列,在监听到 Nova-conductor 传递的实例创建请求后, Nova-compute 开始启动内部工作流程以响应实例创建请求 。 在 Nova-api 的工作流程中,请求中创建实例所需的镜像、网络和存储等资源已经做过有效性和可用性的检查,因此 Nova-compute 将直接与 Glance 交互以获取镜像资源,与 Cinder 交互获取块存储资源 。如果配置了Ceph 块存储或对象存储服务, Nova-compute 还会与 Ceph RADOS 进行交互以访问 Ceph 存储集群 。 Nova-compute 与 Glance 、 Cidner 和 Ceph 的交互访问流程如图 8 -47所示 。
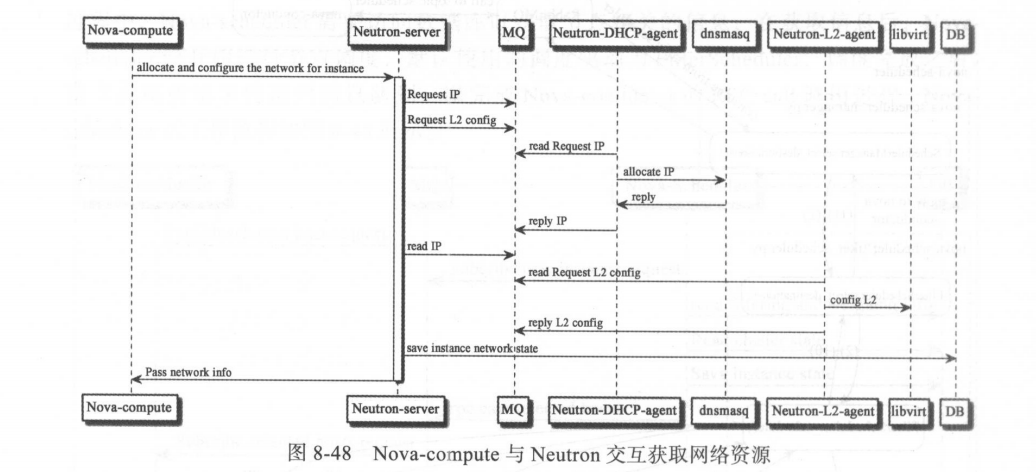
在获取镜像和存储资源后, Nova-compute 还需与 OpenStack 的网络服务项目 Neutron进行交互访问以获取网络资源 。 由于网络资源的有效性和可用性已经在 Nova-api 工作流程中完成,这里主要是获取虚拟机的 Fixed IP 等网络资源 。 Nova-compute 与 Neutron 的交互过程如图 8-48 所示 。
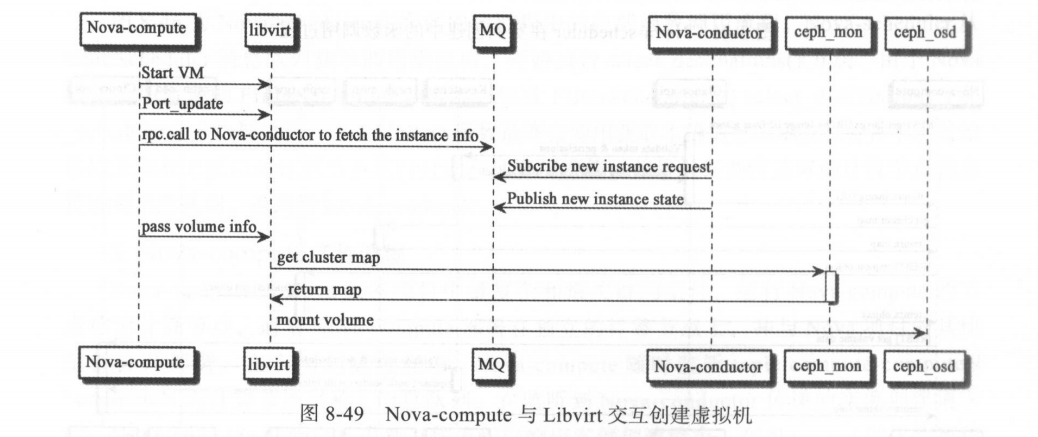
在准备好常见实例所需的一切资源后, Nova-compute 将通过 Libvirt 与对应的 Hypervisor API 进行交互,并通过 Libvirt API 接口进行虚拟机的创 建工作 。 Nova-compute 与Libvirt 交互创建实例的过程如图 8-49 所示 。
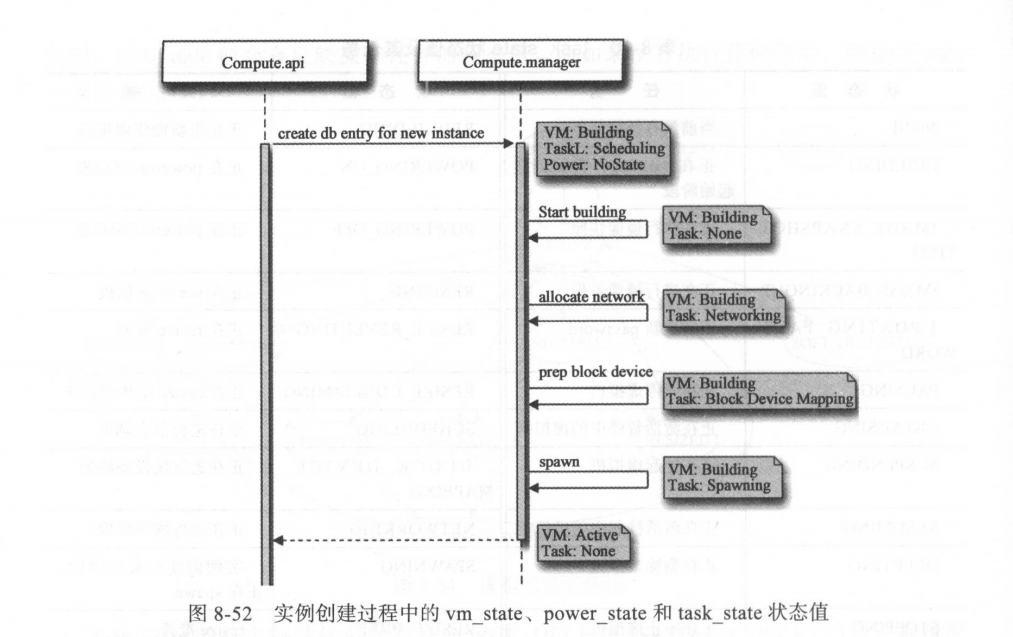
Nova-compute 接收到消息队列中由 Nova-conductor 发起的 RPC cast 调用请求,该请求调用 nova/compute/manager.PY 中的 C omputeManager.build_and_run_instance()方法,该方法继而调用 ComputeManager类中 的_build_and_run_instance()方法以尝试创建实例 ; 这里创建实例不一定成功,如果创建失败并且是因为 Scheduler 调度结果的原因,则会发起 Re-scheduler 操作以重新调度计算节点,并再次尝试创建实例 。8
进入_build_and_run_instance()方法开始创建实例后, Nova-compute 便开始准备网络和存储等资源(这两个资源分别由 build_networks for_instance()和 _prep_block_device()方法来完成) 。
- 其中,在进行网络资源准备时,实例的 vm_state 被设为 building ,而 task_state被设置为 networking ;
- 在准备块存储资源时,实例的 vm_state 被设为 building ,而 taskstate 被设置为 block de vicemapping 。
- 在实例所需资源均准备完成后, nova/virt/libvirt/driver.PY 的 Lib virtDriver.spawn () 方法被调用, 此时实例 vm_state 被设为 building ,而 task_state被设置为 spawning 。 在 spawn 过程中,首先进行镜像加载,如果镜像较大,则此过程可能会花费较长时间,然后创建虚拟机的资源定义文件并通过 Libvirt 发起创建虚拟机的操作 。
- 虚拟机创建完成之后, spawn()将调用_wait_for_boot()方法以等待虚拟机的 power_state 状态变为 runni ng 才返回, 此时虚拟机的各个状态应该是, vm_state 为 active, power_state 为running, task_state 为 none 。
启动方式
从镜像启动实例(–image)
实例创建后虚拟机系统镜像位于计算节点本地文件系统中(可以是网络文件系统,如ceph) ,不涉及 Volume挂载操作
从 Volume 启动实例
从镜像启动实例并挂载非引导 Volume (–image –block-device)
直接从可引导 Volume 启动实例(–block-device)
Nova 允许从镜像创建一个可引导的 Volume ,并将实例从此 Volume 上启动,此时的虚拟机操作系统镜像位于外部块存储上,因此本地磁盘或文件系统的故障并不影响到虚拟机操作系统的正常使用
Evacuate是真正的原样复原,包括系统和用户数据。如相同的实例 ID 、镜像ID 、 Flavor 、 IP 、 Attached Volumes 等。
使用新的镜像重新创建具有相同 ID 的实例,其功能更像是相同的硬件重新安装另外的操作系统(如 windows 系统换成 Linux 系统)。