03 Awk
awk是一个报告生成器,它拥有强大的文本格式化的能力。你可以把”报告”理解为”报表”或者”表格”。awk是逐行处理的。
awk其实是一门编程语言,它支持条件判断、数组、循环等功能。所以,我们也可以把awk理解成一个脚本语言解释器。
awk [options] ‘Pattern{Action} ...’ file...
awk用于表示字符串的引号是双引号。
$1这种内置变量的外侧不能加入双引号,否则$1会被当做文本输出。
$0 表示显示整行 ,$NF表示当前行分割后的最后一列($0和$NF均为内置变量)注意,$NF 和 NF 要表达的意思是不一样的,对于awk来说,$NF表示最后一个字段,NF表示当前行被分隔符切开以后,一共有几个字段。
除了使用 -F 选项指定输入分隔符,还能够通过设置内部变量的方式,指定awk的输入分隔符,awk内置变量FS可以用于指定输入分隔符,但是在使用变量时,需要使用-v选项,用于指定对应的变量,比如 -v FS=’#’,
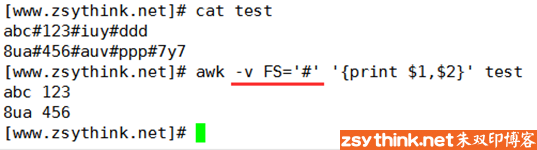
FS:输入字段分隔符, 默认为空白字符
OFS:输出字段分隔符, 默认为空白字符
RS:输入记录分隔符(输入换行符), 指定输入时的换行符
ORS:输出记录分隔符(输出换行符),输出时用指定符号代替换行符
NF:number of Field,当前行的字段的个数(即当前行被分割成了几列),字段数量
NR:行号,当前处理的文本行的行号。
FNR:各文件分别计数的行号
FILENAME:当前文件名
ARGC:命令行参数的个数
ARGV:数组,保存的是命令行所给定的各参数
1、在awk中,只有在引用$0、$1等内置变量的值的时候才会用到”$”,引用其他变量时,不管是内置变量,还是自定义变量,都不使用”$”,而是直接使用变量名。
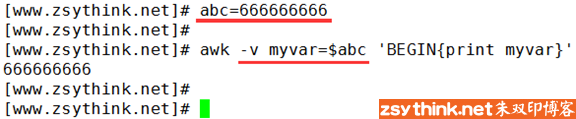
方法一:-v varname=value 变量名区分字符大小写。

方法二:在program中直接定义。但是注意,变量定义与动作之间需要用分号”;”隔开。

1)使用printf动作输出的文本不会换行,如果需要换行,可以在对应的”格式替换符”后加入”\n”进行转义。
2)使用printf动作时,”指定的格式” 与 “被格式化的文本” 之间,需要用”逗号”隔开。
3)使用printf动作时,”格式”中的”格式替换符”必须与 “被格式化的文本” 一一对应。
我们可以利用格式替换符对文本中的每一列进行格式化,示例如下。

我们可以利用awk的内置变量FS,指定输入字段分隔符,然后再利用printf动作,进行格式化,示例如下。

上例完美的体现了awk的格式化能力,因为awk本身负责文本切割,printf动作负责格式化文本,双剑合璧了。
继续扩展一下,可以利用awk的begin模式,结合printf动作,输出一个像样的表格,下图中用到的”修饰符”此处不再赘述,如果不明白,参考printf命令详解。

awk是逐行处理文本的,也就是说,awk会先处理完当前行,再处理下一行,如果我们不指定任何”条件”,awk会一行一行的处理文本中的每一行,如果我们指定了”条件”,只有满足”条件”的行才会被处理,不满足”条件”的行就不会被处理。
当awk进行逐行处理的时候,会把pattern(模式)作为条件,判断将要被处理的行是否满足条件,是否能跟”模式”进行匹配,如果匹配,则处理,如果不匹配,则不进行处理。
没有被指定任何”模式”的情况,也是一种”模式”,我们称这种情况为”空模式”,”空模式”会匹配文本中的每一行,所以,每一行都满足”条件”,所以,每一行都会执行相应的动作。
让两列合并在一起显示
awk ‘{print $1 $2}’ 表示每行分割后,将第一列(第一个字段)和第二列(第二个字段)连接在一起输出。
awk ‘{print $1,$2}’ 表示每行分割后,将第一列(第一个字段)和第二列(第二个字段)以输出分隔符隔开后显示。
AWK 包含两种特殊的模式:BEGIN 和 END。
BEGIN 模式指定了处理文本之前需要执行的操作:
END 模式指定了处理完所有行之后所需要执行的操作:
| 关系运算符 | 含义 | 用法示例 |
|---|---|---|
| < | 小于 | x < y |
| <= | 小于等于 | x <= y |
| == | 等于 | x == y |
| != | 不等于 | x != y |
| >= | 大于等于 | x >= y |
| > | 大于 | x > y |
| ~ | 与对应的正则匹配则为真 | x ~ /正则/ |
| !~ | 与对应的正则不匹配则为真 | x !~ /正则/ |
我们把这种用到了”关系运算符”的”模式”称之为:”关系表达式模式”或者”关系运算符模式”。
正则模式可以理解为,把”正则表达式”当做”条件”,能与正则匹配的行,就算满足条件,满足条件的行才会执行对应的动作,不能被正则匹配到的行,则不会执行对应的动作。在awk命令中,正则表达式被放入了两个斜线中,如果正则中包含”/”,则需要进行转义
1、当在awk命令中使用正则模式时,使用到的正则用法属于”扩展正则表达式”。
2、当使用 {x,y} 这种次数匹配的正则表达式时,需要配合–posix选项或者–re-interval选项。
从被正则1匹配到的行开始,到被正则2匹配到的行结束,之间的所有行都会执行对应的动作,所以,这种模式被称为行范围模式。但是需要注意的是,在行范围模式中,不管是正则1,还是正则2,都以第一次匹配到的行为准。

所有动作的最外侧必须用”{ }”括起。
在awk中,如果省略了模式对应的动作,当前行满足模式时,默认动作为打印整行,即{print $0}。
“{ }”其实也可以被称之为”动作”,只不过,”{ }”属于”组合语句”类型的动作,顾名思义,”组合语句”类型的动作的作用就是将多个代码组合成代码块。此外,”{ }”可以出现多次。
当我们把多个动作(多段代码)组合成一个代码块的时候,每段动作(每段代码)之间需要用分号”;”隔开
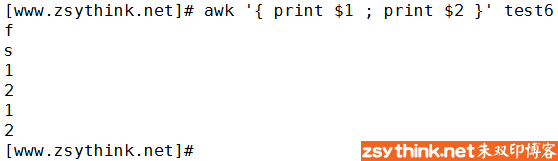
print语句
”if”对应的大括号中有多条语句,所以”if”语法中的大括号不能省略,但是,如果”if”对应的大括号中只有一条命令,那么”if”对应的大括号则可以省略。但是需要注意,如果条件成立之后,需要执行多条语句,那么”if”对应的大括号则不能省略。
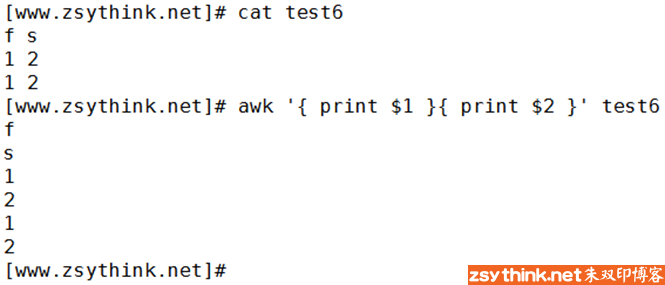
在awk中,0或者空字符串表示”假”,非0值或者非空字符串表示”真”

还可以使用 “!” 对条件进行取反
awk '{if (!(NR==1))print $0}' test6
if(条件)
{
语句1;
语句2;
...
}
if(条件)
{
语句1;
语句2;
...
}
else
{
语句1;
语句2;
...
}
if(条件1)
{
语句1;
语句2;
...
}
else if(条件2)
{
语句1;
语句2;
...
}
else
{
语句1;
语句2;
...
}


条件 ? 结果1 : 结果2

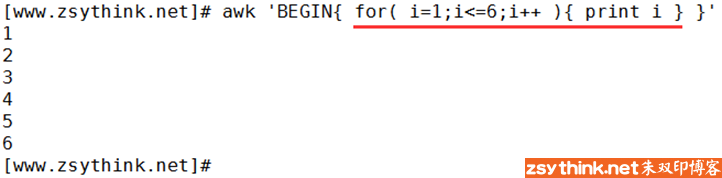
#for循环语法格式1
for(初始化; 布尔表达式; 更新) {
//代码语句
}
#for循环语法格式2
for(变量 in 数组) {
//代码语句
}
#while循环语法
while( 布尔表达式 ) {
//代码语句
}
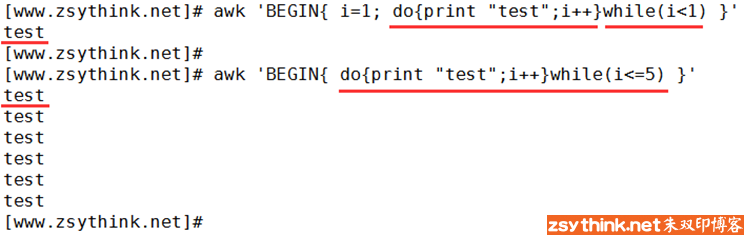
#do...while循环语法
do {
//代码语句
}while(条件)

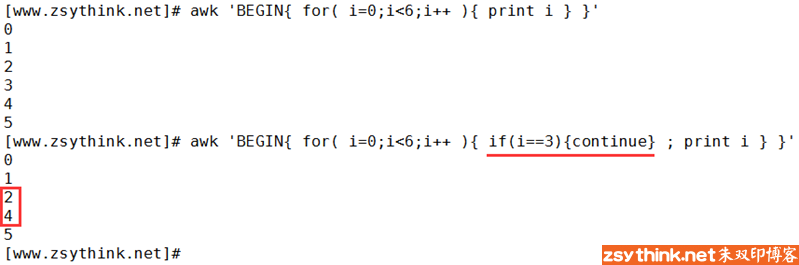
- continue的作用:跳出”当前”循环
- break的作用:跳出”整个”循环

exit:不再执行awk命令,相当于退出了当前的awk命令
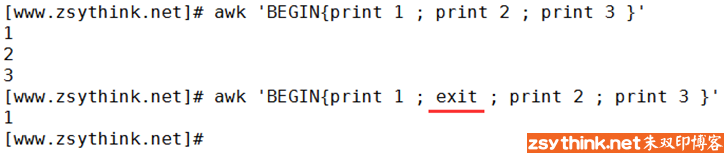
上图中第一条命令中,执行了多个动作(多条语句),上图中的第二条命令中,也执行了多个动作,但是当在awk中执行了exit语句以后,之后的所有动作都不会再被执行,相当于退出了整个awk命令。
其实,这样描述exit的作用并不准确,因为,当在awk中使用了END模式时,exit的作用并不是退出整个awk命令,而是直接执行END模式中的动作
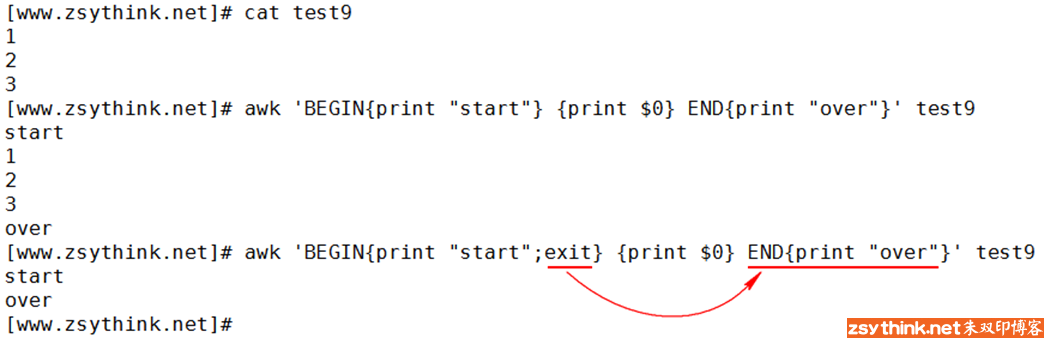
当执行了exit语句后,如果使用了END模式,将直接执行END模式中的动作,其他动作将不会被执行,如果没有使用END模式,当执行了exit语句后,将直接退出整个awk命令。
awk是逐行对文本进行处理的,也就是说,awk会处理完当前行,再继续处理下一行,那么,当awk需要处理某一行文本的时候,我们能不能够告诉awk :”不用处理这一行了,直接从下一行开始处理就行了”。
使用next命令即可让awk直接从下一行开始处理,换句话说就是,next命令可以促使awk不对当前行执行对应的动作,而是直接处理下一行(也是要匹配pattern的),示例如下。
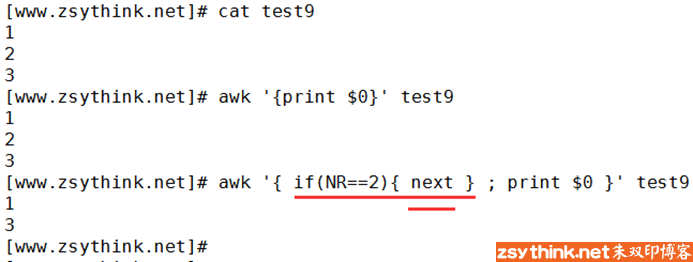
其实,next与continue有些类似,只是,continue是针对”循环”而言的,continue的作用是结束”本次循环”,而next是针对”逐行处理”而言的,next的作用是结束”对当前行的处理”,从而直接处理”下一行”,其实,awk的”逐行处理”也可以理解成为一种”循环”,因为awk一直在”循环”处理着”每一行”。
在awk中,数组元素的下标默认从1开始,但是为了兼容你的使用习惯,我们也可以从0开始设置下标。通过split函数生成的数组的下标默认是从1开始的。
在其他语言中,你可能会习惯性的先”声明”一个数组,在awk中,则不用这样,直接为数组中的元素赋值即可:

在awk中,元素的值可以设置为”空”,在awk中,将元素的值设置为”空字符串”是合法的。那么我们就不能再根据元素的值是否为”空”去判断元素是否存在了,所以,在awk中,如果你使用如下方法判断数组中的元素是否存在,是不合理的。此外当一个元素不存在于数组时,如果我们直接引用这个不存在的元素,awk会自动创建这个元素,并且默认为这个元素赋值为”空字符串”。
在awk中,数组的下标不仅可以为”数字”,还可以为”任意字符串”,如果你使用过shell中的数组,你可以把awk的数组比作bash中的”关联数组”,示例如下

其实,awk中的数组本来就是”关联数组”,之所以先用以数字作为下标的数组举例,是为了让读者能够更好的过度,不过,以数字作为数组下标的数组在某些场景中有一定的优势,但是它本质上也是关联数组,awk默认会把”数字”下标转换为”字符串”,所以,本质上它还是一个使用字符串作为下标的关联数组。
关联数组的元素是无序的。



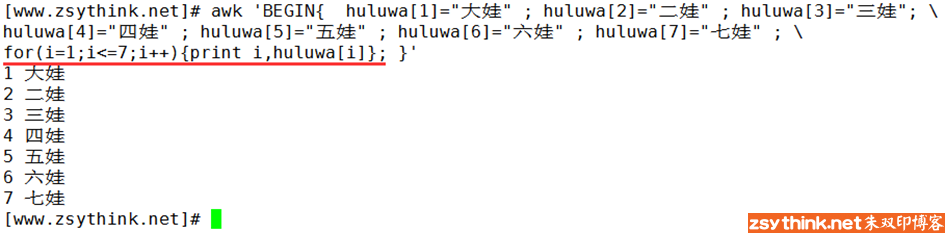

注意,在这种语法中,for循环中的变量”i”表示的是元素的下标,而并非表示元素的值,所以,如果想要输出元素的值,则需要使用”print 数组名[变量]”

awk中,如果字符串参与运算,字符串(包括空字符串)将被当做数字0进行运算。

利用上面这一点,我们就可以统计文本中某些字符出现的次数,比如IP地址,示例如下。
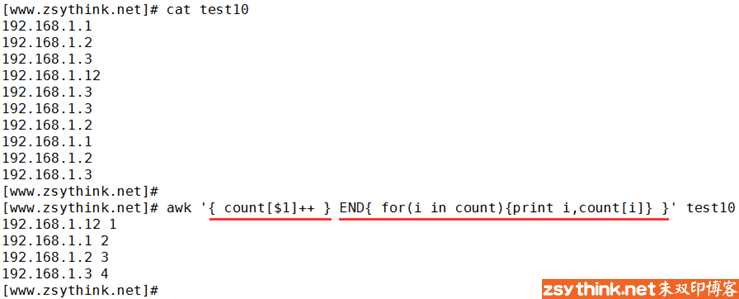
对一个不存在的元素进行自加运算后,这个元素的值就变成了自加运算的次数
如果你以后再想统计文本中某类文本出现的”次数”,就可以使用上述套路了,活学活用以后,你会发现上述套路特别好使。
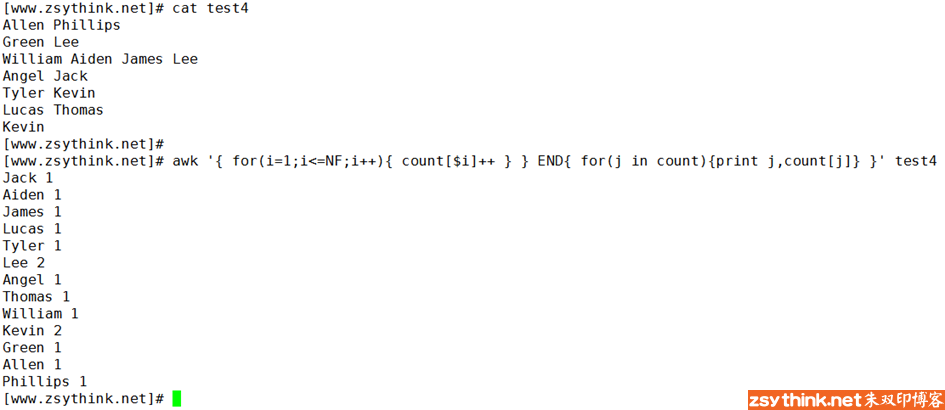
比如,如果我们想要统计如下文本中每个人名出现的次数,我们则可以使用如下命令。
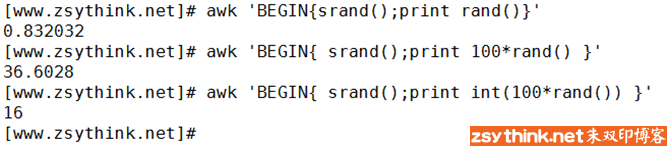
rand函数、srand函数:先运行srand,再运行rand,产生0-1的随机数
int函数:取整数
gsub函数(global替换的sub函数)
sub函数:只替换1次

- length函数,获取到指定字符串的长度

- index函数,获取到指定字符位于整个字符串中的位置

上图中,我们使用index函数,在每一行中咋找字符串”Lee”,如果Lee存在于当前行,则返回字符串Lee位于当前行的位置,如果Lee不存在于当前行,则返回0,表示当前行并不存在Lee,如上图所示,第二行中包含Lee,而且Lee位于第二行的第7个字符的位置,所以返回数字7。
- split函数,我们可以将指定的字符串按照指定的分割符切割,将切割后的每一段赋值到数组的元素中,从而动态的创建数组。split函数也有对应的返回值,其返回值就是分割以后的数组长度

使用split函数对ts字符串使用“:”进行切割,切割后的元素保存在数组huluwa中。被split函数分割后的数组的元素下标从1开始,不像其他语言中的数组下标是从0开始的,而且数组中元素输出的顺序可能与字符串中字符的顺序不同。

split函数生成了数组,并且将split的返回值保存在变量arrlen中,然后利用for循环中变量的递增,顺序的输出了数组中的对应下标以及元素值,
我们还能够通过asort函数根据元素的值进行排序,但是,经过asort函数排序过后的数组的下标将会被重置,示例如下

如上图所示,数组中元素的值均为数字,但是下标为自定义的字符串,通过asort函数对数组排序后,再次输出数组中的元素时,已经按照元素的值的大小进行了排序,但是,数组的下标也被重置为了纯数字,其实,asort还有一种用法,就是在对原数组元素值排序的同时,创建一个新的数组,将排序后的元素放置在新数组中,这样能够保持原数组不做任何改变,我们只要打印新数组中的元素值,即可输出排序后的元素值,示例如下。

其实,asort函数也有返回值,它的返回值就是数组的长度,换句话说,asort的返回值就是数组中元素的数量,示例如下。

理解完asort 函数,我们来认识一下asorti 函数,仔细看,是 asort 与 asorti
使用asort 函数可以根据元素的值进行排序,而使用asorti 函数可以根据元素的下标进行排序。
当元素的下标为字符串时,我们可以使用asorti 函数,根据下标的字母顺序进行排序,当元素的下标为数字时,我们就没有必要使用函数排序了,直接使用for循环即可排序,所以,此刻我们只考虑数组的下标为字符串时,怎样通过asorti 函数根据下标对数组进行排序。
当数组的下标为字符串时,asorti 函数会根据原数组中的下标的字母顺序进行排序,并且将排序后的下标放置到一个新的数组中,并且asorti函数会返回新的数组的长度,示例如下

如上图所示,asorti 函数根据数组t的下标排序后,创建了一个新的数组newt,newt中元素的值即为t数组下标的值,上例中,我们使用len变量保存了asorti函数的返回值,并且输出了最后排序后的新数组。
那么,聪明如你,一定想到了,既然我们已经将t数组的下标排序输出了,那么我们一定可以根据排序后的下标再次输出对应的元素值,从而达到根据数组下标排序后,输出原数组元素的目的,示例如下。

没错,上述过程,其实就是新数组负责排序老数组的下标,并将排序后的下标作为新数组的元素,而我们输出新数组元素的同时,又将新数组的元素值作为老数组下标,从而输出了老数组中的元素值,这句话好绕,不过我觉得你应该明白了。